标签: quicksort
为什么quicksort比mergesort更好?
我在接受采访时被问到这个问题.他们都是O(nlogn),但大多数人使用Quicksort而不是Mergesort.这是为什么?
推荐指数
解决办法
查看次数
为什么极简主义,例如Haskell quicksort不是一个"真正的"快速排序?
Haskell的网站介绍了一个非常有吸引力的5行快速排序功能,如下所示.
quicksort [] = []
quicksort (p:xs) = (quicksort lesser) ++ [p] ++ (quicksort greater)
where
lesser = filter (< p) xs
greater = filter (>= p) xs
它们还包括"C中的真正快速排序".
// To sort array a[] of size n: qsort(a,0,n-1)
void qsort(int a[], int lo, int hi)
{
int h, l, p, t;
if (lo < hi) {
l = lo;
h = hi;
p = a[hi];
do {
while ((l < h) && (a[l] <= p))
l …推荐指数
解决办法
查看次数
Quicksort:选择枢轴
实现Quicksort时,您需要做的一件事就是选择一个数据透视表.但是当我看下面的伪代码时,我不知道应该如何选择枢轴.列表的第一个要素?别的什么?
function quicksort(array)
var list less, greater
if length(array) ? 1
return array
select and remove a pivot value pivot from array
for each x in array
if x ? pivot then append x to less
else append x to greater
return concatenate(quicksort(less), pivot, quicksort(greater))
有人可以帮助我掌握选择枢轴的概念,以及不同的场景是否需要不同的策略.
推荐指数
解决办法
查看次数
为什么Java的Arrays.sort方法对不同类型使用两种不同的排序算法?
Java 6的Arrays.sort方法使用Quicksort作为基元数组,并对对象数组进行合并排序.我相信大多数时候Quicksort比合并排序更快,并且内存更少.我的实验支持这一点,尽管两种算法都是O(n log(n)).那么为什么不同的算法用于不同的类型呢?
推荐指数
解决办法
查看次数
使用Python进行Quicksort
我是python的新手,我正在尝试实现quicksort.有人可以帮我完成我的代码吗?
我不知道如何连接三个数组并打印它们.
def sort(array=[12,4,5,6,7,3,1,15]):
less = []
equal = []
greater = []
if len(array) > 1:
pivot = array[0]
for x in array:
if x < pivot:
less.append(x)
if x == pivot:
equal.append(x)
if x > pivot:
greater.append(x)
sort(less)
sort(pivot)
sort(greater)
推荐指数
解决办法
查看次数
Quicksort vs heapsort
quicksort和heapsort都进行就地排序.哪个更好?什么是首选的应用程序和案例?
推荐指数
解决办法
查看次数
O(N log N)复杂性 - 与线性相似?
所以我想我会因为提出这样一个微不足道的问题而被埋葬,但我对某些事情感到有些困惑.
我已经在Java和C中实现了quicksort,我正在做一些基本的比较.该图表以两条直线形式出现,其中C比Java对应的快了4ms,超过100,000个随机整数.
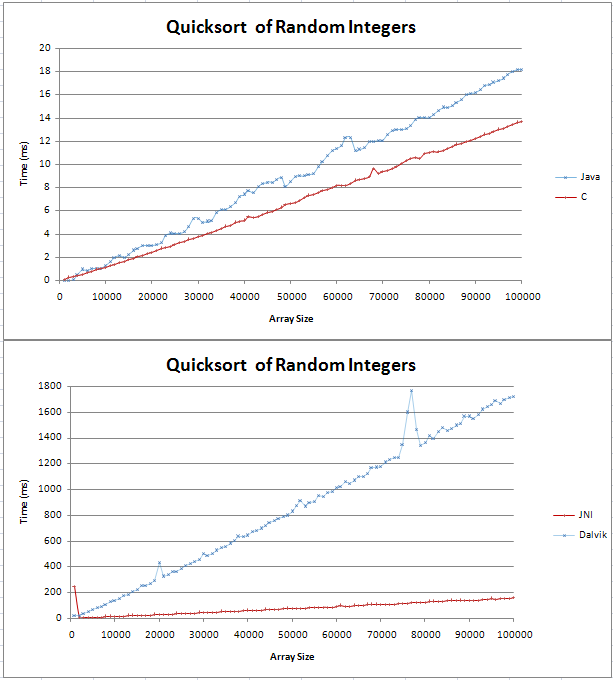
我的测试代码可以在这里找到;
我不确定(n log n)线是什么样的,但我不认为它是直的.我只是想检查这是否是预期的结果,我不应该尝试在我的代码中找到错误.
我将公式固定在excel中,对于10号基础,它似乎是一条直线,在开始时有一个扭结.这是因为log(n)和log(n + 1)之间的差异是线性增加的吗?
谢谢,
GAV
推荐指数
解决办法
查看次数
timsort和quicksort之间的比较
为什么当timsort(根据维基百科)表现得更好时,我大多听说quicksort是最快的整体排序算法?谷歌似乎没有发现任何比较.
推荐指数
解决办法
查看次数
为什么合并排序优先于快速排序以排序链接列表
我在论坛中阅读了以下内容:
合并排序对于链接列表等不可变数据结构非常有效
和
当数据存储在内存中时,快速排序通常比合并排序更快.但是,当数据集很大并且存储在外部设备(如硬盘驱动器)上时,合并排序在速度方面是明显的赢家.它最大限度地减少了外部驱动器的昂贵读取
和
在链表上操作时,合并排序只需要少量的辅助存储
有人能帮助我理解上述论点吗?为什么合并排序首选排序庞大的链表?它如何最大限度地减少对外部驱动器的昂贵读取?基本上我想了解为什么会选择合并排序来排序大链表.
推荐指数
解决办法
查看次数
双枢轴快速排序和快速排序有什么区别?
我以前从未见过双枢轴快速排序.如果是快速排序的升级版?
双枢轴快速排序和快速排序有什么区别?
推荐指数
解决办法
查看次数