标签: kibana
Elasticseach&Kibana - 可视化一年的日志的最佳实践
我正在使用ElasticSearch和Kibana来存储和可视化我的日志中的数据.我知道使用Logstash是习惯做法,但我只是使用elasticsearch Rest API和POST新元素.
考虑到我每天大约有5万条日志,我正在努力寻找最佳实践方法来管理我的指数,我希望有时可视化每周,有时是每月,有时甚至是年度数据.而且我也不需要多个节点.我不需要高可用集群.
所以我基本上试图确定: - 我应该如何按时间存储我的索引?每月?每周?一切都是一个指数? - 一个巨大的索引(一个包含我所有数据的索引)的缺点是什么?这是否意味着整个索引都在内存中?
谢谢.
推荐指数
解决办法
查看次数
没有显示结果,因为所有值都等于 0 - Kibana
我在 kibana 5 上,我有饼图可视化,它说“没有显示结果,因为所有值都等于 0”。
在发现选项卡上一切正常,ChannelID 字段是可搜索和可聚合的。
有任何想法吗?
屏幕:
{kind=link}
{kind=link}
推荐指数
解决办法
查看次数
Terms Aggregations in multiple fields Kibana
I have several fields in ES like:
tank1
tank2
tank3
Every tankID can be in different fields depending on user choice. I wonder if I can count terms from multiple fields(tank1, tank2, tank3) and create graph in kibana 5?
推荐指数
解决办法
查看次数
没有在 ElasticSearch 字段上声明的类型 [geo-point] 的处理程序
我试图将数据中的一个字段映射为 a,geo-point以便我可以在 kibana 的地图上可视化数据。数据存储为一串坐标(例如“12.35,48.64”)。以下是我尝试映射该字段的方式。
"latlong":{
"type":"geo-point",
"fields":{
"raw":{
"type":"keyword",
"ignore_above":256
}
}
},我从 中提取代码GET index/_mapping,然后将类型更改为geo-point,然后出现错误
"type": "mapper_parsing_exception", "reason": "无法解析映射 [docs]: 没有在字段 [latlong] 上声明的类型 [geo-point] 的处理程序",
任何帮助表示赞赏。我是 elasticsearch 的新手,所以这可能很容易解决。
推荐指数
解决办法
查看次数
为什么新创建的索引在发现或创建索引模式中不可用?
我在 Kibana for Elasticsearch 中创建了一个新索引。
开发工具/控制台:
PUT test42
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_doc" : {
"properties" : {
"field1" : { "type" : "text" }
}
}
}
}
然后我检查所有索引:
GET /_cat/indices?v
并得到一个这样的列表:
健康状态指数...
黄色打开测试黄色打开test42
绿色打开.kibana_1
黄色打开test_index2
黄色打开logging-190409
黄色打开time_series_double_values
当我查看 Kibana / Discover 时,我看不到 test42:
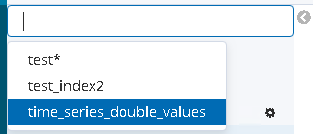
为什么新索引不可用?
我的目标是创建一个用于日志记录的索引模式,如下所述:Logging with ElasticSearch, Kibana, ASP.NET Core and Docker
推荐指数
解决办法
查看次数
根据 Kibana/Elasticsearch 中的条件更新文档中的字段
我正在尝试根据某些条件更新文档中的特定字段。在一般的sql方式中,我想做以下事情。
Update index indexname
set name = "XXXXXX"
where source: file and name : "YYYYYY"
我正在使用下面的内容来更新所有文档,但我无法添加任何条件。
POST indexname/_update_by_query
{
"query": {
"term": {
"name": "XXXXX"
}
}
}
这是我正在使用的模板:
{
"indexname": {
"mappings": {
"idxname123": {
"_all": {
"enabled": false
},
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"date1": {
"type": "date",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"source": {
"type": "text",
"fields": {
"keyword": …推荐指数
解决办法
查看次数
用于创建索引的未知键 [High]
我在弹性搜索中创建了一个索引,看起来像
{"amazingdocs":{"aliases":{},"mappings":{"properties":{"Adj Close":{"type":"text"},"Close":{"type":"text"},"Date":{"type":"text"},"High":{"type":"text"},"Low":{"type":"text"},"Open":{"type":"text"},"Volume":{"type":"text"}}},"settings":{"index":{"creation_date":"1563168811565","number_of_shards":"1","number_of_replicas":"1","uuid":"k2wCARIETvufWmrdkDOtyw","version":{"created":"7020099"},"provided_name":"amazingdocs"}}}}
但是现在当我尝试使用 kibana 在其中插入文档时,出现以下错误
{
"error": {
"root_cause": [
{
"type": "parse_exception",
"reason": "unknown key [High] for create index"
}
],
"type": "parse_exception",
"reason": "unknown key [High] for create index"
},
"status": 400
}
语法,我遵循的是
PUT /amazingdocs/
{
"Date": "1960-10-06",
"Open": "53.720001",
"High": "53.720001",
"Low": "53.720001",
"Close": "53.720001",
"Adj Close": "53.720001",
"Volume": "2510000"
}
此外,当我尝试插入具有类似字段的批量数据时,出现以下错误
"{"took":66336,"errors":true,"items":[{"index":{"_index":"amazingdocs","_type":"_doc","_id":"O7o_9GsBcUaBu1lEWjja","status":400,"error":{"type":"mapper_parsing_exception","reason":"failed to parse","caused_by":{"type":"not_x_content_exception","reason":"Compressor detection can only be called on some xcontent bytes or compressed xcontent bytes"}}}}
推荐指数
解决办法
查看次数
Filebeat 默认仪表板:未找到结果
我刚刚完成了 Logstash、Elasticsearch、Kibana 和 Filebeat 的安装和配置。在 Kibana 接收我的 Logstash 数据遇到很多麻烦之后,我决定停止 Logstash 并切换到 Filebeat。现在,我设法在 Kibana 的 Discover 部分获取了我的 Filebeat 数据,但是在打开任何默认仪表板时,我收到“未找到结果”消息。我希望你们中的一个人能够帮助我。
亲切的问候,蒂斯
Filebeat 配置
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration. enabled: true
# Paths that should be crawled and fetched. …推荐指数
解决办法
查看次数