标签: logistic-regression
R中glm逻辑回归模型的确定阈值
我有一些预测变量和二进制目标的数据.例如:
df <- data.frame(a=sort(sample(1:100,30)), b= sort(sample(1:100,30)),
target=c(rep(0,11),rep(1,4),rep(0,4),rep(1,11)))
我使用了一个logistic regresion模型 glm()
model1 <- glm(formula= target ~ a + b, data=df, family=binomial)
现在我正在尝试预测输出(例如,相同的数据应该足够)
predict(model1, newdata=df, type="response")
这生成概率数的向量.但我想预测实际的课程.我可以在概率数上使用round(),但这假设低于0.5的任何东西都是'0'类,而上面的任何东西都是'1'类.这是正确的假设吗?即使每个阶级的人口可能不相等(或接近相等)?或者有没有办法估算这个门槛?
推荐指数
解决办法
查看次数
模型以glm运行但不是bigglm
我试图对320,000行数据(6个变量)进行逻辑回归.对数据样本(10000)的逐步模型选择给出了具有5个交互项的相当复杂的模型:Y~X1+ X2*X3+ X2*X4+ X2*X5+ X3*X6+ X4*X5.该glm()函数可以使该行模型具有10000行数据,但不适用于整个数据集(320,000).
使用bigglm由块从SQL Server导致错误读取数据块,而我不能让从结果的意义traceback():
fit <- bigglm(Y~X1+ X2*X3+ X2*X4+ X2*X5+ X3*X6+ X4*X5,
data=sqlQuery(myconn,train_dat),family=binomial(link="logit"),
chunksize=1000, maxit=10)
Error in coef.bigqr(object$qr) :
NA/NaN/Inf in foreign function call (arg 3)
> traceback()
11: .Fortran("regcf", as.integer(p), as.integer(p * p/2), bigQR$D,
bigQR$rbar, bigQR$thetab, bigQR$tol, beta = numeric(p), nreq = as.integer(nvar),
ier = integer(1), DUP = FALSE)
10: coef.bigqr(object$qr)
9: coef(object$qr)
8: coef.biglm(iwlm)
7: coef(iwlm)
6: bigglm.function(formula = formula, data = datafun, ...)
5: bigglm(formula …推荐指数
解决办法
查看次数
如何在斯坦运行robit模型?
我想在Stan运行一个强大的逻辑回归(robit).该模型在Gelman&Hill的"使用回归和多级方法的数据分析"(2006,第124页)中提出,但我不确定如何实现它.我检查了Stan的Github存储库和参考手册,但不幸的是我仍然感到困惑.这是我用来模拟常规逻辑回归的一些代码.我应该添加什么,以便在7个自由度分布时出现错误?如果我运行多级分析,那么它是否会是相同的程序?
library(rstan)
set.seed(1)
x1 <- rnorm(100)
x2 <- rnorm(100)
z <- 1 + 2*x1 + 3*x2
pr <- 1/(1+exp(-z))
y <- rbinom(100,1,pr)
df <- list(N=100, y=y,x1=x1,x2=x2)
# Stan code
model1 <- '
data {
int<lower=0> N;
int<lower=0,upper=1> y[N];
vector[N] x1;
vector[N] x2;
}
parameters {
real beta_0;
real beta_1;
real beta_2;
}
model {
y ~ bernoulli_logit(beta_0 + beta_1 * x1 + beta_2 * x2);
}
'
# Run the model
fit <- stan(model_code = model1, …推荐指数
解决办法
查看次数
如何从MLE logit回归中获得系数?
我有一个statsmodels.discrete.discrete_model.BinaryResultsWrapper是running的输出statsmodels.api.Logit(...).fit()。我可以调用该.summary()方法来打印一个结果表,其中的系数嵌入文本中,但是我真正需要的是将这些系数存储到变量中以备后用。我怎样才能做到这一点?关于如何执行此非常基本的操作的文档还不清楚(可能是除了打印结果之外,任何人都想对结果做的最基本的事情)
当我尝试fittedvalues()方法(看起来它会返回系数)时,我得到了错误:
“系列”对象不可调用
推荐指数
解决办法
查看次数
Logistic回归+直方图与ggplot2
我有一些二进制数据,我想绘制逻辑回归线和同一图中0和1的相对频率的直方图.
我在这里使用popbio软件包遇到了一个非常好的实现:shizuka lab的页面
这里有一个与图书馆(popbio)一起运行的MWE(礼貌的shizuka实验室)
bodysize=rnorm(20,30,2) # generates 20 values, with mean of 30 & s.d.=2
bodysize=sort(bodysize) # sorts these values in ascending order.
survive=c(0,0,0,0,0,1,0,1,0,0,1,1,0,1,1,1,0,1,1,1) # assign 'survival' to these 20 individuals non-randomly... most mortality occurs at smaller body size
dat=as.data.frame(cbind(bodysize,survive))
#and now the plot
library(popbio)
logi.hist.plot(bodysize,survive,boxp=FALSE,type="hist",col="gray")
哪个产生

现在,是否可以使用ggplot2执行此操作?
推荐指数
解决办法
查看次数
ValueError:此解算器需要数据中至少2个类的样本,但数据只包含一个类:0.0
在将数据集拆分为测试和训练集后,我已在列车集上应用Logistic回归,但我得到了上述错误.我试图解决它,当我试图在控制台中打印我的响应向量y_train时,它会打印整数值,如0或1.但当我将其写入文件时,我发现值是浮点数,如0.0和1.0.如果那就是问题,我怎么能过来呢.
lenreg = LogisticRegression()
print y_train[0:10]
y_train.to_csv(path='ytard.csv')
lenreg.fit(X_train, y_train)
y_pred = lenreg.predict(X_test)
print metics.accuracy_score(y_test, y_pred)
StrackTrace如下,
Traceback (most recent call last):
File "/home/amey/prog/pd.py", line 82, in <module>
lenreg.fit(X_train, y_train)
File "/usr/lib/python2.7/dist-packages/sklearn/linear_model/logistic.py", line 1154, in fit
self.max_iter, self.tol, self.random_state)
File "/usr/lib/python2.7/dist-packages/sklearn/svm/base.py", line 885, in _fit_liblinear
" class: %r" % classes_[0])
ValueError: This solver needs samples of at least 2 classes in the data, but the data contains only one class: 0.0
与此同时,我遇到了无法回答的链接.有解决方案吗?
推荐指数
解决办法
查看次数
哪些系数去了scikit中多类逻辑回归中的哪一类?
我正在使用scikit learn的Logistic回归来解决多类问题.
logit = LogisticRegression(penalty='l1')
logit = logit.fit(X, y)
我对推动这一决定的特征感兴趣.
logit.coef_
上面给了我一个漂亮的数据帧(n_classes, n_features)格式,但所有的类和功能名称都消失了.有了功能,这没关系,因为假设它们的索引方式与我传递它们的方式相同似乎是安全的......
但是对于类,这是一个问题,因为我从未以任何顺序明确地传入类.那么哪个类做系数集(数据帧中的行)0,1,2和3属于哪个?
推荐指数
解决办法
查看次数
Logistic回归statsmodels的概率预测置信区间
我正在尝试从"统计学习简介"重新创建一个图,我无法弄清楚如何计算概率预测的置信区间.具体来说,我正在尝试重新创建该图的右侧面板(图7.1),该面板预测工资> 250的概率基于4度多项式的年龄和相关的95%置信区间.如果有人关心,工资数据就在这里.
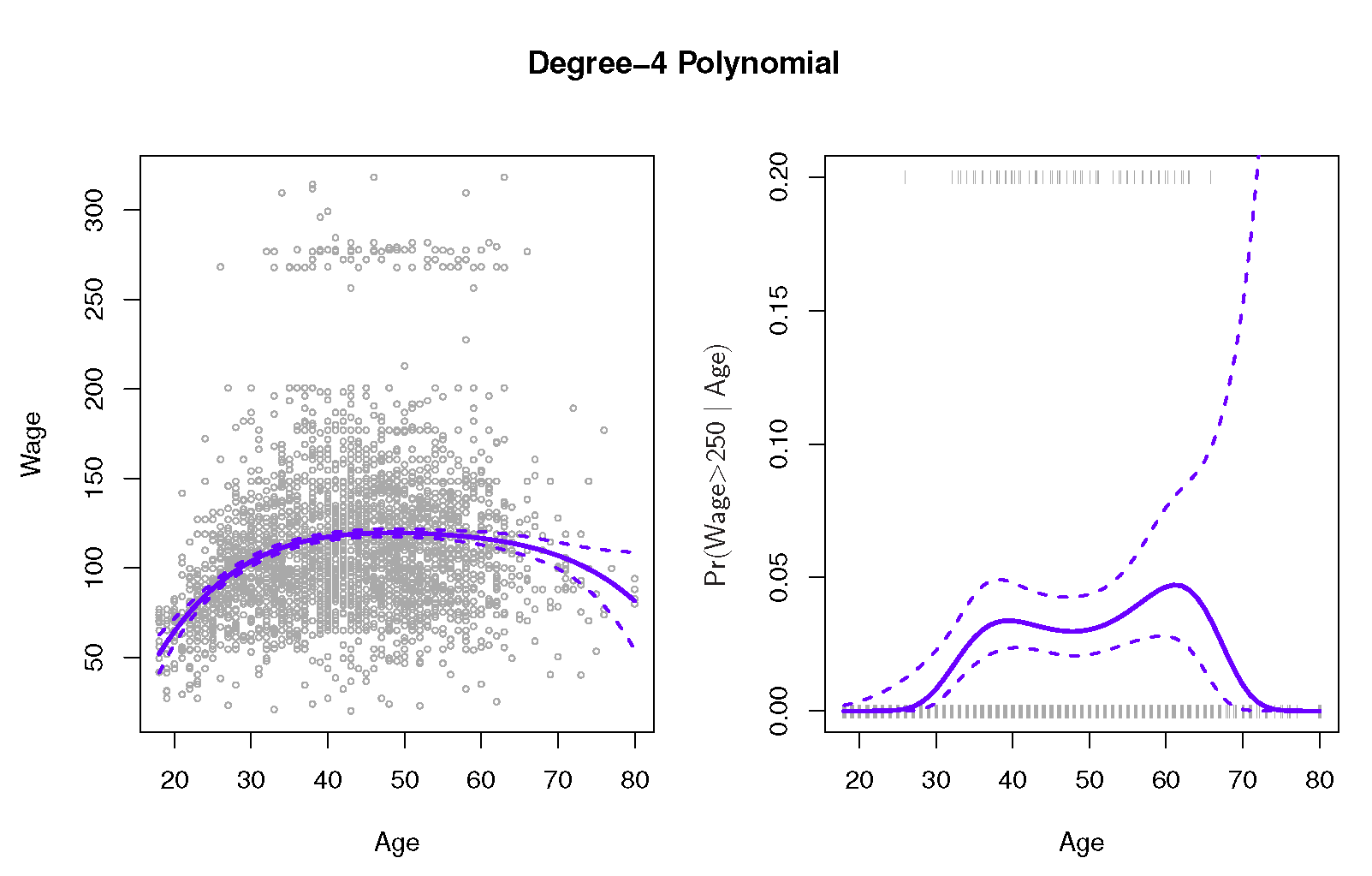{kind=link}
我可以使用以下代码预测并绘制预测概率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from sklearn.preprocessing import PolynomialFeatures
wage = pd.read_csv('../../data/Wage.csv', index_col=0)
wage['wage250'] = 0
wage.loc[wage['wage'] > 250, 'wage250'] = 1
poly = Polynomialfeatures(degree=4)
age = poly.fit_transform(wage['age'].values.reshape(-1, 1))
logit = sm.Logit(wage['wage250'], age).fit()
age_range_poly = poly.fit_transform(np.arange(18, 81).reshape(-1, 1))
y_proba = logit.predict(age_range_poly)
plt.plot(age_range_poly[:, 1], y_proba)
但我对如何计算预测概率的置信区间感到茫然.我已经考虑过多次引导数据以获得每个时代的概率分布,但我知道有一种更简单的方法,这是我无法掌握的.
我有估计的系数协方差矩阵和与每个估计系数相关的标准误差.如果给出这些信息,我将如何计算上图中右侧面板所示的置信区间?
谢谢!
推荐指数
解决办法
查看次数
Logistic回归模型中的内核LogisticRegression scikit-learn sklearn
如何使用sklearn库在逻辑回归模型中使用内核?
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
print(y_pred)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))
predicted= logreg.predict(predict)
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
kernel machine-learning svm scikit-learn logistic-regression
推荐指数
解决办法
查看次数
在 mclogit 中编码随机效应
我正在尝试使用条件逻辑模型分析离散选择实验,并使用 R 包中的 mclogit 函数对每个受试者产生随机效应mclogit。每个受试者 (ID) 评定 4 个选择集,其中包含 4 个备选方案。
我收到错误
属性(.Data) <- c(attributes(.Data), attrib) 中的错误:无法在符号上设置属性
当我将其编码为
out2 <- mclogit(fm2, random=~1|ID, data=ds.pork)
我希望得到正确编码的帮助。
library(support.CEs)
library(survival)
library(mclogit)
d.pork <- Lma.design(
attribute.names = list(
Price = c("100", "130", "160", "190")),
nalternatives = 3,
nblocks = 4,
row.renames = FALSE,
seed = 987)
data(pork)
dm.pork <- make.design.matrix(
choice.experiment.design = d.pork,
optout = TRUE,
continuous.attributes = c("Price"),
unlabeled = FALSE)
ds.pork <- make.dataset(
respondent.dataset = pork,
choice.indicators =
c("q1", "q2", "q3", …推荐指数
解决办法
查看次数
标签 统计
r ×5
python ×3
scikit-learn ×3
glm ×2
statsmodels ×2
ggplot2 ×1
histogram ×1
kernel ×1
mixed-models ×1
predict ×1
python-2.7 ×1
stan ×1
svm ×1