标签: spark-ui
如何查看 AWS Glue Spark UI
在我的 Glue 作业中,我启用了 Spark UI 并指定了 Spark UI 工作所需的所有必要细节(s3 相关等)。
如何查看 Glue 作业的 DAG/Spark UI?
amazon-web-services directed-acyclic-graphs pyspark aws-glue spark-ui
推荐指数
解决办法
查看次数
在独立模式下运行时,SparkUI 不显示选项卡(作业、阶段、存储、环境...)
我通过以下命令运行 Spark Master:
./sbin/start-master.sh
之后我去了http://localhost:8080,我看到了以下页面。
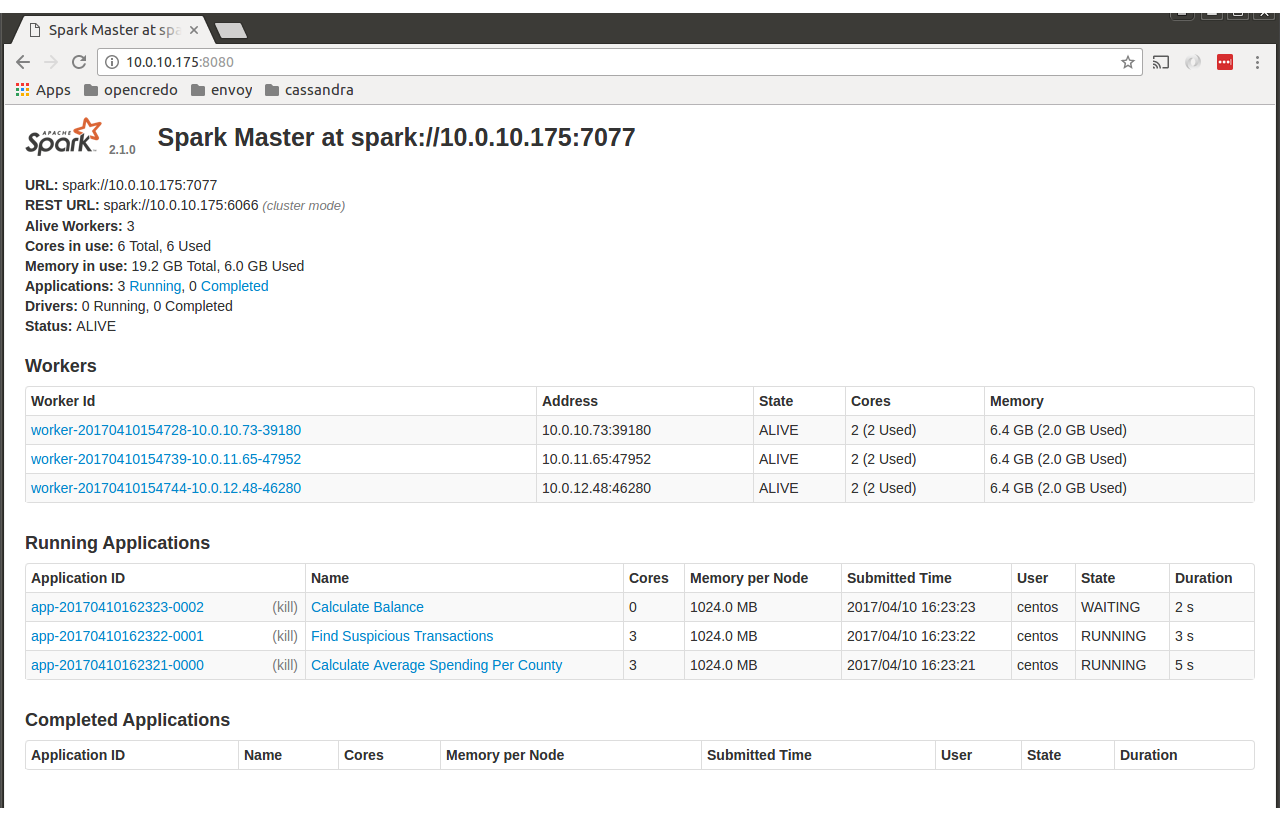
我期待看到包含“工作”、“环境”等的选项卡,如下所示
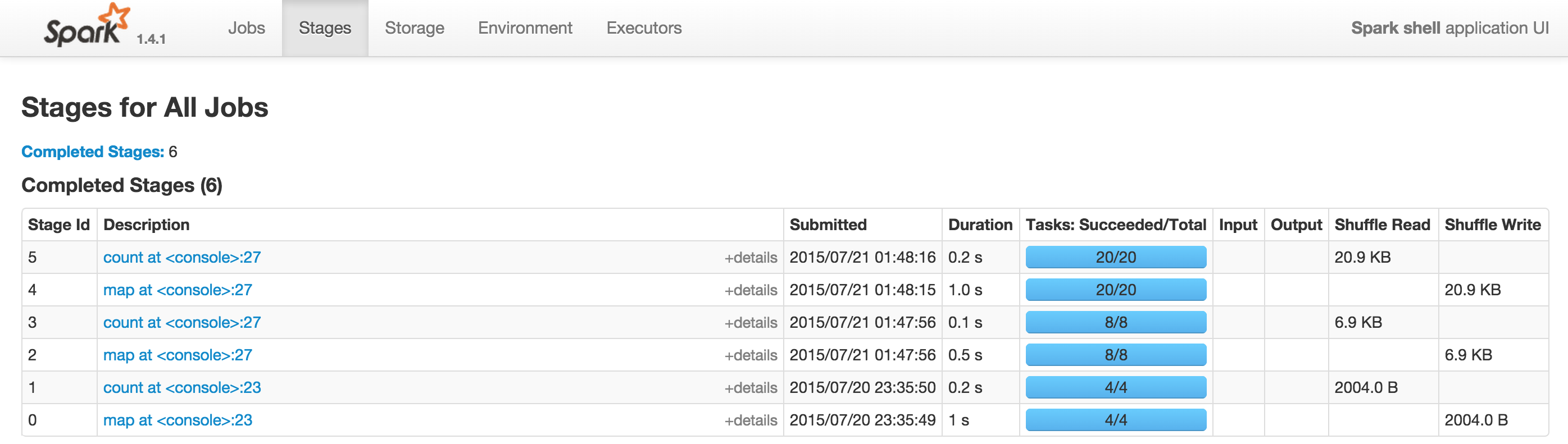
有人可以帮助我了解问题出在哪里吗?
我需要额外的配置吗?
谢谢
朱塞佩
推荐指数
解决办法
查看次数
Spark UI:如何理解 DAG 中的最小值/中值/最大值
我想完全理解有关 min/med/max 信息的含义。
例如:
scan time total(min, med, max)
34m(3.1s, 10.8s, 15.1s)
平均所有核心的扫描时间最短为 3.1 秒,最长为 15.1 秒,累计总时间长达 34 分钟,对吗?
然后对于
data size total (min, med, max)
8.2GB(41.5MB, 42.2MB, 43.6MB)
意味着所有核心的最大使用量是 43.6MB,最小使用量是 41.5MB,对吧?
所以同样的逻辑,对于左边的排序步骤,每个核心使用了 80MB 的 RAM。
现在,执行器有 4 个核心和 6G RAM,根据 metrix,我认为已经预留了很多 RAM,因为每个核心最多可以使用 1G 左右的 RAM。所以我想尝试减少分区数量并强制每个执行器处理更多数据并减少shuffle大小,您认为理论上可能吗?

推荐指数
解决办法
查看次数
Spark SQL:为什么我在 Spark UI 中看到 3 个作业而不是一个作业?
根据我的理解,actionSpark 中每个人都有一份工作。
但我经常看到单个操作触发了多个作业。我试图通过对数据集进行简单的聚合来测试这一点,以获得每个类别的最大值(这里是“主题”字段)
在检查 Spark UI 时,我可以看到为该groupBy操作执行了 3 个“作业” ,而我预期只有一个。
谁能帮我理解为什么有 3 而不是只有 1?
students.show(5)
+----------+--------------+----------+----+-------+-----+-----+
|student_id|exam_center_id| subject|year|quarter|score|grade|
+----------+--------------+----------+----+-------+-----+-----+
| 1| 1| Math|2005| 1| 41| D|
| 1| 1| Spanish|2005| 1| 51| C|
| 1| 1| German|2005| 1| 39| D|
| 1| 1| Physics|2005| 1| 35| D|
| 1| 1| Biology|2005| 1| 53| C|
| 1| 1|Philosophy|2005| 1| 73| B|
// Task : Find Highest Score in each subject
val highestScores = students.groupBy("subject").max("score")
highestScores.show(10)
+----------+----------+
| …推荐指数
解决办法
查看次数
Apache Spark:操作和作业之间的关系,Spark UI
据我所知,到目前为止,在 Spark 中,只要对数据集/数据帧调用操作,就会提交作业。工作可能进一步分为阶段和任务,我了解如何找出阶段和任务的数量。下面给出的是我的小代码
val spark = SparkSession.builder().master("local").getOrCreate()
val df = spark.read.json("/Users/vipulrajan/Downloads/demoStuff/data/rows/*.json").select("user_id", "os", "datetime", "response_time_ms")
df.show()
df.groupBy("user_id").count().show
据我所知,当我阅读时,它应该在第 4 行提交一份作业。一个在第一场演出,一个在第二场演出。前两个假设是正确的,但对于第二个展示,它提交了 5 个作业。我不明白为什么。下面是我的用户界面的屏幕截图

如您所见,作业 0 用于读取 json,作业 1 用于第一个节目,5 个作业用于第二个节目。谁能帮我理解 Spark UI 中的这项工作是什么?
推荐指数
解决办法
查看次数
什么是火花溢出(磁盘和内存)?
根据文档:
洗牌溢出(内存)是内存中洗牌数据的反序列化形式的大小。
Shuffle 溢出(磁盘)是磁盘上数据的序列化形式的大小。
我对shuffle的理解是这样的:
- 每个执行器都会获取其上的所有分区,并将它们哈希分区为 200 个新分区(这 200 个可以更改)。每个新分区都与一个稍后将转到的执行程序相关联。例如:
For each existing partition: new_partition = hash(partitioning_id)%200; target_executor = new_partition%num_executors其中%是模运算符,num_executors 是集群上执行程序的数量。 - 这些新分区被转储到其初始执行器的每个节点的磁盘上。每个新分区稍后都会被 target_executor 读取
- 目标执行器选取各自的新分区(在生成的 200 个分区中)
我对shuffle操作的理解是否正确?
您能帮我将 shuffle 溢出(内存)和 shuffle 溢出(磁盘)的定义放在 shuffle 机制的上下文中(如果正确的话,上面描述的)?例如(也许):“shuffle溢出(磁盘)是上面提到的第2点中发生的部分,其中200个分区被转储到各自节点的磁盘上”(我不知道这样说是否正确;只是举个例子)
apache-spark apache-spark-sql pyspark spark-ui spark-shuffle
推荐指数
解决办法
查看次数