标签: gpudirect
AMD的OpenCL是否提供类似于CUDA的GPUDirect的东西?
NVIDIA提供GPUDirect以减少内存传输开销.我想知道AMD/ATI是否有类似的概念?特别:
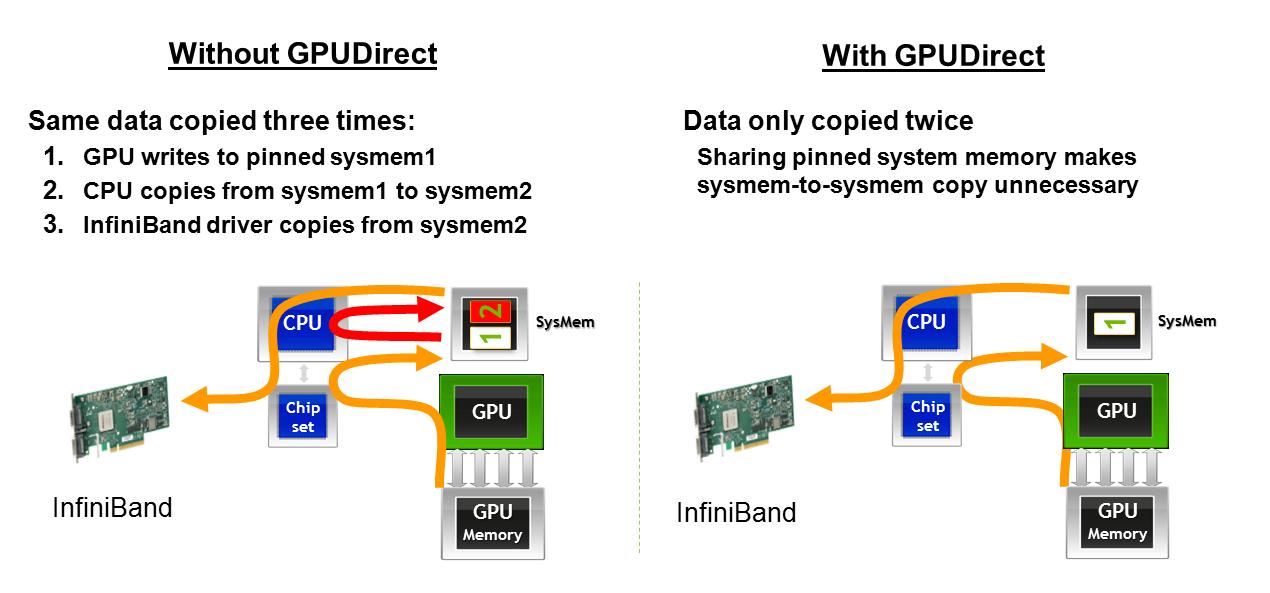
1)AMD GPU在与网卡连接时是否避免第二次内存传输,如此处所述.如果图形在某些时候丢失,这里描述了GPUDirect对从一台机器上的GPU获取数据以通过网络接口传输的影响:使用GPUDirect,GPU内存进入主机内存,然后直接进入网络接口卡.如果没有GPUDirect,GPU内存将转移到一个地址空间中的主机内存,然后CPU必须进行复制以将内存转移到另一个主机内存地址空间,然后它就可以转到网卡.
{kind=link}
2)如果在同一PCIe总线上共享两个GPU,AMD GPU是否允许P2P内存传输,如此处所述.如果图形在某些时候丢失,这里描述了GPUDirect对同一PCIe总线上GPU之间传输数据的影响:使用GPUDirect,数据可以直接在同一PCIe总线上的GPU之间移动,而不会触及主机内存.如果没有GPUDirect,数据总是必须返回到主机才能到达另一个GPU,无论GPU位于何处.
{kind=link}
编辑:BTW,我不完全确定GPUDirect有多少是蒸发器,有多少是实际有用的.我从来没有真正听说过GPU程序员将它用于真实的东西.对此的想法也是受欢迎的.
推荐指数
解决办法
查看次数
GPUDirect RDMA从GPU传输到远程主机
场景:
我有两台机器,一台客户机和一台服务器,与Infiniband连接.服务器机器有一个NVIDIA Fermi GPU,但客户端机器没有GPU.我有一个在GPU机器上运行的应用程序,它使用GPU进行一些计算.GPU上的结果数据从不被服务器机器使用,而是直接发送到客户端机器而无需任何处理.现在我正在做一个cudaMemcpy从GPU获取数据到服务器的系统内存,然后通过套接字将其发送到客户端.我正在使用SDP为此通信启用RDMA.
题:
在这种情况下,我是否可以利用NVIDIA的GPUDirect技术来摆脱cudaMemcpy呼叫?我相信我已正确安装了GPUDirect驱动程序,但我不知道如何在不先将其复制到主机的情况下启动数据传输.
我的猜测是不可能将SDP与GPUDirect结合使用,但还有其他方法可以启动从服务器机器GPU到客户机的RDMA数据传输吗?
额外:如果somone有一个简单的方法来测试我是否正确安装了GPUDirect依赖项,这也是有帮助的!
推荐指数
解决办法
查看次数
nVidia RDMA GPUDirect是否始终仅运行物理地址(在CPU的物理地址空间中)?
我们知道:http://en.wikipedia.org/wiki/IOMMU#Advantages
IOMMU可以支持外围存储器分页.使用PCI-SIG PCIe地址转换服务(ATS)页面请求接口(PRI)扩展的外设可以检测并发出对内存管理器服务的需求.

但是当我们使用CUDA> = 5.0的nVidia GPU时,我们可以使用RDMA GPUDirect,并且知道:
http://docs.nvidia.com/cuda/gpudirect-rdma/index.html#how-gpudirect-rdma-works
传统上,使用CPU的MMU作为内存映射I/O(MMIO)地址,将BAR窗口等资源映射到用户或内核地址空间.但是,由于当前的操作系统没有足够的机制来在驱动程序之间交换MMIO区域,因此NVIDIA内核驱动程序会导出函数以执行必要的地址转换和映射.
http://docs.nvidia.com/cuda/gpudirect-rdma/index.html#supported-systems
从PCI设备的角度来看,GPUDirect的RDMA当前依赖于所有物理地址是相同的.这使它与IOMMU不兼容,因此必须禁用它们才能使RDUD for GPUDirect正常工作.
如果我们将CPU-RAM分配并映射到UVA,如下所示:
#include <iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
int main() {
// Can Host map memory
cudaSetDeviceFlags(cudaDeviceMapHost);
// Allocate memory
unsigned char *host_src_ptr = NULL;
cudaHostAlloc(&host_src_ptr, 1024*1024, cudaHostAllocMapped);
std::cout << "host_src_ptr = " << (size_t)host_src_ptr << std::endl;
// Get UVA-pointer
unsigned int *uva_src_ptr = NULL;
cudaHostGetDevicePointer(&uva_src_ptr, host_src_ptr, 0);
std::cout << "uva_src_ptr = " << (size_t)uva_src_ptr << std::endl;
int b; …推荐指数
解决办法
查看次数
如何在Infiniband中使用GPUDirect RDMA
我有两台机器.每台机器上都有多张特斯拉卡.每台机器上都有一张InfiniBand卡.我想通过InfiniBand在不同机器上的GPU卡之间进行通信.只需点对点单播即可.我当然希望使用GPUDirect RDMA,这样我就可以省去额外的复制操作.
我知道Mellanox现在有一款可用于其InfiniBand卡的驱动程序.但它没有提供详细的开发指南.另外我知道OpenMPI支持我要求的功能.但OpenMPI对于这个简单的任务来说太重了,它不支持单个进程中的多个GPU.
我想知道我是否可以直接使用驱动程序进行通信.代码示例,教程,任何事情都会很好.此外,如果有人能帮助我在OpenMPI中找到处理此问题的代码,我将不胜感激.
推荐指数
解决办法
查看次数