标签: outliers
结果的行数不是 R 中向量长度 (arg 2) 的倍数
我有与此相关的新问题,我的主题 删除 r 中的异常值并考虑名义 var。在新情况下,变量 x 和 x1 具有不同的长度
x <- c(-10, 1:6, 50)
x1<- c(-20, 1:5, 60)
z<- c(1,2,3,4,5,6,7,8)
bx <- boxplot(x)
bx$out
bx1 <- boxplot(x1)
bx1$out
x<- x[!(x %in% bx$out)]
x1 <- x1[!(x1 %in% bx1$out)]
x_to_remove<-which(x %in% bx$out)
x <- x[!(x %in% bx$out)]
x1_to_remove<-which(x1 %in% bx1$out)
x1 <- x1[!(x1 %in% bx1$out)]
z<-z[-unique(c(x_to_remove,x1_to_remove))]
z
data.frame(cbind(x,x1,z))
然后我收到警告
Warning message:
In cbind(x, x1, z) :
number of rows of result is not a multiple of vector length (arg 2)
所以在新的数据框中 …
推荐指数
解决办法
查看次数
有没有可以去除异常值的功能?
我找到了一个函数来检测列中的异常值,但我不知道如何删除异常值
是否有从列中排除或删除异常值的函数
这是检测异常值的函数,但我需要帮助删除异常值的函数
import numpy as np
import pandas as pd
outliers=[]
def detect_outlier(data_1):
threshold=3
mean_1 = np.mean(data_1)
std_1 =np.std(data_1)
for y in data_1:
z_score= (y - mean_1)/std_1
if np.abs(z_score) > threshold:
outliers.append(y)
return outliers
这里是打印异常值
#printing the outlier
outlier_datapoints = detect_outlier(df['Pre_TOTAL_PURCHASE_ADJ'])
print(outlier_datapoints)
推荐指数
解决办法
查看次数
如何检测单变量异常值并在新列中标记为 TRUE 或 FALSE
我有一个包含 30 列和 >10,000 行的数据框。
我如何对一组变量运行异常值分析,如果任何变量超过特定阈值(对于该给定变量),则返回 TRUE,如果不满足任何异常值阈值 (3SD),则返回 FALSE变量,TRUE/FALSE 值显示在新列中?
我使用分位数来找到每个变量的 3 个标准偏差截止值:
IE:
quantile(df$a, 0.003, na.rm = T) #and
quantile(df$a, 0.997, na.rm = T)
假设第一个值是 2.5,这个变量的上限值是 10.5,然后我创建了一个新变量:
df$outliers <- (df$a <- df$a <2.5 | df$a > 10.5)
当 a 列中的值小于 2.5 或大于 10.5 时,它给出 TRUE 值。
我想做的是让 df$outliers 代表一组列的异常值状态,而不仅仅是一个列,即列 d、e、f、g、l、m 等,它们都有自己的阈值遇见。
做这个的最好方式是什么?
推荐指数
解决办法
查看次数
使用自定义评分器功能在 GridSearchCV 期间评估多个隔离森林估计器
我有一个没有目标值的值样本。实际上,X 特征(预测变量)全部用于拟合隔离森林估计器。目标是确定哪些 X 特征以及未来出现的特征实际上是异常值。举例来说,假设我拟合一个数组 (340,3) => (n_samples, n_features)并且我预测这些特征来识别 340 个观察值中哪些是异常值。
到目前为止我的方法是:
首先我创建一个管道对象
from sklearn.pipeline import Pipeline
from sklearn.ensemble import IsolationForest
from sklearn.model_selection import GridSearchCV
steps=[('IsolationForest', IsolationForest(n_jobs=-1, random_state=123))]
pipeline=Pipeline(steps)
然后我创建一个用于超参数调整的参数网格
parameteres_grid={'IsolationForest__n_estimators':[25,50,75],
'IsolationForest__max_samples':[0.25,0.5,0.75,1.0],
'IsolationForest__contamination':[0.01,0.05],
'IsolationForest__bootstrap':[True, False]
}
最后,我应用GridSearchCV算法
isolation_forest_grid=GridSearchCV(pipeline, parameteres_grid, scoring=scorer_f, cv=3, verbose=2)
isolation_forest_grid.fit(scaled_x_features.values)
我的目标是确定最适合的评分函数(记为Scorer_f ),它将有效地选择最合适的隔离森林估计器来进行异常值检测。
到目前为止,基于这个出色的答案,我的评分如下:
记分功能
isolation_forest_grid=GridSearchCV(pipeline, parameteres_grid, scoring=scorer_f, cv=3, verbose=2)
isolation_forest_grid.fit(scaled_x_features.values)
简单解释一下,我不断地将批次中 5%(0.05 分位数)的观察值识别为异常值。因此,每个低于阈值的分数都被表示为异常值。因此,我指示 GridSearch 函数选择异常值最多的模型作为最坏情况。
让您尝尝结果:
isolation_forest_grid.cv_results_['mean_test_score']
array([4. , 4. , 4. , …python machine-learning outliers scikit-learn isolation-forest
推荐指数
解决办法
查看次数
outline = FALSE用什么方法来确定异常值?
在R中,我使用outline = FALSE参数在绘制特定集合的框和晶须时排除异常值.它的工作非常出色,但让我想知道它究竟是如何确定哪些元素是异常值的.
boxplot(x, horizontal = TRUE, axes = FALSE, outline = FALSE)
推荐指数
解决办法
查看次数
识别和删除PCA和QQ图中的异常值
我有一个132 x 107的数据集,包括2个患者类型 - (患者1的33)和(患者2的99).
我正在寻找异常值,所以我在数据集上运行了pca,并使用以下命令完成了前4个组件的qqplots
pca = prcomp(data, scale. = TRUE)
plot(pca$x, pch = 20, col = c(rep("red", 33), rep("blue", 99)))
当我使用以下内容执行第二个组件的qqplot时:
qqPlot(pca$x[,2],pch = 20, col = c(rep("red", 33), rep("blue", 99)))
下图显示了2个明确的异常值 - 左下角的红点是患者1.
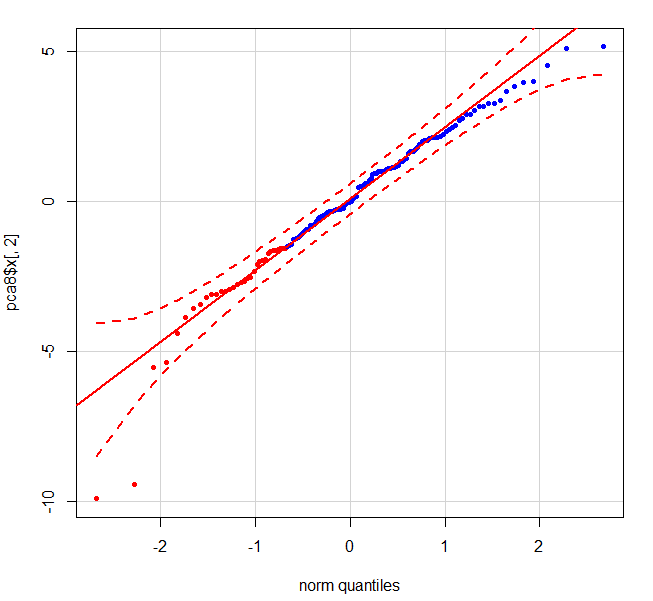
有没有直接的方法来计算数据中这些点的索引,以便可以删除它们?
推荐指数
解决办法
查看次数
在R箱图中如何精确去除异常值,以及如何去除相同的异常值以进行进一步计算(例如均值)?
在A中,boxplot我设置了outline=FALSE删除异常值的选项。
现在,我想在方框图中包括points显示均值的位置。显然,使用计算得出的均值mean包括离群值。
如何从数据框中删除完全相同的离群值,以使计算出的均值对应于箱图中所示的数据?
我知道如何删除异常值,但是该outline选项从boxplot内部使用了哪些设置?不幸的是,该手册未作任何说明。
推荐指数
解决办法
查看次数
R:'spatialSign'功能是否有助于识别异常值?
这是我的问题:
"AppliedPredictiveModeling"包中"spatialSign"功能的用途是什么?我在一本关于"空间符号"方法的书中读到了识别异常值的方法.该函数将变量的值投影到圆圈中,如果有异常值,则它们应该出现在圆圈内.R是否与此包中使用的"空间符号"相同?
如果是这样,我提交此代码的时候怎么样:
plotSubset <- data.frame(scale(zquant1[, c("AGE", "FL")]))
xyplot(AGE ~ FL,
data = plotSubset,
auto.key = list(columns = 10))
transformed <- spatialSign(plotSubset)
transformed <- as.data.frame(transformed)
xyplot(AGE ~ FL,
data = transformed,
auto.key = list(columns = 2))
可能看起来我在第一张图片中有一个异常值,但空间符号方法(第二张图像)不能识别它?
(第1张图片)http://www.imagesup.net/?di=5142245473711 (第2张图片)http://www.imagesup.net/?di=5142245489110
推荐指数
解决办法
查看次数
从按变量分组的数据框中搜索和删除异常值
我有一个有5个变量和800行的数据框:
head(df)
V1 variable value element OtolithNum
1 24.9835 V7 130230.0 Mg 25
2 24.9835 V8 145844.0 Mg 25
3 24.9835 V9 126126.0 Mg 25
4 24.9835 V10 103152.0 Mg 25
5 24.9835 V11 129571.9 Mg 25
6 24.9835 V12 114214.0 Mg 25
我需要执行以下操作:
- 识别与中位数> 2标准差的所有值(来自"值"变量),按元素变量分组.
- 从数据框中删除异常值(或创建一个排除异常值的新数据框.
我一直在使用dplyr包并使用以下代码按"element"变量进行分组,并提供平均值:
df1=df %>%
group_by(element) %>%
summarise_each(funs(mean), value)
你可以帮我操作或添加上面的代码,以便在我提取平均值之前删除由"element"变量分组的异常值(上面定义为> 2 sd,从中间开始).
我从另一个帖子中尝试了以下代码(这就是为什么数据名称与我上面的个人数据不匹配),没有运气:
#standardize each column (we use it in the outdet function)
scale(dat)
#create function that looks for values > +/- 2 …推荐指数
解决办法
查看次数
关于R中的异常值检测的grubbs测试
我按照如何重复Grubbs测试和标记异常值的网站上的程序代码,并在我的数据向量中测试异常值.我的数据向量包含更多44000个项目.
输出如下:
grubbs.result = grubbs.test(test_data)
pvalue = grubbs.result$p.value
grubbs.result
Grubbs test for one outlier
data: test_data
G = 3.79551464153584561, U = 0.99967764032789053, p-value = 1
alternative hypothesis: highest value -48.70000076 is an outlier
pvalue
[1] 1
grubbs.result$alternative
[1] "highest value -48.70000076 is an outlier"
我的问题是为什么pvalue是1,但程序检测到的值-48.70000076是异常值??? 是否-48.70000076通过grubbs测试检测到异常值?如果是,如何解释pvalue是1,不是像0.01这样的小值?
因为我是这个领域的新学习者,任何人都可以给我任何帮助吗?非常感谢你提前.
推荐指数
解决办法
查看次数