我正在寻找一个实现蚁群优化的.NET类库或.NET-Framework.你能给我一些关于这个主题的链接,资源等吗?
.net algorithm mathematical-optimization montecarlo ant-colony
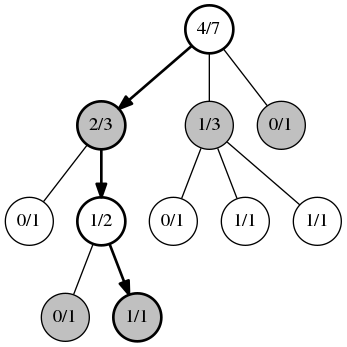
考虑一系列n个正实数,(a i)及其部分和序列(s i).给定一个号码X ε(0, s ^ Ñ ],我们必须找到我使得š 我 -1 < X ≤ 小号我.此外,我们希望能够改变的一个一个我的,而不必更新所有的部分款项.两者都可以在O(日志做ñ)时使用二叉树的一个我作为叶节点值,并且非叶节点的值是各个子节点的值的总和.如果n已知并且已修复,则树不必是自平衡的,并且可以有效地存储在线性阵列中.此外,如果n是2的幂,则只需要2 n -1个数组元素.参见Blue等,Phys.Rev. E 51(1995),pp.R867-R868申请.鉴于问题的通用性和解决方案的简单性,我想知道这个数据结构是否具有特定的名称以及是否存在现有的实现(最好是在C++中).我自己已经实现了它,但是从头开始编写数据结构似乎总是让我重新发明轮子 - 如果以前没有人做过,我会感到惊讶.
我知道时间是随机数生成的不安全种子,因为它有效地减小了种子空间的大小.
但是说我不关心安全问题.例如,假设我正在为纸牌游戏进行蒙特卡罗模拟.但是,我要关心尽可能接近真正的随机性.作为种子的时间会影响我的输出的随机性吗?在这种情况下,我认为PRNG的选择比种子更重要.
我正在编写一个试图复制本文开头讨论的算法的程序,
http://www-stat.stanford.edu/~cgates/PERSI/papers/MCMCRev.pdf
F是从char到char的函数.假设P1(f)是该函数的"合理性"度量.算法是:
从对函数的初步猜测开始,比如f,然后是新的函数f* -
我正在使用以下代码实现此功能.我正在使用c#,但试图让每个人都更加简化.如果有更好的论坛,请告诉我.
var current_f = Initial(); // current accepted function f
var current_Pl_f = InitialPl(); // current plausibility of accepted function f
for (int i = 0; i < 10000; i++)
{
var candidate_f = Transpose(current_f); // create a candidate function
var candidate_Pl_f = ComputePl(candidate_f); // compute its plausibility
if (candidate_Pl_f > current_Pl_f) // candidate Pl has improved
{
current_f = candidate_f; // accept the candidate
current_Pl_f = …c# algorithm functional-programming markov-chains montecarlo
我想用montecarlo类型模拟来总结任意数量的概率分布.我想随机抽样某些东西的连续分布,并将它们添加到其他连续分布的其他随机样本中,最终得到它们组合的概率分布.分布本身是经验的 - 它们不是函数,而是以P99 = 2.4,P90 = 7.12,P50 = 24.53,P10 = 82.14等形式(实际上存在一堆这些点).分布或多或少是对数正态的,因此将它们近似为对数正态可能会很好,如果这是必要的话.但是我怎么能进入SciPy的lognorm函数呢?或者在SciPy中使用其他方式,或者通常使用python?
我希望我很清楚我想要做什么.非常感谢,Alex
对于程序,我需要一种算法来快速计算实体的体积.该形状由一个函数指定,给定点P(x,y,z),如果P是实体的点,则返回1,如果P不是实体的点,则返回0.
我尝试使用numpy使用以下测试:
import numpy
from scipy.integrate import *
def integrand(x,y,z):
if x**2. + y**2. + z**2. <=1.:
return 1.
else:
return 0.
g=lambda x: -2.
f=lambda x: 2.
q=lambda x,y: -2.
r=lambda x,y: 2.
I=tplquad(integrand,-2.,2.,g,f,q,r)
print I
但它没有给我以下错误:
警告(来自警告模块):文件"C:\ Python27\lib\site-packages\scipy\integrate\quadpack.py",第321行warnings.warn(msg,IntegrationWarning)IntegrationWarning:最大细分数(50)已经实现了.如果增加限制没有产生任何改进,建议分析被积函数以确定困难.如果可以确定局部难度的位置(奇点,不连续),则可能从分割区间并在子范围上调用积分器获得.也许应该使用专用集成商.
警告(来自警告模块):文件"C:\ Python27\lib\site-packages\scipy\integrate\quadpack.py",第321行warnings.warn(msg,IntegrationWarning)IntegrationWarning:算法不收敛.在外推表中检测到舍入误差.假设无法实现所请求的容差,并且返回的结果(如果full_output = 1)是可以获得的最佳结果.
警告(来自警告模块):文件"C:\ Python27\lib\site-packages\scipy\integrate\quadpack.py",第321行warnings.warn(msg,IntegrationWarning)IntegrationWarning:检测到舍入错误的发生,其中防止达到要求的容差.错误可能被低估了.
警告(来自警告模块):文件"C:\ Python27\lib\site-packages\scipy\integrate\quadpack.py",第321行warnings.warn(msg,IntegrationWarning)IntegrationWarning:积分可能是发散的,或者是慢慢收敛的.
所以,很自然地,我寻找"专用集成商",但找不到任何可以做我需要的东西.
然后,我尝试使用蒙特卡罗方法编写自己的集成,并使用相同的形状对其进行测试:
import random
# Monte Carlo Method
def get_volume(f,(x0,x1),(y0,y1),(z0,z1),prec=0.001,init_sample=5000):
xr=(x0,x1)
yr=(y0,y1)
zr=(z0,z1)
vdomain=(x1-x0)*(y1-y0)*(z1-z0)
def rand((p0,p1)):
return p0+random.random()*(p1-p0)
vol=0.
points=0.
s=0. # sum part of variance of f
err=0.
percent=0
while err>prec …我是这里的新成员,我会直接进入这个,因为我整个星期天都试图绕过它.
我是Python的新手,以前在C++上学习了基础中级编码(这是一个为期10周的大学模块).
我正在尝试一些迭代技术来计算Pi,但两者都有些不准确,我不知道为什么.
我在大学教的第一种方法 - 我相信你们中的一些人之前已经看过它.
x=0.0
y=0.0
incircle = 0.0
outcircle = 0.0
pi = 0.0
i = 0
while (i<100000):
x = random.uniform(-1,1)
y = random.uniform(-1,1)
if (x*x+y*y<=1):
incircle=incircle+1
else:
outcircle=outcircle+1
i=i+1
pi = (incircle/outcircle)
print pi
它本质上是两个轴上-1到+1平面上随机(x,y)坐标的生成器.然后,如果x ^ 2 + y ^ 2 <= 1,我们知道该点位于由坐标轴形成的框内的半径为1的圆内.
根据点的位置,计数器增加incircle或outcircle.
然后,pi的值是圆圈内外的值的比率.坐标是随机生成的,所以它应该是均匀的.
但是,即使在非常高的迭代值下,我对Pi的结果总是在3.65左右.
第二种方法是另一次迭代,它计算多边形的周长,边数增加,直到多边形几乎是一个圆,然后,Pi =圆周/直径.(我有点被骗,因为编码有一个math.cos(Pi)术语,所以看起来我正在使用Pi来找到Pi,但这只是因为你不能轻易地使用度来表示Python上的角度).但即使是高迭代,最终结果似乎也在3.20左右结束,这也是错误的.代码在这里:
S = 0.0
C = 0.0
L = 1.0
n = 2.0
k = 3.0
while (n<2000):
S = 2.0**k
L = L/(2.0*math.cos((math.pi)/(4.0*n))) …我对 MCTS“树策略”的实施方式有些困惑。我读过的每一篇论文或文章都谈到了从当前游戏状态(在 MCTS 术语中:玩家即将采取行动的根)的树。我的问题是,即使我处于 MIN 玩家级别(假设我是 MAX 玩家),我如何选择最好的孩子。即使我选择了 MIN 可能采取的某些特定动作,并且我的搜索树通过该节点变得更深,MIN 玩家在轮到它时也可能会选择一些不同的节点。(如果 min 玩家是业余人类,它可能就像选择一些不一定是最好的节点)。由于 MIN 选择了一个不同的节点,这种类型使得 MAX 在通过该节点传播的整个工作都变得徒劳。对于我所指的步骤: https://jeffbradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/ 其中树政策:https : //jeffbradberry.com/images/mcts_selection.png 有点让我相信他们是从单人视角来执行它的。
这是我想用 R 做的算法:
ARIMA模型到arima.sim()函数模拟10个时间序列数据集2s,3s,4s,5s,6s,7s,8s,和9s。ARIMA通过auto.arima()函数从每个块大小的子系列中获得最佳模型。RMSE。下面的R函数完成了。
## Load packages and prepare multicore process
library(forecast)
library(future.apply)
plan(multisession)
library(parallel)
library(foreach)
library(doParallel)
n_cores <- detectCores()
cl <- makeCluster(n_cores)
registerDoParallel(cores = detectCores())
## simulate ARIMA(1,0, 0)
#n=10; phi <- 0.6; order <- c(1, 0, 0)
bootstrap1 <- function(n, phi){
ts <- arima.sim(n, model = …montecarlo ×10
algorithm ×4
python ×3
.net ×1
ant-colony ×1
arima ×1
binary-tree ×1
c# ×1
c++ ×1
numeric ×1
numpy ×1
pi ×1
prng ×1
python-2.7 ×1
r ×1
random ×1
scipy ×1
security ×1
simulation ×1
statistics ×1
{kind=link}