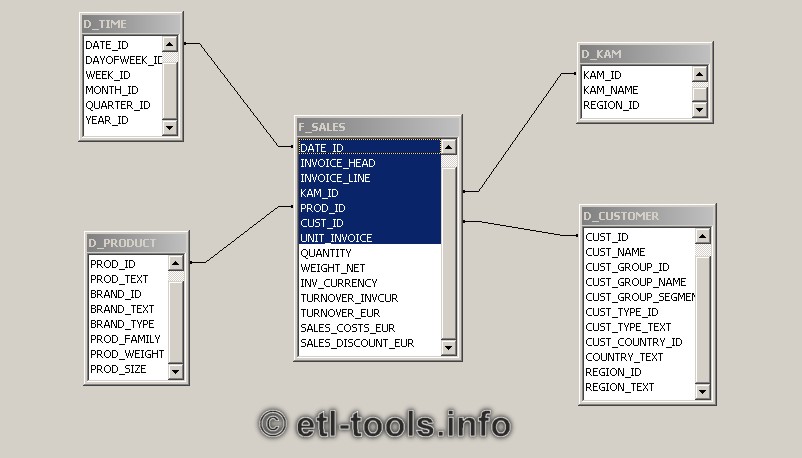
我正在构建一个数据仓库.每个事实都有它的时间戳.我需要按天,月,季度创建报告,但也要按小时创建.在示例中,我看到日期往往会保存在维度表格中.alt starexample http://etl-tools.info/images/dw_star_schema.jpg
但我认为,时间没有意义.维度表将增长和增长.另一方面,使用日期维度表的JOIN比在SQL中使用日期/时间函数更有效.
您有什么意见/解决方案?
(我正在使用Infobright)
我正在建立系统来分析有关证券交易价格的大量金融数据.这方面的一个重大挑战是确定数据将使用哪种存储方法,因为数据将在10的TB级中.将对数据进行许多查询,例如取平均值,计算标准偏差以及按多个列过滤的总和,例如价格,时间,数量等.连接语句不是必需的,但是很高兴.
现在,我正在寻找infobright社区版,monetdb和greenplum社区版用于评估目的.到目前为止,它们看起来很棒,但是对于更高级的功能,某些版本中不提供某些功能(使用多个服务器,插入/更新语句等).
您将在这种情况下使用哪些解决方案,并为替代方案提供哪些好处?具有成本效益是一个重要的优点.如果我必须支付数据仓库解决方案,我会,但我宁愿避免它,并尽可能采用开源/社区版路线.
我们有一个BI客户,他们的销售数据库表每月产生大约4千万行,这些行是根据他们的销售交易生成的.他们希望使用5年的历史数据构建销售数据集市,这意味着该事实表可能会有大约2.4亿行.(40 x 12个月x 5年)
这是结构良好的数据.
这是我第一次面对这么多数据,这让我分析了像Inforbright和其他工具这样的垂直数据库工具.但是仍然使用这种软件,一个简单的查询将需要非常长的时间来运行.
这让我看看Hadoop,但在阅读了一些文章后,我得出结论,Hadoop不是创建事实表的最佳选择(即使使用Hive),因为我的理解是用于处理非结构化数据.
所以,我的问题是:构建这个挑战的最佳方法是什么?,我不是在寻找合适的技术吗?在一个如此重要的事实表中,我能得到的最佳查询响应时间是多少?..或者我在这里面对一个真正的墙,唯一的选择是建立聚合表?
我需要存储大量的小数据对象(每月数百万行).一旦他们得救,他们就不会改变.我需要 :
我的第一个镜头是Infobright Community - 只是一个面向列的,只读的MySQL存储机制
另一方面,人们说NoSQL方法可能会更好.Hadoop + Hive看起来很有问题,但文档看起来很差,版本号小于1.0.
我听说过Hypertable,Pentaho,MongoDB ....
你有什么建议 ?
(是的,我在这里找到了一些主题,但它是一两年前)
编辑:其他解决方案:MonetDB,InfiniDB,LucidDB - 你怎么看?
为Hadoop集群提供数据并使用该集群将数据输入Vertica/InfoBright数据仓库有什么意义?
所有这些供应商都在说"我们可以与Hadoop联系",但我不明白这是什么意思.在Hadoop中存储并转移到InfoBright有什么兴趣?为什么不将应用程序直接存储在Infobright/Vertica DW中?
谢谢 !
我正在处理的应用程序是一个基于Java的ETL过程,它将数据加载到多个表中.DBMS是Infobright(基于MYSQL的DBMS,适用于数据仓库).
数据加载应以原子方式完成; 但是,出于性能原因,我想同时将数据加载到多个表中(使用LOAD DATA INFILE命令).这意味着我需要打开多个连接.
有没有任何解决方案允许我原子地并行地进行负载?(我猜测答案可能取决于我加载的表格的引擎;大多数是Brighthouse,它允许事务,但没有XA和没有保存点).
为了进一步澄清,我想避免让我们说:
在这种情况下,我无法回滚前4个加载,因为它们已经被提交.
{kind=link}