标签: microbenchmark
推荐指数
解决办法
查看次数
为什么(a*b!= 0)比Java中的(a!= 0 && b!= 0)更快?
我正在用Java编写一些代码,在某些时候,程序的流程是由两个int变量"a"和"b"是否为非零来确定的(注意:a和b从不是负数,并且从不在整数溢出范围内).
我可以评估它
if (a != 0 && b != 0) { /* Some code */ }
或者
if (a*b != 0) { /* Some code */ }
因为我希望每段代码运行数百万次,所以我想知道哪一段会更快.我通过在一个巨大的随机生成的数组上进行比较来做实验,我也很想知道数组的稀疏性(数据的分数= 0)会如何影响结果:
long time;
final int len = 50000000;
int arbitrary = 0;
int[][] nums = new int[2][len];
for (double fraction = 0 ; fraction <= 0.9 ; fraction += 0.0078125) {
for(int i = 0 ; i < 2 ; i++) {
for(int j = 0 ; j < len ; j++) …java performance processing-efficiency microbenchmark branch-prediction
推荐指数
解决办法
查看次数
如果声明vs if-else语句,哪个更快?
我前几天和朋友争论过这两个片段.哪个更快,为什么?
value = 5;
if (condition) {
value = 6;
}
和:
if (condition) {
value = 6;
} else {
value = 5;
}
如果value是矩阵怎么办?
注意:我知道value = condition ? 6 : 5;存在并且我希望它更快,但它不是一个选项.
编辑(工作人员要求,因为问题暂时搁置):
- 请通过考虑主流编译器(例如g ++,clang ++,vc,mingw)在优化和非优化版本或MIPS汇编中生成的x86汇编来回答.
- 当汇编不同时,解释为什么版本更快和何时(例如"更好,因为没有分支和分支跟随问题blahblah")
推荐指数
解决办法
查看次数
如何更简洁地找到缺失值?
下面的代码检查x和y是不同的值(变量x,y,z只能有值a,b或c),并且如果是这样,设置z于第三字符:
if x == 'a' and y == 'b' or x == 'b' and y == 'a':
z = 'c'
elif x == 'b' and y == 'c' or x == 'c' and y == 'b':
z = 'a'
elif x == 'a' and y == 'c' or x == 'c' and y == 'a':
z = 'b'
有可能以更简洁,可读和有效的方式做到这一点吗?
推荐指数
解决办法
查看次数
在Java中,可以比&&快吗?
在这段代码中:
if (value >= x && value <= y) {
什么时候value >= x和value <= y没有特定模式的情况一样真假,使用&运算符会比使用更快&&吗?
具体来说,我正在考虑如何&&懒惰地评估右侧表达式(即,仅当LHS为真),这意味着条件,而&在此上下文中的Java 保证严格评估两个(布尔)子表达式.值结果是相同的两种方式.
不过,虽然一个>=或<=运营商将使用一个简单的比较指令时,&&必须包括一个分支,该分支是易受分支预测失败 -按本非常著名的问题:为什么快处理有序数组不是一个排序的数组?
因此,强制表达式没有惰性组件肯定会更具确定性,并且不容易受到预测失败的影响.对?
笔记:
- 很明显,如果代码看起来如此,我的问题的答案就是否定:
if(value >= x && verySlowFunction()).我专注于"足够简单"的RHS表达. - 无论如何,那里有一个条件分支(
if声明).我无法向自己证明这是无关紧要的,而且替代配方可能是更好的例子,比如boolean b = value >= x && value <= y; - 这一切都落入了可怕的微观优化世界.是的,我知道:-) ......虽然很有趣?
更新 只是为了解释为什么我感兴趣:我一直在盯着马丁汤普森在他的机械同情博客上撰写的系统,在他来到并谈到 Aeron之后.其中一个关键信息是我们的硬件中包含了所有这些神奇的东西,我们的软件开发人员不幸地无法利用它.别担心,我不打算在我的所有代码上使用///// :-) ...但是这个网站上有很多关于通过删除分支来改进分支预测的问题,并且它发生了对我来说,条件布尔运算符是测试条件的核心.
当然,@ StephenC提出了一个奇妙的观点,即将代码弯曲成奇怪的形状可以使JIT更容易发现常见的优化 - 如果不是现在,那么将来也是如此.并且上面提到的非常着名的问题是特殊的,因为它推动预测复杂性远远超出实际优化. …
java performance processing-efficiency microbenchmark branch-prediction
推荐指数
解决办法
查看次数
Java 11 - 针对Java 8的性能回归?
更新:看到每个方法可能会遇到不同的性能问题,我决定将这个问题分成两个:
最初的讨论可以在下面找到......
当我遇到一些令人惊讶的数据时,我正在比较我的库在Java 8和11下的性能.这是基准代码:
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.infra.Blackhole;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class MyBenchmark
{
@Benchmark
public void emptyMethod()
{
}
@Benchmark
public void throwAndConsumeStacktrace(Blackhole bh)
{
try
{
throw new IllegalArgumentException("I love benchmarks");
}
catch (IllegalArgumentException e)
{
StringWriter sw = new StringWriter();
e.printStackTrace(new PrintWriter(sw));
bh.consume(sw.toString());
}
}
}
运行jmh 1.21,OracleJDK 1.8.0_192返回:
MyBenchmark.emptyMethod avgt 25 0.363 ± 0.001 ns/op
MyBenchmark.throwAndConsumeStacktrace avgt …推荐指数
解决办法
查看次数
Scala的隐藏性能成本?
我遇到了这个老问题,并使用scala 2.10.3进行了以下实验.
我重写了Scala版本以使用显式尾递归:
import scala.annotation.tailrec
object ScalaMain {
private val t = 20
private def run() {
var i = 10
while(!isEvenlyDivisible(2, i, t))
i += 2
println(i)
}
@tailrec private def isEvenlyDivisible(i: Int, a: Int, b: Int): Boolean = {
if (i > b) true
else (a % i == 0) && isEvenlyDivisible(i+1, a, b)
}
def main(args: Array[String]) {
val t1 = System.currentTimeMillis()
var i = 0
while (i < 20) {
run()
i += 1 …推荐指数
解决办法
查看次数
为什么StringBuilder链接模式sb.append(x).append(y)比常规sb.append(x)更快; sb.append(Y)?
我有一个微基准测试,显示非常奇怪的结果:
@BenchmarkMode(Mode.Throughput)
@Fork(1)
@State(Scope.Thread)
@Warmup(iterations = 10, time = 1, timeUnit = TimeUnit.SECONDS, batchSize = 1000)
@Measurement(iterations = 40, time = 1, timeUnit = TimeUnit.SECONDS, batchSize = 1000)
public class Chaining {
private String a1 = "111111111111111111111111";
private String a2 = "222222222222222222222222";
private String a3 = "333333333333333333333333";
@Benchmark
public String typicalChaining() {
return new StringBuilder().append(a1).append(a2).append(a3).toString();
}
@Benchmark
public String noChaining() {
StringBuilder sb = new StringBuilder();
sb.append(a1);
sb.append(a2);
sb.append(a3);
return sb.toString();
}
}
我期待两个测试的结果相同或至少非常接近.但是,差异几乎是5倍:
# Run complete. Total time: 00:01:41 …推荐指数
解决办法
查看次数
MATLAB的数字和长度函数之间的差异
我知道length(x)返回max(size(x))并numel(x)返回x的元素总数,但对于1乘n的数组哪个更好?它是否重要,或者在这种情况下它们是否可以互换?
编辑:只是为了踢:
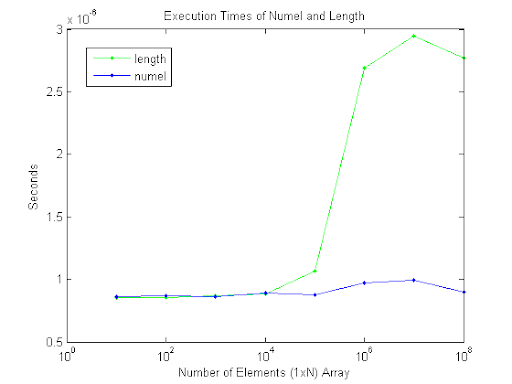
看起来它们在性能方面是相同的,直到你获得100k元素.
推荐指数
解决办法
查看次数
为什么总结一个值类型数组然后总结一个引用类型数组?
我想更好地了解内存如何在.NET中运行,所以我正在使用BenchmarkDotNet和诊断器.我通过对数组项进行求和来创建基准比较class和struct性能.我期望求和值类型总是更快.但对于短阵列则不然.有谁能解释一下?
代码:
internal class ReferenceType
{
public int Value;
}
internal struct ValueType
{
public int Value;
}
internal struct ExtendedValueType
{
public int Value;
private double _otherData; // this field is here just to make the object bigger
}
我有三个数组:
private ReferenceType[] _referenceTypeData;
private ValueType[] _valueTypeData;
private ExtendedValueType[] _extendedValueTypeData;
我使用相同的随机值初始化.
然后是一个基准测试方法:
[Benchmark]
public int ReferenceTypeSum()
{
var sum = 0;
for (var i = 0; i < Size; i++)
{
sum += _referenceTypeData[i].Value; …推荐指数
解决办法
查看次数
标签 统计
microbenchmark ×10
performance ×7
java ×5
benchmarking ×2
jmh ×2
jvm ×2
arrays ×1
assembly ×1
c# ×1
c++ ×1
c++11 ×1
java-11 ×1
java-8 ×1
jvm-hotspot ×1
matlab ×1
python ×1
scala ×1