标签: database-performance
多个模式与巨大的表格
考虑一个移动设备管理器系统,其中包含每个用户的信息,例如存储他已安装在手机上的应用程序的表,审核详细信息,通知信息等.为每个用户创建一个单独的模式以及相应的表是明智的吗?对于单个用户而言,表的数量很大,每个用户大约30个表.拥有一个单独的模式,将所有这些信息放入这些表(反过来创建庞大的表?)或为每个用户设置模式会更好吗?
提前致谢
推荐指数
解决办法
查看次数
PostgreSql表中UUID,CHAR和VARCHAR之间的性能差异?
我将UUID v4值存储在PostgreSQL v9.4表的"id"列下.
当我创建表时,无论是将"id"列定义为VARCHAR(36),CHAR(36)还是UUID数据类型,后续写入或读取性能是否有任何差异?
谢谢!
推荐指数
解决办法
查看次数
针对每个N的最新记录的最佳执行查询
这是我发现自己的情景.
我有一个相当大的表,我需要查询来自的最新记录.以下是查询基本列的创建:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
ID列是主键,VehicleID和TimeStamp上有非Clustered索引
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
我正在努力优化我的查询的表是超过2300万行,并且只是查询需要操作的大小的十分之一.
我需要为每个VehicleID返回最新的行.
我一直在查看StackOverflow上对这个问题的回答,我已经做了很多谷歌搜索,似乎有3或4种常见的方法在SQL Server 2005及更高版本上执行此操作.
到目前为止,我发现的最快的方法是以下查询:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
使用表中的当前数据量,执行大约需要6秒,这在合理的限制范围内,但是在实时环境中,表将包含的数据量开始执行得太慢.
查看执行计划,我关心的是SQL Server正在做什么来返回行.
我无法发布执行计划图像,因为我的声誉不够高,但索引扫描正在解析表中的每一行,这使得查询速度下降太多.
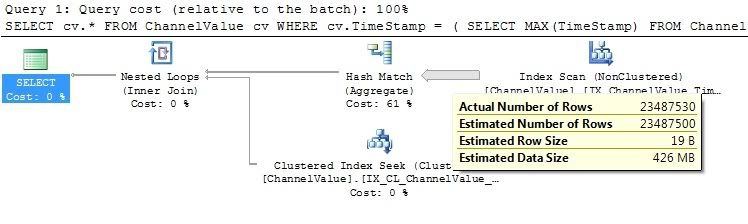
我尝试用几种不同的方法重写查询,包括使用SQL 2005 Partition方法,如下所示: …
t-sql sql-server performance database-performance greatest-n-per-group
推荐指数
解决办法
查看次数
为什么SQL Server不使用计算列上的索引?
在SQL Server 2014 DB中给出以下内容:
create table t
(
c1 int primary key,
c2 datetime2(7),
c3 nvarchar(20),
c4 as cast(dbo.toTimeZone(c2, c3, 'UTC') as date) persisted
);
create index i on t (c4);
declare @i int = 0;
while @i < 10000
begin
insert into t (c1, c2, c3) values
(@i, dateadd(day, @i, '1970-01-02 03:04:05:6'), 'Asia/Manila');
set @i = @i + 1;
end;
toTimeZone是一个CLR UDF,它将datetime2时区转换为datetime2另一个时区.
当我运行以下查询时:
select c1
from t
where c4 >= '1970-01-02'
and c4 <= …sql-server performance query-optimization database-performance sql-server-2014
推荐指数
解决办法
查看次数
服务器可以处理多少个MySql查询/秒?
我已经开始开发一个浏览器(数据库)游戏.我的问题是有多少查询可以常规托管处理(当我的意思是常规,我的意思是你可以找到约7美元/月的共享主机).至于查询,没什么复杂的(简单的SELECT和WHERE操作).
那么......?10?100?10000?
推荐指数
解决办法
查看次数
如何清除MySQL查询配置文件
在MySQL中启用分析后
SET profiling=1;
我可以像查询一样运行,SELECT NOW(); 并使用以下命令查看配置文件结果的执行时间:
SHOW PROFILES;
但是,我无法弄清楚如何清除配置文件列表.有人知道删除旧配置文件数据的声明吗?SET profiling=0;只是禁用新数据的记录,不会删除旧的统计信息.
推荐指数
解决办法
查看次数
mysql命令由-id vs命令由id desc命令
我希望从1M行的表中获取最后10行.
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`updated_date` datetime NOT NULL,
PRIMARY KEY (`id`)
)
这样做的一种方法是 -
select * from test order by -id limit 10;
**10 rows in set (0.14 sec)**
另一种方法是 -
select * from test order by id desc limit 10;
**10 rows in set (0.00 sec)**
所以我对这些查询进行了"解释" -
以下是我使用'order by desc'的查询结果
EXPLAIN select * from test order by id desc limit 10;

以下是我使用'order by -id'的查询结果
EXPLAIN select * from test order by -id …推荐指数
解决办法
查看次数
使用filesort,MYSQL性能变慢
我有一个简单的MySQL查询,但是当我有很多的记录(目前103,0000),性能实在是太慢了,它说,它是使用文件排序,林不知道这是为什么它是缓慢的.有没有人建议加快它?或者使用filesort停止它?
MYSQL查询:
SELECT adverts .*
FROM adverts
WHERE (
price >='0'
)
AND (
adverts.status = 1
)
AND (
adverts.approved = 1
)
ORDER BY date_updated DESC
LIMIT 19990 , 10
解释结果:
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE adverts range price price 4 NULL 103854 Using where; Using filesort
这是广告表和索引:
CREATE TABLE `adverts` (
`advert_id` int(10) NOT NULL AUTO_INCREMENT,
`user_id` int(10) NOT NULL,
`type_id` tinyint(1) NOT NULL,
`breed_id` int(10) NOT NULL,
`advert_type` tinyint(1) …推荐指数
解决办法
查看次数
为什么Oracle使用ORDER BY忽略索引?
我的目的是获得客户的分页结果集.我正在使用Tom的这个算法:
select * from (
select /*+ FIRST_ROWS(20) */ FIRST_NAME, ROW_NUMBER() over (order by FIRST_NAME) RN
from CUSTOMER C
)
where RN between 1 and 20
order by RN;
我还在"CUSTOMER"列上定义了一个索引."FIRST_NAME":
CREATE INDEX CUSTOMER_FIRST_NAME_TEST ON CUSTOMER (FIRST_NAME ASC);
查询返回预期的结果集,但是从解释计划中我注意到没有使用索引:
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15467 | 679K| 157 (3)| 00:00:02 |
| 1 | SORT ORDER BY | | 15467 …sql oracle performance database-performance sql-execution-plan
推荐指数
解决办法
查看次数
Rails:加入记录的性能问题
我使用ActiveRecord和MySQL进行以下设置:
用户通过成员身份拥有多个组通过成员身份,
组拥有许多用户
schema.rb中还描述了group_id和user_id的索引:
add_index "memberships", ["group_id", "user_id"], name: "uugj_index", using: :btree
3个不同的查询:
User.where(id: Membership.uniq.pluck(:user_id))`
(3.8ms)SELECT DISTINCT
memberships.user_idFROMmembershipsUser Load(11.0ms)SELECTusers.*FROMusersWHEREusers.idIN(1,2 ......)
User.where(id: Membership.uniq.select(:user_id))
用户加载(15.2ms)SELECT
users.*FROMusersWHEREusers.idIN(SELECT DISTINCTmemberships.user_idFROMmemberships)
User.uniq.joins(:memberships)
用户负载(135.1ms)SELECT DISTINCT
users.*FROMusersINNER JOINmembershipsONmemberships.user_id=users.id
这样做的最佳方法是什么?为什么带连接的查询要慢得多?
mysql activerecord ruby-on-rails database-performance ruby-on-rails-4
推荐指数
解决办法
查看次数
标签 统计
mysql ×5
performance ×4
sql ×2
sql-server ×2
activerecord ×1
database ×1
filesort ×1
multi-tenant ×1
optimization ×1
oracle ×1
postgresql ×1
profiling ×1
select ×1
sqldatatypes ×1
t-sql ×1