是否可以在不使用create table语句并指定每个列类型的情况下从select语句创建临时(仅会话)表?我知道派生表能够做到这一点,但那些是超临时的(仅限语句),我想重用.
如果我不必编写create table命令并保持列列表和类型列表匹配,那么可以节省时间.
我正在为我的项目团队创建一个状态板模块.状态板允许用户将其状态设置为输入或输出,并且还可以提供注释.我打算将所有信息存储在一个表中......以下是数据示例:
Date User Status Notes
-------------------------------------------------------
1/8/2009 12:00pm B.Sisko In Out to lunch
1/8/2009 8:00am B.Sisko In
1/7/2009 5:00pm B.Sisko In
1/7/2009 8:00am B.Sisko In
1/7/2009 8:00am K.Janeway In
1/5/2009 8:00am K.Janeway In
1/1/2009 8:00am J.Picard Out Vacation
我想查询数据并返回每个用户的最新状态,在这种情况下,我的查询将返回以下结果:
Date User Status Notes
-------------------------------------------------------
1/8/2009 12:00pm B.Sisko In Out to lunch
1/7/2009 8:00am K.Janeway In
1/1/2009 8:00am J.Picard Out Vacation
我试图找出TRANSACT-SQL来实现这一目标?任何帮助,将不胜感激.
我想在SQL Server中使用以下查询创建一个新表.我无法理解为什么这个查询不起作用.
Query1:工作
SELECT * FROM TABLE1
UNION
SELECT * FROM TABLE2
Query2:不起作用.错误:Msg 170, Level 15, State 1, Line 7
Line 7: Incorrect syntax near ')'.
SELECT * INTO [NEW_TABLE]
FROM
(
SELECT * FROM TABLE1
UNION
SELECT * FROM TABLE2
)
谢谢!
因此,它就像我们的正常银行账户,我们有很多交易导致资金流入或流出.总是可以通过简单地总结交易价值来得出账户余额.在这种情况下,将更新的帐户余额存储在数据库中或在需要时重新计算时会更好?
每个帐户的预期交易量:每天<5
预期的帐户余额检索:每当交易发生时,平均每天一次.
您如何建议对此做出决定?非常感谢!
更新:我找到了解决方案.请参阅下面的答案.
如何优化此查询以最大限度地减少停机时间?我需要更新50多个模式,门票数量从100,000到200万不等.是否可以尝试同时在tickets_extra中设置所有字段?我觉得这里有一个解决方案,我只是没有看到.我一直在打击这个问题超过一天.
另外,我最初尝试不使用子SELECT,但表现得太多比我现在有更坏.
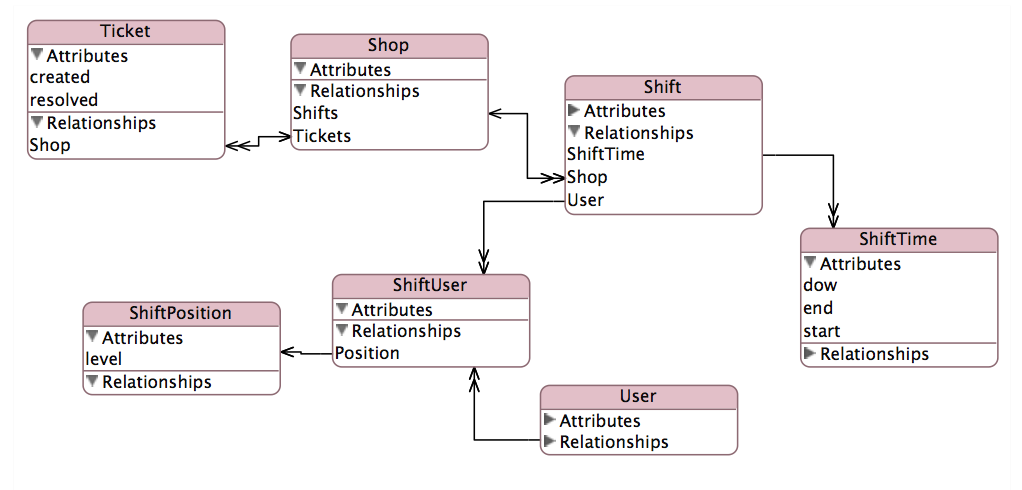
我正在尝试优化我的数据库以获取需要运行的报告.我需要聚合的字段计算起来非常昂贵,因此我对现有模式进行了非规范化以适应此报告.请注意,通过删除几十个不相关的列,我简化了故障单表.
我的报告将按创建时管理器和解析后管理器聚合票证计数.这个复杂的关系如下图所示:
EAV http://cdn.cloudfiles.mosso.com/c163801/eav.png
为了避免在运行中计算这个需要的六个令人讨厌的连接,我已经将以下表添加到我的模式中:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
现在的问题是,我没有将这些数据存储在任何地方.经理总是动态计算.我在几个数据库中拥有数百万张票,这些数据库具有需要填充此表的相同模式.我希望以尽可能高效的方式执行此操作,但是在优化我正在使用的查询时未能成功:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id …问题
我需要更好地理解有关何时可以在子查询中引用外部表以及何时(以及为什么)这是不合适的请求的规则.我在Oracle SQL查询中发现了一个重复,我正在尝试重构,但是当我尝试将我的引用表转换为分组子查询时,我遇到了问题.
以下声明适用:
SELECT t1.*
FROM table1 t1,
INNER JOIN table2 t2
on t1.id = t2.id
and t2.date = (SELECT max(date)
FROM table2
WHERE id = t1.id) --This subquery has access to t1
不幸的是,table2有时会有重复的记录,所以在将它加入t1之前我需要首先聚合t2.但是,当我尝试将其包装在子查询中以完成此操作时,SQL引擎突然无法再识别外部表.
SELECT t1.*
FROM table1 t1,
INNER JOIN (SELECT *
FROM table2 t2
WHERE t1.id = t2.id --This loses access to t1
and t2.date = (SELECT max(date)
FROM table2
WHERE id = t1.id)) sub on t1.id = sub.id
--Subquery loses access to t1
我知道这些是根本不同的查询,我要求编译器放在一起,但我不知道为什么一个会工作而不是另一个.
我知道我可以复制子查询中的表引用,并有效地将子查询从外部表中分离,但这似乎是完成此任务的一种非常难看的方式(所有代码和处理的重复都是如此).
有用的参考资料 …
我有两个名为Check Ins和Check Outs的派生表
检查Ins
CheckDate CheckIn
---------- ---------
08/02/2011 10:10:03
08/02/2011 15:57:16
07/19/2011 13:58:52
07/19/2011 16:50:55
07/26/2011 15:11:24
06/21/2011 12:36:47
08/16/2011 14:49:36
08/09/2011 13:52:10
08/09/2011 16:54:51
08/23/2011 15:48:58
09/06/2011 15:23:00
09/13/2011 10:09:27
09/13/2011 10:40:14
09/13/2011 11:43:14
09/13/2011 11:59:32
09/13/2011 17:05:24
09/20/2011 11:03:42
09/20/2011 12:08:50
09/20/2011 15:21:06
09/20/2011 15:34:29
09/27/2011 11:34:06
10/04/2011 11:37:59
10/04/2011 15:24:04
10/04/2011 16:57:44
10/11/2011 18:19:33
退房
CheckDate CheckOut
---------- ---------
08/02/2011 13:29:40
08/02/2011 17:02:25
07/12/2011 17:06:06
07/19/2011 16:40:15
07/19/2011 17:07:35
07/26/2011 14:48:10
07/26/2011 17:27:08
05/31/2011 17:01:39
06/07/2011 …在派生表上使用CTE是否有任何性能提升?
performance sql-server-2005 derived-table common-table-expression
假设您有这样的查询......
SELECT T.TaskID, T.TaskName, TAU.AssignedUsers
FROM `tasks` T
LEFT OUTER JOIN (
SELECT TaskID, GROUP_CONCAT(U.FirstName, ' ',
U.LastName SEPARATOR ', ') AS AssignedUsers
FROM `tasks_assigned_users` TAU
INNER JOIN `users` U ON (TAU.UserID=U.UserID)
GROUP BY TaskID
) TAU ON (T.TaskID=TAU.TaskID)
可以将多个人分配给给定任务.此查询的目的是为每个任务显示一行,但将人员分配给单个列中的任务
现在...假设你有正确的指标设置上tasks,users和tasks_assigned_users.在连接tasks到派生表时,MySQL Optimizer仍然不会使用TaskID索引.WTF?!?!?
所以,我的问题是......如何使这个查询使用tasks_assigned_users.TaskID上的索引?临时表是蹩脚的,所以如果这是唯一的解决方案...... MySQL优化器是愚蠢的.
使用的索引:
编辑:此外,此页面表示派生表在连接发生之前执行/实现.为什么不重新使用密钥来执行连接?
编辑2: MySQL优化器不会让你在派生表上放置索引提示(大概是因为派生表上没有索引)
编辑3:这是一篇非常好的博客文章:http: …
我一直认为View是一个存储查询.最近我需要在项目中使用派生表.这让我想到了观点.
是否与派生表视图相同,除了它已被保存为动态构建派生表的逻辑实体?
derived-table ×10
sql ×6
mysql ×3
optimization ×2
t-sql ×2
create-table ×1
database ×1
datetime ×1
inline-view ×1
join ×1
left-join ×1
performance ×1
select ×1
sql-server ×1
subquery ×1
temp-tables ×1
union ×1
validation ×1
view ×1
{kind=link}