标签: set-difference
R - 数据帧中2组之间的差异
我有2个因子列,我想创建第三列,它告诉我第二列是什么,第一列没有.它与这篇文章非常相似,但是我从df使用setdiff()函数到使用函数时遇到了麻烦.
例如:
library(dplyr)
y1 <- c("a.b.","a.","b.c.d.")
y2 <- c("a.b.c.","a.b.","b.c.d.")
df <- data.frame(y1,y2)
列y1有a.b.和列y2有a.b.c..我想要一个三分之一的列返回c.或只是c.
> df
y1 y2 col3
1 a.b. a.b.c. c.
2 a. a.b. b.
3 b.c.d. b.c.d.
我认为这是应该的组合strsplit和setdiff,但我不能得到它的工作.
我试图将其转换factor为character,然后我尝试应用于strsplit()结果,但输出对我来说似乎很奇怪.它似乎在列表中创建了一个列表,这使得很难传递给它setdiff()
#convert factor to character
df <- df %>% mutate_if(is.factor, as.character)
lapply(df$y1,function(x)(strsplit(x,split = "[.]")))
> lapply(df$y1,function(x)(strsplit(x,split = "[.]")))
[[1]]
[[1]][[1]]
[1] …推荐指数
解决办法
查看次数
为什么设置差异功能不能将列表与文件中的数据进行比较?
这是我的文件和功能:
List1.txt =>猫狗虎熊
List2.txt =>猫狗虎
这些文件是在winodws xp上进行ANSI编码的.
(defun get-file (filename)
(with-open-file (stream filename)
(loop for line = (read-line stream nil)
while line collect line)))
(defparameter *file1* (get-file "list1.txt"))
(defparameter *file2* (get-file "list2.txt"))
(set-difference *file1* *file2*)
我认为输出只是"熊".然而,它返回("猫","狗","老虎","熊")作为差异.我假设它必须与我一起从文件中读取信息,但我被困在那里.感谢您的时间.
推荐指数
解决办法
查看次数
在 Spark Python 中对 RDD 执行集差
我有两个 spark RDD,A 有 301,500,000 行,B 有 1,500,000 行。B 中的那 150 万行也都出现在 A 中。我想要这两个 RDD 之间的设置差异,以便我返回包含 300,000,000 行的 A,而来自 B 的那 1,500,000 行不再存在于 A 中。
我不能使用 Spark 数据帧。
这是我现在使用的系统。这些 RDD 有主键。我在下面做的是创建一个(收集的)出现在 B 中的主键列表,然后遍历 A 的主键以找到那些没有出现在 B 主键列表中的主键。
a = sc.parallelize([[0,"foo",'a'],[1,'bar','b'],[2,'mix','c'],[3,'hem', 'd'],[4,'line','e']])
b = sc.parallelize([[1,'bar','b'],[2,'mix','c']])
b_primary_keys = b.map(lambda x: x[0]).collect() # since first col = primary key
def sep_a_and_b(row):
primary_key = row[0]
if(primary_key not in b_primary_keys):
return(row)
a_minus_b = a.map(lambda x: sep_a_and_b(x)).filter(lambda x: x != None)
现在,这适用于这个示例问题,因为 A 和 B 很小。但是,当我使用真实数据集 …
推荐指数
解决办法
查看次数
如何在一个字典中找到没有另一个字典中对应字符的键?
在Python中,如何在一个字典中找到没有另一个字典中对应字符的键?实际问题是,我有一本人员的字典,这些人员已经注册,并且他们每天都会参与一本字典,我正在努力寻找那些已经注册但没有参加的人,或者是在注册词典中,而不是在参与字典中.
在Python食谱中,我找到了交叉口注册和参与的良好代码,或两个词典的交集:
print "Intersection: ", filter(enrollments.has_key, participation.keys())
但我无法弄清楚如何将这种逻辑扩展到正面(?)的情况.我试过把一个不在参数前面.()但是我收到了一个错误.有没有办法将过滤器中的逻辑扩展到我的问题或完全接近它的另一种方法?
推荐指数
解决办法
查看次数
在Java中查找字符串数组差异
我创建了两个数组变量:s1和s2 s1包含{ram,raju,seetha} s2包含{ram}
我想将两个数组减去为集合,以获得以下结果:
raju seetha
我怎样才能做到这一点?
推荐指数
解决办法
查看次数
在set和map键之间找到set_difference
我想问一下是否可以提供一个示例,说明如何使用set_difference找到地图的集合和键之间的差异
我知道另一个问题std :: set_difference是否可以比较set和map Keys?但它指出另一个没有明确例子的问题.我需要一个不使用boost库的解决方案
#include <algorithm>
#include <set>
#include <iterator>
// ...
std::set<int> s1, s2;
// Fill in s1 and s2 with values
std::set<int> result;
std::set_difference(s1.begin(), s1.end(), s2.begin(), s2.end(),
std::inserter(result, result.end()));
推荐指数
解决办法
查看次数
rm()除特定对象外的所有内容
有人知道如何删除R中除一个对象外的所有内容吗?通常,要删除我编码的所有内容:
rm(list=ls())
所以我尝试过:
rm(c(list=ls()-my_object))
但它不起作用.
推荐指数
解决办法
查看次数
如何查找一个向量中不在另一个向量中的元素(不使用setdiff)
我有两个向量
x <- c(1,2,2,3,4)
y <- c(1,2,3)
而且我想获得x中不在y中的元素的另一个向量;因此在这种情况下(2,4)。
我已经尝试过使用setdiff()函数,但这没有考虑重复项(它只会返回4),因此我不确定该如何处理。
谢谢!
推荐指数
解决办法
查看次数
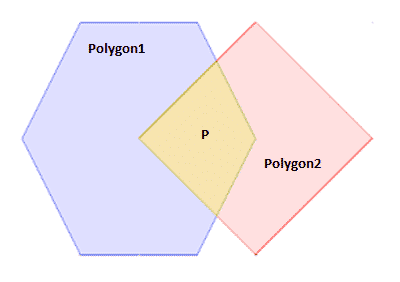
如何使用 Shapely 减去两个多边形
我不太确定如何解释这一点,但我有 2 个多边形,Polygon1 和 Polygon2。这些多边形相互重叠。如何在没有来自 Polygon1的P 的情况下使用 Shapely 获取Polygon2。
推荐指数
解决办法
查看次数
两个列表的差异C#
我有两个字符串列表,这两个字符串都是~300,000行.列表1比列表2有几行.我要做的是找到列表1中但不在列表2中的字符串.
考虑到我需要比较多少个字符串,是否Except()足够好还是有更好的(更快)?
推荐指数
解决办法
查看次数
标签 统计
set-difference ×10
python ×3
r ×3
set ×2
apache-spark ×1
arrays ×1
c# ×1
c++ ×1
common-lisp ×1
comparison ×1
dictionary ×1
format ×1
java ×1
lisp ×1
list ×1
map ×1
rdd ×1
rm ×1
shapely ×1
strsplit ×1