标签: pseudocode
你经常在现实世界中使用伪代码吗?
回到大学时,我的课程中只使用伪代码而不是OOP.就像评论(以及其他传播的"最佳实践")一样,我发现在关键时刻,伪代码经常被忽略.所以我的问题是......谁在很多时候实际使用它?或者,当一个算法真的难以完全概念化时,你是否只使用它?我对每个人的回答很感兴趣:在初期的初级开发人员和那些在打卡时代回来的灰白色的兽医.
至于我个人而言,我大多只使用它来处理困难的事情.
推荐指数
解决办法
查看次数
计算依赖图的部分排序的算法
我正在尝试计算一个依赖图的部分"拓扑排序",它实际上是一个精确的DAG(有向无环图); 以便并行地执行没有冲突的依赖项的任务.
我想出了这个简单的算法,因为我在Google上发现的并不是那么有用(我一直只能找到并行运行的算法来计算正常的拓扑排序).
visit(node)
{
maxdist = 0;
foreach (e : in_edge(node))
{
maxdist = max(maxdist, 1 + visit(source(e)))
}
distance[node] = maxdist;
return distance[node];
}
make_partial_ordering(node)
{
set all node distances to +infinite;
num_levels = visit(node, 0);
return sort(nodes, by increasing distance) where distances < +infinite;
}
(请注意,这只是伪代码,肯定会有一些可能的小优化)
至于正确性,似乎很明显:对于叶子(:=没有进一步依赖的节点),叶子的最大距离总是0(正确,因为循环因0边缘而被跳过).对于连接到节点n1,...,nk的任何节点,最大叶对距离是1 + max {distance [n1],..,distance [nk]}.
在我写下算法之后我确实找到了这篇文章:http://msdn.microsoft.com/en-us/magazine/dd569760.aspx 但老实说,他们为什么要做所有那些列表复制等等,它只是看起来真的效率低......
无论如何,我想知道我的算法是否正确,如果是这样,它被称为什么,以便我可以阅读有关它的一些东西.
更新:我在我的程序中实现了算法,它似乎对我测试的所有内容都很有效.代码方式它看起来像这样:
typedef boost::graph_traits<my_graph> my_graph_traits;
typedef my_graph_traits::vertices_size_type vertices_size_type;
typedef my_graph_traits::vertex_descriptor vertex;
typedef my_graph_traits::edge_descriptor edge;
vertices_size_type find_partial_ordering(vertex v,
std::map<vertices_size_type, std::set<vertex> >& …推荐指数
解决办法
查看次数
特定类型图表中的最长路径
推荐指数
解决办法
查看次数
生成随机数的算法
我希望生成一个随机数并将其发布到数据库中的表中,以用于特定的user_id.问题是,相同的数字不能使用两次.有一百万种方法可以做到这一点,但我希望非常热衷于算法的人能够在一个优雅的解决方案中巧妙地解决问题,因为满足以下条件:
1)对数据库的查询量最少.2)在内存中进行数据结构爬行的次数最少.
基本上这个想法是做以下事情
1)创建0到9999999之间的随机数
2)检查数据库以查看数字是否存在
或者
2)查询数据库中的所有数字
3)查看返回的结果是否与数据库中的数据匹配
4)如果匹配,重复步骤1,如果没有,问题就解决了.
谢谢.
推荐指数
解决办法
查看次数
工作安排问题
我正在开发一个应用程序,我需要在轮换时间表上为成员自动安排作业.我不太擅长解释规则,所以这里有一些数据可以帮助解决:
职位:职称,每周一至周三等规则.
类别:一组职位
组:另一组职位.同一组中的职位不能在同一天
分配成员:分配到给定日期职位的用户.
对于该月中的每个日期,成员被分配到职位(均按升序排列).如果成员被分配到一个类别中的位置,则下一次出现相同类别中的位置时,按字母顺序(或列表的开头)分配下一个成员,例如.
成员:M1,M2,M3,M4
类别C1中的位置:P1,P2,P3
位置P1的成员:M1,M2,M3,M4
位置P2的成员:M1,M2,M3
位置P2的成员:M1,M3, M4
如果为P1分配了M1,如果接下来是P2,则将分配M2.引入了额外的复杂层,如果P3接下来,则M3被分配.系统必须跟踪M2被"跳过"的事实并在下一次分配M2(如果可用),然后分配M4,或者等到它到达M2可用的位置(当有许多'被跳过时,这变得更加复杂'成员).
如果一名成员表示他将无法在该日期上任,那么该成员也将被跳过.系统需要优先考虑跳过的成员,在它们出现时以某种方式识别它们,然后跳转到列表中的下一个逻辑人员.由于日期冲突,跳过也适用于群组.
我已经有了一个临时[和凌乱]的解决方案,我不再理解,即使我有很多评论解释每一步.它的弱点在于与被跳过的成员打交道.
如果你打算编码,你会怎么做呢?我在PHP中实现它,但伪代码也可以.
推荐指数
解决办法
查看次数
如何使用Edmonds-Karp算法获得剪辑?
我使用我在Edmonds-Karp算法wiki页面中找到的Pseudocode实现了Edmonds-Karp算法:http://en.wikipedia.org/wiki/Edmonds%E2%80%93Karp_algorithm
它工作得很好,但算法输出是最大流量值(最小切割值),我需要这个切割所包含的边缘列表
我试图改变算法,没有成功,你们可以帮忙吗?
谢谢
推荐指数
解决办法
查看次数
在javascript中实现一个方形树形图
我目前正在尝试在Javascript中实现树图算法.更具体地说,在Squarified Treemaps中描述的算法.给出的伪代码如下所示:
procedure squarify(list of real children, list of real row, real w)
begin
real c = head(children);
if worst(row, w) <= worst(row++[c], w) then
squarify(tail(children),row++[c], w)
else
layoutrow(row);
squarify(children,[], width());
fi
end
但我的JavaScript看起来像:
var c = children[0];
if (worst(row, w) >= worst(row.concat(c), w)) {
this.squarify(children.splice(1), row.concat(c), w);
} else {
layoutrow(row);
this.squarify(children, [], width());
}
据我所知,我的代码工作正常,但不平等是错误的方法.我假设我在实现中忽略了某些东西,或者伪代码中的不等式是不正确的?谢谢
推荐指数
解决办法
查看次数
求解字符串约简算法
我正准备接受我周一的采访,我发现这个问题要解决,称为" 减少字符串 ".问题是这样说的:
给定由a,b和c组成的字符串,我们可以执行以下操作:获取任意两个相邻的不同字符,并将其替换为第三个字符.例如,如果'a'和'c'相邻,则可以用'b'代替.重复应用此操作可以产生的最小字符串是多少?
例如,cab - > cc或cab - > bb,产生一个长度为2的字符串.对于这个,一个最佳解决方案是:bcab - > aab - > ac - > b.不能再应用任何操作,结果字符串的长度为1.如果字符串为= CCCCC,则不能执行任何操作,因此答案为5.
我在stackoverflow上看到了很多问题和答案,但我想验证我自己的算法.这是我的伪代码算法.在我的代码中
- S是我减少的字符串
- S [i]是索引i处的字符
- P是一个堆栈:
redux是减少字符的函数.
Run Code Online (Sandbox Code Playgroud)function reduction(S[1..n]){ P = create_empty_stack(); for i = 1 to n do car = S[i]; while (notEmpty(P)) do head = peek(p); if( head == car) break; else { popped = pop(P); car = redux (car, popped); } done push(car) done return size(P)}
我算法的最坏情况是O(n),因为堆栈P上的所有操作都在O(1)上.我在上面的例子中尝试了这个算法,我得到了预期的答案.让我用这个例子" abacbcaa " 执行我的算法:
i = 1 :
car …推荐指数
解决办法
查看次数
Twitter时间线算法如何工作?
我正在尝试设计一个类似于Twitter时间轴的系统,但我无法理解如何在保持高效的同时从众多粉丝那里获得更新.假设我在推特上关注了1000人.当我转到我的Feed时,它如何知道哪些推文给我看?这就是我的想法,但它似乎非常低效且不太可能:
You have 10,000 friends.
In a for loop, loop through each friend, getting their latest
status updates since their last update.
但是,通过10,000个朋友循环似乎是荒谬的.我无法想象他们会怎么做呢.或者它会是这样的:
Someone I am following posted a tweet. That tweet is inserted in
an array containing the tweets of all people I am following.
但后来这看起来很奇怪,如果我跟随一个有2万条推文的新人,那么我的阵列中会插入20,000条推文,如果那个人拥有数百万的粉丝,那么同一套推文就有一百万个X 20,000个拷贝.所以这似乎也不太可能.
任何人都有任何想法,他们怎么可能这样做?
推荐指数
解决办法
查看次数
Prime计数功能的可行实现
任何人都可以提供计算上可行的任何计数功能实现的伪代码吗?我最初尝试编写Hardy-Wright算法,但它的阶乘开始产生可怜的溢出,而其他许多似乎必然会产生类似的问题.我已经在谷歌搜索了实用的解决方案,但最好的是,我发现了非常深奥的数学,这是我在常规程序中从未见过的.
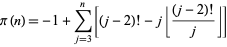{kind=link}
推荐指数
解决办法
查看次数
标签 统计
pseudocode ×10
algorithm ×7
java ×2
php ×2
dependencies ×1
edmonds-karp ×1
graph ×1
graph-theory ×1
javascript ×1
mysql ×1
performance ×1
primes ×1
random ×1
treemap ×1
twitter ×1