我在互联网上使用的一些资源在集合关联缓存的工作方式上存在分歧.
例如硬件机密似乎相信它的工作原理如下:
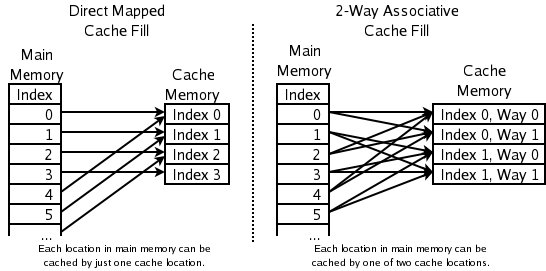
然后,主RAM存储器被划分为存储器高速缓存中可用的相同数量的块.保持512 KB 4路组关联示例,主RAM将被分成2,048个块,内存缓存中可用的块数相同.每个内存块都链接到缓存中的一组行,就像在直接映射缓存中一样.
http://www.hardwaresecrets.com/printpage/481/8
他们似乎在说每个缓存块(4个缓存行)映射到特定的连续RAM块.他们说不连续的系统内存块(RAM)无法映射到同一个缓存块.
这是有关hardwaresecrets认为它如何工作的图片 http://www.hardwaresecrets.com/fullimage.php?image=7864
与维基百科的关联缓存图片对比 http://upload.wikimedia.org/wikipedia/commons/9/93/Cache%2Cassociative-fill-both.png.
布朗不同意硬件机密
考虑如果每个高速缓存行具有两组字段可能发生的情况:两个有效位,两个脏位,两个标记字段和两个数据字段.一组字段可以缓存主存储器的一个区域的数据,另一组字段可以缓存到恰好映射到同一缓存线的另一个区域.
http://www.spsu.edu/cs/faculty/bbrown/web_lectures/cache/
也就是说,非连续的系统存储器块可以映射到相同的高速缓存块.
如何创建系统内存和缓存块上的非连续块之间的关系.我在某处读到这些关系是基于缓存步幅的,但除了它们存在之外,我找不到有关缓存步幅的任何信息.
谁是对的?如果实际使用了跨步,那么跨步工作如何?我是否拥有正确的技术名称?如何找到特定系统的步幅?它是基于寻呼系统?有人能指出一个能够详细解释N路组关联缓存的网址吗?
另见:http: //www.cs.umd.edu/class/sum2003/cmsc311/Notes/Memory/set.html
caching operating-system memory-management systems-programming
我有遗留代码,出于性能原因需要改进.我的应用程序包含两个需要交换某些信息的可执行文件.在遗留代码中,一个exe写入文件(文件名作为参数传递给exe),第二个可执行文件首先检查这样的文件是否存在; 如果不存在则再次检查并在找到它时,继续读取文件的内容.这种方式在两个可执行文件之间传递信息.代码的结构方式,第二个可执行文件在第一次尝试时就成功了.
现在我必须清理这个代码,并想知道使用文件作为通信手段而不是像管道这样的进程间通信有什么缺点.打开和读取比管道更昂贵的文件?还有其他缺点吗?您认为性能下降有多重要.
遗留代码在Windows和Linux上运行.
我读到使用vfork()系统调用创建的新进程作为父地址空间中的线程执行,直到子线程不调用exit()或exec()系统调用,父进程被阻塞.所以我用vfork()系统调用编写了一个程序
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
printf("Parent\n");
pid = vfork();
if(pid==0)
{
printf("Child\n");
}
return 0;
}
我得到的输出如下:
Parent
Child
Parent
Child
Parent
Child
....
....
....
我假设return语句必须在内部调用exit()系统调用,所以我只期望输出
Parent
Child
有人可以解释为什么实际上它不会停止并持续打印无限循环.
我正在读大卫汉森的书"C接口和实现".这个练习题似乎很有趣,无法找到解决方案:
在某些系统上,程序在检测到错误时可以自行调用调试器.当断言失败可能很常见时,此工具在开发期间特别有用.
您能否提供一个关于如何调用调试器的简短示例.
void handle_seg_fault(int arg)
{
/* how to invoke debugger from within here */
}
int main()
{
int *ptr = NULL;
signal(SIGSEGV, handle_seg_fault);
/* generate segmentation fault */
*ptr = 1;
}
在我的E8200机箱上,这不会发生,但是在我的Atom N450上网本(都运行OpenSuse 11.2)上,每当我读取CPU的TSC时,返回的值是mod 10 == 0,即没有被10整除的余数.我正在使用RDTSC用于测量有趣代码片段的时间的值,但为了演示的目的,我已经编写了这个小程序:
.text
.global _start
_start: xorl %ebx,%ebx
xorl %ecx,%ecx
xorl %r14d,%r14d
movb $10,%cl
loop: xchgq %rcx,%r15 # save to reg
cpuid
rdtsc
shlq $32,%rdx
xorq %rax,%rdx # full 64 bit of RDTSC
movq %r14,%r13 # save the old value
movq %rdx,%r14 # copy current
movq %r14,%rsi # argv[1] of printf()
subq %r13,%rdx # argv[2] (delta)
leaq format(%rip),%rdi # argv[0]
xorl %eax,%eax # no stack varargs
call printf
xchgq %rcx,%r15
loop loop
0: xorl …我试图从DTS文件中了解以下代码段.
/dts-v1/;
/ {
model = "MPC8313ERDB";
compatible = "MPC8313ERDB", "MPC831xRDB", "MPC83xxRDB";
#address-cells = <1>;
#size-cells = <1>;
aliases {
ethernet0 = &enet0;
serial0 = &serial0;
serial1 = &serial1;
pci0 = &pci0;
};
别名的作用是什么?
我的理解如下.
对于ethernet0,我们可以使用enet0.
但为什么serial0 =&serial0?
和serial1 =&serial1
有人可以请一下吗?
谢谢.
embedded operating-system embedded-linux systems-programming device-tree
在本学期的系统软件课程中,我们正在学习汇编程序和其他系统软件.在阅读整个课程时,我遇到了LITERALS的主题.
在文字和立即操作数之间进行了比较,他们说它们之间的唯一区别是文字不是作为指令的一部分组装的,而立即操作数则是.
如果我们可以使用立即操作数,为什么我们必须使用文字?是什么让他们与众不同?换句话说,何时使用文字以及何时使用立即操作数?
我正在尝试编写一个钩子,它将捕获暂停进程的Process Explorer的 " SomeFunction " .我已经有了一个挂钩SuspendThread和NtSuspendThread等函数的解决方案.但是Process Explorer使用了不同的东西,我不知道是什么.请问有人可以告诉我PE暂停进程所使用的函数的名称吗?
我只是想知道在不同的操作系统中有不同的功能,但它们的用途相同,或者可以说不同的操作系统有不同的系统编程语言(比如Windows和UNIX的操作系统).
因此,例如,由于C库包含函数的实现,它们的实现必须调用不同的函数(取决于OS),以实现相同的功能.它是否正确?那么,在cygwin中使用的库是用于编译专门为Windows编写的C程序,还是gcc编写的,特别是对于Linux?我对么?如果没有,为什么呢?
我正在编写一个C#应用程序,用于监视和记录连接到Windows系统的不同USB设备.使用Window的设置API,我可以获得诸如VID,PID,硬件ID和友好名称等详细信息.我想问的是,在Windows中有一种方法可以检查连接的设备是SmartPhone,打印机,大容量存储设备还是调制解调器?
注意:使用SetupGerDeviceRegistryProperty()我能够获取设备描述,但是对于所有设备,它显示设备描述是USB复合设备.
{kind=link}