我有一个经典的线性回归问题的形式:
y = X b
其中y是响应向量 X是一个矩阵输入变量的和b是拟合参数我寻找的矢量.
Python提供b = numpy.linalg.lstsq( X , y )了解决此形式的问题.
但是,当我使用它时,我倾向于得到组件的极大或极小的值b.
我想执行相同的拟合,但约束b0到255之间的值.
它看起来像是scipy.optimize.fmin_slsqp()一个选项,但我发现它对我感兴趣的问题的大小非常缓慢(X有点像3375 by 1500希望甚至更大).
b数值的回归方法?python numpy mathematical-optimization scipy linear-regression
我想知道是否有更好的方法来测试两个变量是否是协整的,而不是以下方法:
import numpy as np
import statsmodels.api as sm
import statsmodels.tsa.stattools as ts
y = np.random.normal(0,1, 250)
x = np.random.normal(0,1, 250)
def cointegration_test(y, x):
# Step 1: regress on variable on the other
ols_result = sm.OLS(y, x).fit()
# Step 2: obtain the residual (ols_resuld.resid)
# Step 3: apply Augmented Dickey-Fuller test to see whether
# the residual is unit root
return ts.adfuller(ols_result.resid)
以上方法有效; 但是,效率不高.当我跑步时sm.OLS,会计算很多东西,而不仅仅是残差,这当然会增加运行时间.我当然可以编写自己的代码来计算残差,但我认为这也不会非常有效.
我正在寻找一种直接测试协整的内置测试.我在想Pandas,但似乎找不到任何东西.或者也许有一个聪明的人来测试协整而不运行回归或一些有效的方法.
我必须进行大量的协整测试,并且很好地改进我当前的方法.
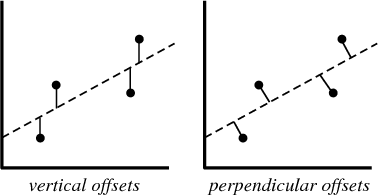
我有兴趣制作一个带有最小二乘回归线和连接数据点与回归线的线段的图,如图所示,称为垂直偏移:http: //mathworld.wolfram.com/LeastSquaresFitting.html alt text http ://mathworld.wolfram.com/images/eps-gif/LeastSquaresOffsets_1000.gif
我在这里完成了情节和回归线:
## Dataset from http://www.apsnet.org/education/advancedplantpath/topics/RModules/doc1/04_Linear_regression.html
## Disease severity as a function of temperature
# Response variable, disease severity
diseasesev<-c(1.9,3.1,3.3,4.8,5.3,6.1,6.4,7.6,9.8,12.4)
# Predictor variable, (Centigrade)
temperature<-c(2,1,5,5,20,20,23,10,30,25)
## For convenience, the data may be formatted into a dataframe
severity <- as.data.frame(cbind(diseasesev,temperature))
## Fit a linear model for the data and summarize the output from function lm()
severity.lm <- lm(diseasesev~temperature,data=severity)
# Take a look at the data
plot(
diseasesev~temperature,
data=severity,
xlab="Temperature",
ylab="% Disease Severity",
pch=16,
pty="s", …有没有人知道在C#中进行多元线性回归的有效方法,其中联立方程的数量可能在1000(有3或4个不同的输入).在阅读了关于多元线性回归的这篇文章之后,我尝试用矩阵方程实现它:
Matrix y = new Matrix(
new double[,]{{745},
{895},
{442},
{440},
{1598}});
Matrix x = new Matrix(
new double[,]{{1, 36, 66},
{1, 37, 68},
{1, 47, 64},
{1, 32, 53},
{1, 1, 101}});
Matrix b = (x.Transpose() * x).Inverse() * x.Transpose() * y;
for (int i = 0; i < b.Rows; i++)
{
Trace.WriteLine("INFO: " + b[i, 0].ToDouble());
}
然而,由于矩阵求逆运算,它不能很好地扩展到1000的方程.我可以调用R语言并使用它,但是我希望有一个纯粹的.Net解决方案可以扩展到这些大型集合.
有什么建议?
编辑#1:
我暂时使用R定居.通过使用statconn(在这里下载),我发现它既快又相对容易使用这种方法.即这里是一个小代码片段,使用R statconn库真的没有太多代码(注意:这不是所有的代码!).
_StatConn.EvaluateNoReturn(string.Format("output <- lm({0})", equation));
object intercept = _StatConn.Evaluate("coefficients(output)['(Intercept)']");
parameters[0] = (double)intercept;
for …在应用L方法确定数据集中k-means聚类的数量之前,有没有人试图将更平滑的应用程序应用于评估指标?如果是这样,它是否改善了结果?或者允许更少数量的k-means试验,从而大大提高速度?您使用了哪种平滑算法/方法?
"L-Method"详述如下: 确定分层聚类/分段算法中的聚类/分段数,Salvador&Chan
这将计算一系列不同试验群集计数的评估指标.然后,为了找到膝盖(出现最佳簇数),使用线性回归拟合两条线.应用简单的迭代过程来改善膝盖拟合 - 这使用现有的评估度量计算,并且不需要重新运行k均值.
对于评估指标,我使用的是Dunns指数的简化版本的倒数.简化速度(基本上我的直径和簇间计算得到简化).倒数使得指数在正确的方向上工作(即,通常更好).
K-means是一种随机算法,因此通常会多次运行并选择最佳拟合.这非常有效,但是当您为1..N群集执行此操作时,时间会快速累加.因此,控制运行次数符合我的利益.整体处理时间可能决定我的实现是否实用 - 如果我无法加速,我可能会抛弃此功能.
我正在尝试通过评估我的回归系数输出来执行特征选择,并选择具有最高幅度系数的特征.问题是,我不知道如何获得相应的功能,因为只有系数从coef._属性返回.文件说:
线性回归问题的估计系数.如果在拟合期间传递多个目标(y 2D),则这是形状的二维数组(n_targets,n_features),而如果仅传递一个目标,则这是长度为n_features的一维数组.
我传入了我的regression.fit(A,B),其中A是一个二维数组,文档中每个特征的tfidf值.示例格式:
"feature1" "feature2"
"Doc1" .44 .22
"Doc2" .11 .6
"Doc3" .22 .2
B是我的数据目标值,它们只是与每个文档相关的数字1-100:
"Doc1" 50
"Doc2" 11
"Doc3" 99
使用regression.coef_,我得到一个系数列表,但不是它们的相应特征!我怎样才能获得这些功能?我猜我需要修改B目标的结构,但我不知道如何.
我试图在我的图表中添加一个线性回归线,但是当它运行时,它没有显示出来.以下代码已简化.每天通常有多个点.除此之外,图表还不错.
b<-data.frame(day=c('05/22','05/23','05/24','05/25','05/26','05/27','05/28','05/29','05/30','05/31','06/01','06/02','06/03','06/04','06/05','06/06','06/07','06/08','06/09','06/10','06/11','06/12','06/13','06/14','06/15','06/16','06/17','06/18','06/19','06/20','06/21','06/22','06/23','06/24','06/25'),
temp=c(10.1,8.7,11.4,11.4,11.6,10.7,9.6,11.0,10.0,10.7,9.5,10.3,8.4,9.0,10.3,11.3,12.7,14.5,12.5,13.2,16.5,19.1,14.6,14.0,15.3,13.0,10.1,8.4,4.6,4.3,4.7,2.7,1.6,1.8,1.9))
gg2 <- ggplot(b, aes(x=day, y=temp, color=temp)) +
geom_point(stat='identity', position='identity', aes(colour=temp),size=3)
gg2<- gg2 + geom_smooth(method='lm') + scale_colour_gradient(low='yellow', high='#de2d26')
gg2 <-gg2 + labs(title=filenames[s], x='Date', y='Temperture (Celsius)') + theme(axis.text.x=element_text(angle=-45, vjust=0.5))
gg2
它可能非常简单,但我似乎无法弄明白.或者这是我使用x轴日期的事实,但我没有收到任何错误.如果是由于日期,我不知道如何处理它.谢谢.
我通过不同情景下的线性回归的一些实例工作,使用比较结果Normalizer和StandardScaler,结果是令人费解.
我正在使用波士顿住房数据集,并以这种方式准备:
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
#load the data
df = pd.DataFrame(boston.data)
df.columns = boston.feature_names
df['PRICE'] = boston.target
我目前正试图推断我从以下场景得到的结果:
normalize=Truevs using 初始化线性回归Normalizerfit_intercept = False带有和不带标准化的参数初始化线性回归.总的来说,我发现结果令人困惑.
这是我如何设置一切:
# Prep the data
X = df.iloc[:, :-1]
y = df.iloc[:, -1:]
normal_X = Normalizer().fit_transform(X)
scaled_X = StandardScaler().fit_transform(X)
#now prepare some of the models …问题提示: 当尝试使用scipy.optimize.fmin_bfgs最小化(优化)函数时,该函数抛出一个
derphi0 = np.dot(gfk,pk)ValueError:矩阵未对齐
错误.根据我的错误检查,这发生在第一次迭代的最后通过fmin_bfgs - 就在返回任何值或任何调用回调之前.
配置: Windows Vista Python 3.2.2 SciPy 0.10 IDE =带有PyDev的Eclipse
详细说明: 我使用scipy.optimize.fmin_bfgs来最小化简单逻辑回归实现的成本(从Octave转换为Python/SciPy).基本上,成本函数名为cost_arr函数,梯度下降在gradient_descent_arr函数中.
我已手动测试并完全验证*cost_arr*和*gradient_descent_arr*正常工作并正确返回所有值.我还测试了验证正确的参数是否传递给*fmin_bfgs*函数.然而,运行时,我得到ValueError:矩阵没有对齐.根据来源评论,确切的错误发生在
def line_search_wolfe1函数在#Minpack的Wolfe行和scaplar搜索中由scipy包提供.
值得注意的是,如果我使用scipy.optimize.fmin,则fmin函数将运行完成.
确切错误:
文件"D:\ Users\Shannon\Programming\Eclipse\workspace\SBML\sbml\LogisticRegression.py",第395行,在fminunc_opt中
Run Code Online (Sandbox Code Playgroud)optcost = scipy.optimize.fmin_bfgs(self.cost_arr, initialtheta, fprime=self.gradient_descent_arr, args=myargs, maxiter=maxnumit, callback=self.callback_fmin_bfgs, retall=True)文件"C:\ Python32x32\lib\site-packages\scipy\optimize\optimize.py",第533行,在fmin_bfgs old_fval,old_old_fval)
文件"C:\ Python32x32\lib\site-packages\scipy\optimize\linesearch. py",第76行,in line_search_wolfe1 derphi0 = np.dot(gfk,pk)ValueError:矩阵未对齐
我用以下方法调用优化函数:optcost = scipy.optimize.fmin_bfgs(self.cost_arr,initialtheta,fprime = self.gradient_descent_arr,args = myargs,maxiter = maxnumit,callback = self.callback_fmin_bfgs,retall = True)
我花了几天时间试图解决这个问题,似乎无法确定是什么导致 矩阵没有对齐错误.
附录:2012-01-08我更多地使用了这个并且似乎已经缩小了问题(但是对于如何修复它们感到困惑).首先,fmin(仅使用fmin)使用这些函数 - 成本,渐变.其次,在手动实现中的单次迭代中测试时,成本和梯度函数都能准确地返回预期值(不使用fmin_bfgs).第三,我在optimize.linsearch中添加了错误代码,错误似乎是在def line_search_wolfe1行中引发的:derphi0 = np.dot(gfk,pk).在这里,根据我的测试,scipy.optimize.optimize pk = [[12.00921659] [11.26284221]] pk type = and …
我用R插入符训练了一个线性回归模型.我现在正在尝试生成混淆矩阵并继续收到以下错误:
confusionMatrix.default(pred,测试$ Final)出错:数据和参考因子必须具有相同的级别数
EnglishMarks <- read.csv("E:/Subject Wise Data/EnglishMarks.csv",
header=TRUE)
inTrain<-createDataPartition(y=EnglishMarks$Final,p=0.7,list=FALSE)
training<-EnglishMarks[inTrain,]
testing<-EnglishMarks[-inTrain,]
predictionsTree <- predict(treeFit, testdata)
confusionMatrix(predictionsTree, testdata$catgeory)
modFit<-train(Final~UT1+UT2+HalfYearly+UT3+UT4,method="lm",data=training)
pred<-format(round(predict(modFit,testing)))
confusionMatrix(pred,testing$Final)
生成混淆矩阵时会发生错误.两个对象的级别相同.我无法弄清问题是什么.它们的结构和水平如下.它们应该是一样的.任何帮助将非常感谢,因为它让我破解!
> str(pred)
chr [1:148] "85" "84" "87" "65" "88" "84" "82" "84" "65" "78" "78" "88" "85"
"86" "77" ...
> str(testing$Final)
int [1:148] 88 85 86 70 85 85 79 85 62 77 ...
> levels(pred)
NULL
> levels(testing$Final)
NULL
artificial-intelligence r classification machine-learning linear-regression
python ×3
r ×3
scikit-learn ×2
scipy ×2
.net ×1
algorithm ×1
c# ×1
ggplot2 ×1
k-means ×1
numpy ×1
pandas ×1
plot ×1
python-3.x ×1
statistics ×1
{kind=link}