标签: poisson
推荐指数
解决办法
查看次数
随机泊松噪声
我在Mathematica中寻找相同的Matlab函数:
"R = poissrnd(lambda)从泊松分布中生成随机数,平均参数为lambda.lambda可以是向量,矩阵或多维数组.R的大小是lambda的大小."
下面的函数输出示例.
b = 95.7165 95.7165 95.7165 95.7165 95.7165 98.9772 98.9772 98.9772 98.9772 0.3876
poissrnd(b)
ans =100 115 81 90 109 106 104 87 104 2
我怎样才能在Mathematica 8中做类似的事情?
推荐指数
解决办法
查看次数
在Java中生成Poisson到达
我想在Java中创建一个函数,根据平均到达率(lambda)和平均服务率(mu)生成Poisson到达.
在我的例子中,我有:2,2个请求/天,换句话说2,2个到达/天,平均服务时间为108个小时.考虑到我的程序在t = 0分钟开始,我想创建一个返回到达[]的函数,它将包含t1,t2和一个可能的t3.T1,t2和t3是这些到达发生的白天的瞬间(以分钟为单位).我有以下限制:
t1 < t2 < t3 < 1440 minutes (24 hours*60 minutes/hour)
t2-t1 > 108 minutes
t3-t2 > 108 minutes
t3+ 108 minutes < 1440 minutes
有人可以帮帮我吗?
谢谢,
安娜
推荐指数
解决办法
查看次数
Python SciPy chisquare 测试从 Excel 和 LibreOffice 返回不同的 p 值
在阅读了最近关于泊松分布应用程序的博客文章后,我尝试使用 Python 的“scipy.stats”模块以及 Excel/LibreOffice 的“POISSON”和“CHITEST”函数重现其发现。
对于文章中显示的期望值,我简单地使用了:
import scipy.stats
for i in range(8):
print(scipy.stats.poisson.pmf(i, 2)*31)
这重现了博客文章中显示的表格 - 我还在 LibreOffice 中重新创建了它,使用第一列 A,在单元格 A1、A2、...、A8 中具有值 0 到 7,以及简单的公式 '=POISSON( A1, 2, 0)*31' 在 B 列的前 8 行中重复。
到目前为止一切顺利 - 现在是卡方 p 检验值:
在 LibreOffice 下,我只是在单元格 C1-C8 中记下观察到的值,并使用“=CHITEST(C1:C8, B1:B8)”来重现文章报告的 p 值 0.18。但是,在 scipy.stats 下,我似乎无法重现此值:
import numpy as np
import scipy.stats
obs = [4, 10, 7, 5, 4, 0, 0, 1]
exp = [scipy.stats.poisson.pmf(i, 2)*31 for i in range(8)]
# we …推荐指数
解决办法
查看次数
为什么我的泊松回归的可能性/ AIC是无限的?
我试图评估R中几个回归的模型拟合,我遇到了一个我现在多次遇到的问题:我的Poisson回归的对数似然是无限的.
我正在使用一个非整数因变量(注意:我知道我在这方面做了什么),我想知道是否可能是这个问题.但是,在运行回归时,我没有得到无限的对数似然glm.nb.
重现问题的代码如下.
编辑:当我将DV强制转换为整数时,问题似乎消失了.知道如何从非整数DV的Poissons获取对数似然?
# Input Data
so_data <- data.frame(dv = c(21.0552722691125, 24.3061351414885, 7.84658638053276,
25.0294679770848, 15.8064731063311, 10.8171744654056, 31.3008088413026,
2.26643928259238, 18.4261153345417, 5.62915828161753, 17.0691184593063,
1.11959635820499, 30.0154935602592, 23.0000809735738, 28.4389825676123,
27.7678405415711, 23.7108405071757, 23.5070651053276, 14.2534787168392,
15.2058525068363, 19.7449094187771, 2.52384709295823, 29.7081691356397,
32.4723790240354, 19.2147002673637, 61.7911384519901, 10.5687170234821,
23.9047421013736, 18.4889651451222, 13.0360878554798, 15.1752866581849,
11.5205948111817, 31.3539840929108, 31.7255952728076, 25.3034625215724,
5.00013988265465, 30.2037887018226, 1.86123112349445, 3.06932041603219,
22.6739418581257, 6.33738321053804, 24.2933951601142, 14.8634827414491,
31.8302947881089, 34.8361908525564, 1.29606416941288, 13.206844629927,
28.843579313401, 25.8024295609021, 14.4414831628722, 18.2109680632694,
14.7092063453463, 10.0738043919183, 28.4124482962025, 27.1004208775326,
1.31350378236957, 14.3009307888745, 1.32555197766214, 2.70896028922312,
3.88043749517381, 3.79492216916016, 19.4507965653633, 32.1689088941444,
2.61278585713499, 41.6955885902228, 2.13466761675063, 30.4207256294235, …推荐指数
解决办法
查看次数
为什么 scipy poisson 没有 pdf(概率密度函数)方法?
我想在使用 scipy 创建的 python 中绘制泊松分布的概率密度函数。如果我想绘制 beta 分布的 pdf,我会执行如下操作:
x = np.linspace(0, 1, 200)
alphas = 4
betas = 10
pdf = st.beta.pdf(x, alpha, beta)
plt.plot(x, pdf, label=r'$\alpha$ = {}, $\beta$ = {}'.format(alpha, beta))
我以为我可以用泊松分布做同样的事情,但不幸的是,该对象没有该pdf方法!为什么?如何在不自己编写公式的情况下绘制泊松pdf?
推荐指数
解决办法
查看次数
如何在R ggplot2中的geom_smooth(facet_wrap)中传递多个公式?
我想为每个因素拟合三个不同的函数(var.test)。我尝试了以下方法,但收到错误消息Warning messages: 1: Computation failed in stat_smooth() :invalid formula。还有其他方法可以同时读取多个公式吗?
set.seed(14)
df <- data.frame(
var.test = c("T","T","T","T","M","M","M","M","A","A","A","A"),
val.test = rnorm(12,4,5),
x = c(1:12)
)
my.formula <- c(y~x + I(x^2), y~x, y~x + I(x^2))
ggplot(df, aes(x = x, y = val.test)) + geom_point() +
geom_smooth(method="glm", formula = my.formula,
method.args = list(family = "poisson"), color = "black" ) + facet_grid(.~var.test)

推荐指数
解决办法
查看次数
如何用R模拟任意区域的空间泊松过程?
我正在研究R 3.0.1并进行了聚类泊松过程的模拟,R通常有一个默认区域,基本上是一个盒子,在下一张图片中你可以看到我的模拟:

到目前为止,一切都很好,我想要做的就是模拟相同distribution但使用地理区域的麻烦,但我不知道如何更改参数以便使用地理坐标来获得不同的区域.例如:

总而言之,基本上我想要做的是弄清楚如何为更大的区域改变这个区域,以便进行相同的模拟但是使用新区域.这是我试过的代码:
library(spatstat)
sim1 = rpoispp(100)
plot(sim1)
推荐指数
解决办法
查看次数
通过泊松过程c ++生成随机到达
有件事我不明白。我使用 cpp 参考中给出的示例来生成数字:
const int nrolls = 10; // number of experiments
std::default_random_engine generator;
std::poisson_distribution<int> distribution(4.1);
for (int i=0; i<nrolls; ++i){
int number = distribution(generator);
cout<<number<<" "<<endl;
}
(原始代码:http://www.cplusplus.com/reference/random/poisson_distribution/)
输出:2 3 1 4 3 4 4 3 2 3 等等...首先这些数字意味着什么?我的意思是我必须将它们相加才能创造时机吗?例如:2、(2+3)=5、(5+1)=6、(6+4)=10、……等等。
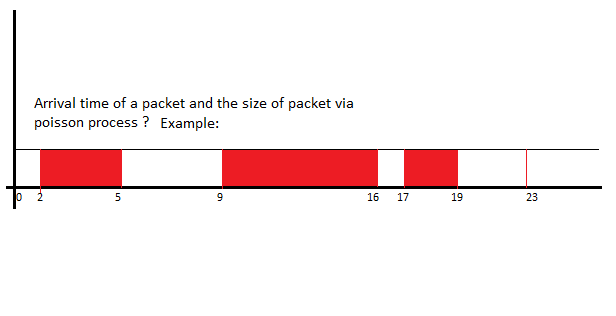
其次,我真正的问题是,我需要生成网络数据包的随机到达和数据包的大小。我的意思是,当数据包到来时,如果数据包到来,数据包的大小是多少?我怎样才能做到这一点?我需要这样的东西: http://i.hizliresim.com/dWmaGX.png
{kind=link}
推荐指数
解决办法
查看次数
如何创建以泊松作为理论分布的 QQ 图
我需要创建一个 QQ 图来检查我观察到的数据是否符合泊松分布。
这是我的数据框:
df = read.table(text = 'Var1 Freq
1975 10
1976 12
1977 9
1978 14
1979 14
1980 11
1981 8
1982 7
1983 10
1984 8
1985 12
1986 9
1987 10
1988 9
1989 10
1990 9
1991 11
1992 12
1993 9
1994 10', header = TRUE)
这df$Freq专栏是我感兴趣的专栏,因为观察结果代表了每年的事件数量。
我知道我必须使用该qqplot函数以及qpois创建理论分位数的函数,但是如何呢?
推荐指数
解决办法
查看次数
标签 统计
poisson ×10
r ×4
scipy ×2
c ×1
c++ ×1
distribution ×1
geospatial ×1
ggplot2 ×1
glm ×1
java ×1
plot ×1
python ×1
quantile ×1
random ×1
simulation ×1
spatial ×1
statistics ×1