标签: distributed
分布式系统,最佳框架?
我正在构建一个遵循该场景的软件程序:
我有很多计算机,并将每一台计算机添加到一个集群中.集群中的每台计算机都可以将文件添加到分布式表(字典,散列映射,应该足够快).
所以现在我有一个地方,每个人都可以看到组/集群包含哪些文件.现在,组/集群中的计算机请求文件.他可以从分布式表中访问有关该文件的所有信息(在哪台计算机上可以找到该文件等等).
通过某种机制,它应该从B点(具有该文件的计算机)到A点(请求该文件的计算机)获取文件.
基本上它应该进行数据复制.(但对于非常大的文件)
所以你现在可能想知道,这个quy要求的是什么,这里是:
数据复制应该尽可能快.什么是最好的方法?我想过像通量网络这样的东西.
在场景之后使用软件的最佳框架是什么?
我在寻找一个JAVA FRAMEWORK :).(我需要跑完十字架)
谢谢!
推荐指数
解决办法
查看次数
仿真网络断开连接以本地测试分布式应用程序分区
我有几个在localhost上运行的分布式应用程序实例; 每个实例都通过某些端口与其他实例进行通信,所有实例共同构成一个整体.(我实际上是在谈论在Linux上运行的ZooKeeper)
现在我想编写单元测试来模拟整体分区.
例如,我有5个实例,我想将它们分成两组,每组3和2,以便一个组中的实例无法与另一个组中的实例进行通信.当3台机器在一个数据中心,2台机器在另一台数据中心,数据中心被分区时,它将模拟真实情况.
问题主要是使套接字选择性地工作:与一个套接字说话,但不要与另一个套接字说话.我想到的一个解决方案是抽象通信层并将测试规则注入其中(以"如果我是来自一个组的实例我不允许与另一个组的实例对话 - 关闭套接字"的形式或忽略数据或其他任何").
但也许存在一些工具,可能是一些测试框架?一般来说,您如何在分布式应用程序中测试此类案例?
PS尽管问题被标记为"java"(因为ZooKeeper是用Java编写的),但是听到任何其他语言的解决方案,或者语言独立的解决方案 - 可能是一些Linux大师技巧,真是太棒了.
推荐指数
解决办法
查看次数
在这种情况下,Paxos代理的正确行为是什么?
我正在研究Paxos,我对算法在这个人为的例子中应该如何表现感到困惑.我希望下面的图解释了这个场景.
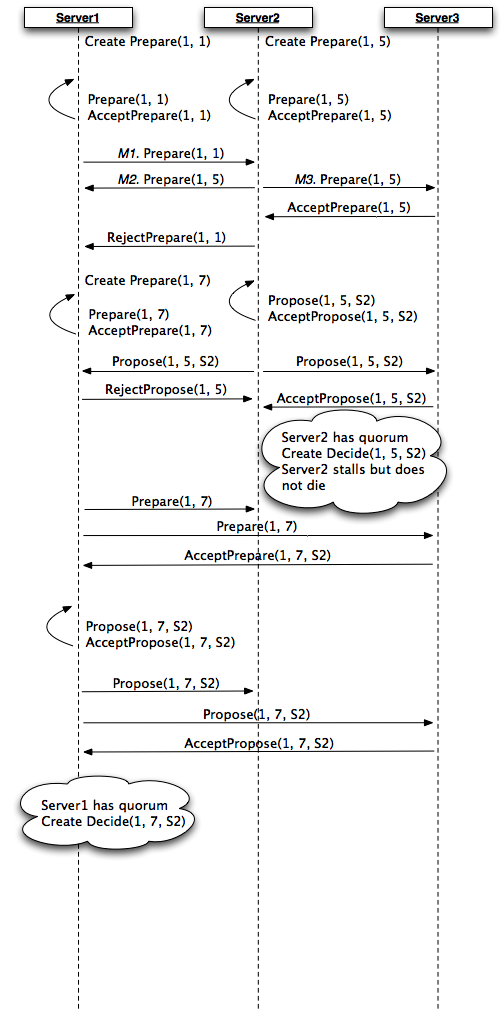
几点:
- 每个代理都充当提议者/接受者/学习者
- 准备消息有形式
(instance, proposal_num) - 建议消息有形式
(instance, proposal_num, proposal_val) - Server1和Server2都决定同时启动提案流程
- 在开始时,消息M1,M2和M3同时发生
在这里似乎虽然协议是"正确的",即只S2选择了一个值,但Server1和Server2认为它是因为提议编号不同而被选中的.
Paxos算法是否仅在将Decide(...)消息发送给学习者时终止?我必须误解Paxos Made Simple,但我认为,当提议者达到他们的Propose(...)消息的法定人数时,就做出了选择.
如果仅在将Decide(...)消息发送给代理之后才进行选择,那么Server2应该Decide(1, 5, S2)在它恢复时终止其发送,因为它稍后会看到它Prepare(1, 7)吗?
推荐指数
解决办法
查看次数
分布式LSH(位置敏感哈希)
我想使用LSH建立具有数百万个高维向量的大型可伸缩数据库。由于必须将所有数据保存在ram中才能进行快速查询,因此必须将数据分发到多个服务器上以容纳所有对象。
幼稚的方法是将所有对象散布到不同的服务器,并向每个服务器发送一个查询。正确答案最佳的服务器具有正确的对象。
我确信必须有一些更好的解决方案,其中不必将查询发送到所有服务器节点,并且将相似的对象分组到一台服务器上。
什么是分布式LSH表的好方法?也许那里甚至有一些项目?
感谢您的任何提示。
推荐指数
解决办法
查看次数
在Node.js中保存应用程序状态
如何保存node.js主要由HTTP请求组成的应用程序的应用程序状态?
我在Node.JS中有一个脚本,它与RESTful API一起将大量(10,000+)以上的产品导入到电子商务应用程序中.API对可以提出的请求数量有限制,我们正在盯着这个限制.在之前的运行中,脚本Error: connect ETIMEDOUT可能由于超出API限制而退出.我希望能够尝试连接5次,如果在恢复限制的一小时后恢复失败.
在发生崩溃(电源中断,网络崩溃等)的情况下保存整个进程也是有益的.并且能够从它停止的位置恢复脚本.
我知道Node.js作为一个巨大的事件队列运行,所有的http请求及其回调都被放入该队列(与其他一些事件一起).这使其成为保存当前执行状态的主要目标.其他令人愉快的(这个项目不是完全必要的)将能够在不同网络上的多台机器之间分配工作以提高吞吐量.
那么有现成的方法吗?也许一个框架?或者我是否需要自己实现这一点,在这种情况下,任何有用的资源如何做到这一点将不胜感激.
推荐指数
解决办法
查看次数
Celery-链接远程回调
我有三个Celery任务,分别在三个不同的服务器上运行。
- task.send_push_notification
- task.send_sms
- task.send_email
我想设置一个工作流,以便如果发送推送通知失败,我应该尝试发送短信。如果发送短信失败,我应该发送电子邮件。
如果这3个任务及其代码库位于同一服务器上,那么我将按照链接任务的示例进行操作,例如
from celery import chain
from tasks import send_push_notification, send_sms, send_email
import json
# some paylaod
payload = json.dumps({})
res = chain(
send_push_notification.subtask(payload),
send_sms.subtask(payload),
send_email.subtask(payload)
)()
但是任务被保存在3个不同的服务器上!
我试过了
# 1
from celery import chain
from my_celery_app import app
res = chain(
app.send_task('tasks.send_push_notification', payload),
app.send_task('tasks.send_sms', payload),
app.send_task('tasks.send_email', payload)
)()
# Which fails because I am chaining tasks not subtasks
和
# 2
from celery import chain, subtask
res = chain(
subtask('tasks.send_push_notification', payload),
subtask('tasks.send_sms', payload), …推荐指数
解决办法
查看次数
为什么1行的DataFrame上的collect()使用2000个exectors?
这是我能想到的最简单的DataFrame.我正在使用PySpark 1.6.1.
# one row of data
rows = [ (1, 2) ]
cols = [ "a", "b" ]
df = sqlContext.createDataFrame(rows, cols)
所以数据框完全适合内存,没有对任何文件的引用,对我来说看起来很微不足道.
然而,当我收集数据时,它使用2000个执行程序:
df.collect()
在收集期间,使用2000执行者:
[Stage 2:===================================================>(1985 + 15) / 2000]
然后是预期的输出:
[Row(a=1, b=2)]
为什么会这样?DataFrame不应该完全在驱动程序的内存中吗?
推荐指数
解决办法
查看次数
Laravel安排在分布式应用程序上
我的应用程序在负载均衡器后面的3台服务器上运行.因此它是无状态的,所有数据都存储在redis和MySQL中.
如果我的机器正在运行工匠cron调度程序,我假设相同的任务将运行3次.一旦在每台机器上,因为不知道它们之间共享的是什么,也就是数据库表.
有什么解决方案?
推荐指数
解决办法
查看次数
如何在分布式Vertx系统中关联日志事件
在vertx的多个模块中执行日志时,基本要求是我们应该能够将单个请求的所有日志关联起来。
由于vertx是异步的,因此保留logid,conversationid和eventid的最佳位置。
我们可以实施任何解决方案或模式吗?
推荐指数
解决办法
查看次数
在张量流分布式训练中如何进行评估和推理?
我了解tensorflow分布式培训,并且实现了自己的脚本。
我现在想要做的是整合为某些工作人员分配异步评估模型任务的可能性。
假设我们有6个工作人员,我要做的是使用其中4个工作人员进行异步培训,一个工作人员定期评估模型,另一个工作人员定期进行模型推断。
我的直觉是实现以下目标:
....
elif FLAGS.job_name == "worker":
if FLAGS.task_index <= (len(cluster_dict["worker"][:-2]) - 1):
logging.info("Training worker started")
...
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster,
ps_tasks=len(cluster_dict["ps"])
)):
train_model = Model(
mode=tf.contrib.learn.ModeKeys.TRAIN
)
with tf.train.MonitoredTrainingSession(
is_chief=(FLAGS.task_index == 0),
master=server.target,
checkpoint_dir=ckpt_dir,
config=config_proto,
hooks=hooks
) as mon_sess:
while not mon_sess.should_stop():
res = train_model.train(...)
...
elif FLAGS.task_index == (len(cluster_dict["worker"][-2]) - 1):
logging.info("Evaluation worker started")
...
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster,
ps_tasks=len(cluster_dict["ps"])
)):
eval_model = Model(
mode=tf.contrib.learn.ModeKeys.EVAL
)
...
elif FLAGS.task_index == (len(cluster_dict["worker"][-1]) - …推荐指数
解决办法
查看次数
标签 统计
distributed ×10
python ×3
algorithm ×2
java ×2
apache-spark ×1
celery ×1
consensus ×1
database ×1
frameworks ×1
hadoop-yarn ×1
hash ×1
javascript ×1
laravel ×1
logging ×1
networking ×1
node.js ×1
paxos ×1
php ×1
pyspark ×1
redis ×1
tensorflow ×1
unit-testing ×1
vert.x ×1