标签: graph-databases
炒作图数据库...为什么?
在今天可以使用图形数据库解决的Web环境中,可以遇到的问题是什么?图形数据库是否适用于经典应用程序,即可以用作关系数据库的替代品吗?所以实际上这是两个问题.
推荐指数
解决办法
查看次数
图表DB与Prolog(或miniKanren)
最近我一直在研究像Neo4j这样的图形数据库,以及Prolog和miniKanren中的逻辑编程.根据我迄今所学到的知识,它们都允许指定它们之间的事实和关系,并且还可以查询生成的系统以进行某些选择.所以,实际上我看不出它们之间的差别很大,因为它们都可以用来构建图形并查询它,但是使用不同的语法.但是,它们是完全不同的软件.
除了数据库可能提出更多时空有效存储技术的技术性,除了像miniKanren这样的微小逻辑核心更简单和可嵌入之外,图形数据库和逻辑编程语言之间的实际区别是什么,如果它们都只是一个图形数据库+查询API?
推荐指数
解决办法
查看次数
图形数据库和RDF三重存储:在python中存储图形数据
我需要在python中开发一个图形数据库(我很乐意,如果有人可以加入我的开发.我已经有了一些代码,但我很乐意讨论它).
我在互联网上做了我的研究.在Java中,neo4j是候选者,但我无法找到任何有关实际磁盘存储的信息.在python中,有许多图形数据模型(参见此PEP前提议,但它们都不能满足我从磁盘存储和检索的需要.
不过,我确实知道三重商店.triplestores基本上都是RDF数据库,所以图形数据模型可以在RDF映射和存储,但我一般不安(主要是由于缺乏经验)对这一解决办法.一个例子是芝麻.事实是,在任何情况下,你必须在内存中的图形表示转换为RDF表示,反之亦然,除非客户端代码想要直接破解RDF文档,这几乎是不可能的.这就像直接处理DB元组,而不是创建一个对象.
什么是国家的最先进的用于存储和检索(一拉在python图形数据的DBMS),此刻?是否有意义开始开发实现,希望在有兴趣的人的帮助下,以及与Graph API PEP的提议者合作?请注意,这将是我未来几个月工作的一部分,所以我对这个最终项目的贡献非常严重;)
编辑:发现也是directededge,但它似乎是一个商业产品
推荐指数
解决办法
查看次数
如何在图形数据库(如Neo4j)中建立真实世界的关系?
我有一个关于在图形数据库中建模的一般性问题,我似乎无法解决这个问题.
你如何模拟这种关系:"牛顿发明了微积分"?
在一个简单的图表中,您可以像这样建模:
Newton (node) -> invented (relationship) -> Calculus (node)
...所以当你添加更多的人和发明时,你会有一堆"发明的"图形关系.
问题是,你开始需要在关系中添加一堆属性:
- invention_date
- influential_concepts
- influential_people
- books_inventor_wrote
...并且您将要开始在这些属性和其他节点之间创建关系,例如:
- influential_people:与人节点的关系
- books_inventor_wrote:与书籍节点的关系
所以现在似乎"真实世界的关系"("发明")实际上应该是图中的一个节点,图形应如下所示:
Newton (node) -> (relationship) -> Invention of Calculus (node) -> (relationship) -> Calculus (node)
更复杂的是,其他人也参与了微积分的发明,所以图形现在变成了:
Newton (node) ->
(relationship) ->
Newton's Calculus Invention (node) ->
(relationship) ->
Invention of Calculus (node) ->
(relationship) ->
Calculus (node)
Leibniz (node) ->
(relationship) ->
Leibniz's Calculus Invention (node) ->
(relationship) ->
Invention of Calculus (node) ->
(relationship) ->
Calculus (node) …推荐指数
解决办法
查看次数
在Cypher中,如果不存在关系,我该如何建立关系; 更新属性,如果它
在Neo4J的Cypher中,给定两个节点,如果它们之间没有关系,我想创建一个权重属性为1的关系(类型为Foo).如果这种关系已经存在,我想增加它的权重属性.
有没有一种方法可以在单个Cypher查询中执行此操作?谢谢!
编辑:一些其他详细信息:节点已创建,唯一且在索引中.
推荐指数
解决办法
查看次数
D3.js是Neo4j Graph DB数据实时可视化的正确选择
我是UW的CS研究生,我的小组正在尝试可视化实时放入neo4j图形数据库的特定网络流量.
我读过许多不同的工具,如gephi,cytoscape,人力车(基于D3.js),其他一些工具,以及D3.js.
我们到目前为止与D3.js一起前进,但想得到社区的意见.我们不能因为neo4j而使用cytoscape,并且认为D3.js在快速实时环境中对于半大数据最有效.
建议?
也许对于另一个问题,还可以随意输入:实现neo4j的最佳方式?Java,Ruby,node.js?
谢谢!
visualization neo4j graph-databases graph-visualization d3.js
推荐指数
解决办法
查看次数
图表数据库能否跨节点有效地分配数据?
如果有人在另一个数据库之上构建数据库,比如twitter已经完成,那么该数据库是否会继承底层数据库的限制和低效?
我对titan db(http://thinkaurelius.com)特别感兴趣,因为他们声称支持跨节点有效地分割数据集.
他们声称支持跨节点分发数据,因为cassandra的效率.然而,neo4j声称他们不在节点之间分配数据,而是在每个节点上复制整个数据集的原因是因为任何离开一个节点的图遍历,因此必须移动到以太网网络,这太慢了要切合实际.
由于cassandra不了解图形,因此无法优化以在一个节点上保持图形遍历.因此,大多数图遍历将跨越节点边界.
泰坦是否声称跨节点有效扩展?
推荐指数
解决办法
查看次数
将图形数据表示为键值对象
我开始深入研究图形数据库,但我不知道这些图形是如何在内部存储的.假设我有这张图(取自维基百科):
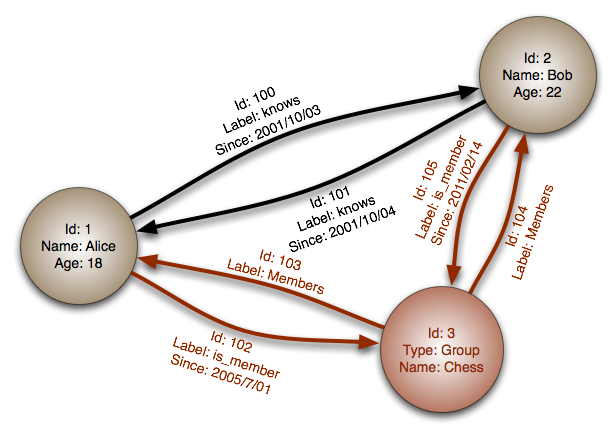
如何将此图表序列化为键值对象?(例如Python dict)
我想象两个dicts,一个用于顶点,一个用于边缘:
{'vertices':
{'1': {'Name': 'Alice', 'Age': 18},
'2': {'Name': 'Bob', 'Age': 22},
'3': {'Type': 'Group', 'Name': 'Chess'}},
'edges':
{'100': {'Label': 'knows', 'Since': '2001/10/03'},
'101': {'Label': 'knows', 'Since': '2001/10/04'},
'102': {'Label': 'is_member', 'Since': '2005/7/01'},
'103': {'Label': 'Members'},
'104': {'Label': 'Members'},
'105': {'Label': 'is_member', 'Since': '2011/02/14'}},
'connections': [['1', '2', '100'], ['2', '1', '101'],
['1', '3', '102'], ['3', '1', '103'],
['3', '2', '104'], ['2', '3', '105']]}
但我不确定,这是否是最实用的实施方案.也许"连接"应该在"顶点"字典内.那么,使用键值对象实现图数据存储的最佳方法是什么?我可以在哪里以及在哪里阅读更多相关内容?
可能相关但不重复:如何在某些数据结构中表示奇怪的图形
推荐指数
解决办法
查看次数
什么时候不使用neo4j?
Neo4j是一个很好的映射关系数据的工具,但我很好奇在什么条件下它不是一个好的工具.
在哪些用例中使用neo4j是一个坏主意?
推荐指数
解决办法
查看次数
什么是最快的ArangoDB朋友的朋友查询(有计数)
我正在尝试使用ArangoDB来获取朋友的朋友列表.不仅仅是一个基本的朋友朋友列表,我还想知道用户和朋友的朋友有多少朋友,并对结果进行排序.在多次尝试(重新)编写性能最佳的AQL查询之后,这就是我最终的结果:
LET friends = (
FOR f IN GRAPH_NEIGHBORS('graph', @user, {"direction": "any", "includeData": true, "edgeExamples": { name: "FRIENDS_WITH"}})
RETURN f._id
)
LET foafs = (FOR friend IN friends
FOR foaf in GRAPH_NEIGHBORS('graph', friend, {"direction": "any", "includeData": true, "edgeExamples": { name: "FRIENDS_WITH"}})
FILTER foaf._id != @user AND foaf._id NOT IN friends
COLLECT foaf_result = foaf WITH COUNT INTO common_friend_count
RETURN {
user: foaf_result,
common_friend_count: common_friend_count
}
)
FOR foaf IN foafs
SORT foaf.common_friend_count DESC
RETURN foaf
不幸的是,性能并不像我想的那么好.与同一查询(和数据)的Neo4j版本相比,AQL似乎相当慢(5-10倍).
我想知道的是......我如何改进查询以使其表现更好?
推荐指数
解决办法
查看次数