标签: byte-order-mark
推荐指数
解决办法
查看次数
将带有BOM的UTF-8转换为UTF-8,在Python中没有BOM
这里有两个问题.我有一组文件,通常是带有BOM的UTF-8.我想将它们(理想情况下)转换为没有BOM的UTF-8.似乎codecs.StreamRecoder(stream, encode, decode, Reader, Writer, errors)会处理这个问题.但我真的没有看到任何关于使用的好例子.这是处理这个的最佳方法吗?
source files:
Tue Jan 17$ file brh-m-157.json
brh-m-157.json: UTF-8 Unicode (with BOM) text
此外,如果我们能够处理不同的输入编码而不明确地知道(看到ASCII和UTF-16),那将是理想的.看起来这应该都是可行的.有没有可以将任何已知的Python编码和输出作为UTF-8而无BOM的解决方案?
从下面编辑1提出的sol'n(谢谢!)
fp = open('brh-m-157.json','rw')
s = fp.read()
u = s.decode('utf-8-sig')
s = u.encode('utf-8')
print fp.encoding
fp.write(s)
这给了我以下错误:
IOError: [Errno 9] Bad file descriptor
新闻快报
我在评论中被告知错误是我用模式'rw'而不是'r +'/'r + b'打开文件,所以我最终应该重新编辑我的问题并删除已解决的部分.
推荐指数
解决办法
查看次数
创建没有BOM的文本文件
我试过这个方法没有任何成功
我正在使用的代码:
// File name
String filename = String.Format("{0:ddMMyyHHmm}", dtFileCreated);
String filePath = Path.Combine(Server.MapPath("App_Data"), filename + ".txt");
// Process
myObject pbs = new myObject();
pbs.GenerateFile();
// pbs.GeneratedFile is a StringBuilder object
// Save file
Encoding utf8WithoutBom = new UTF8Encoding(true);
TextWriter tw = new StreamWriter(filePath, false, utf8WithoutBom);
foreach (string s in pbs.GeneratedFile.ToArray())
tw.WriteLine(s);
tw.Close();
// Push Generated File into Client
Response.Clear();
Response.ContentType = "application/vnd.text";
Response.AppendHeader("Content-Disposition", "attachment; filename=" + filename + ".txt");
Response.TransmitFile(filePath);
Response.End();
结果:

无论如何都在编写BOM,特殊字符(如ÆØÅ)不正确: - / …
推荐指数
解决办法
查看次数
如何删除多个UTF-8 BOM序列
使用PHP5(cgi)从文件系统输出模板文件,并且有问题吐出原始HTML.
private function fetch($name) {
$path = $this->j->config['template_path'] . $name . '.html';
if (!file_exists($path)) {
dbgerror('Could not find the template "' . $name . '" in ' . $path);
}
$f = fopen($path, 'r');
$t = fread($f, filesize($path));
fclose($f);
if (substr($t, 0, 3) == b'\xef\xbb\xbf') {
$t = substr($t, 3);
}
return $t;
}
即使我已经添加了BOM修复程序,我仍然遇到Firefox接受它的问题.你可以在这里看到一个实时的副本:http://ircb.in/jisti/(如果你想查看它,我在http://ircb.in/jisti/home.html投掷的模板文件)
知道如何解决这个问题吗?O_O
推荐指数
解决办法
查看次数
如何在带有BOM的UTF8编码的C#中使用GetBytes()?
我在C#中的asp.net mvc 2应用程序中遇到UTF8编码问题.我正在尝试让用户从字符串下载一个简单的文本文件.我试图用以下行获取字节数组:
var x = Encoding.UTF8.GetBytes(csvString);
但当我使用以下命令返回下载时:
return File(x, ..., ...);
我得到一个没有BOM的文件,所以我没有正确显示克罗地亚字符.这是因为我的bytes数组在编码后不包含BOM.我手动插入这些字节然后它正确显示,但这不是最好的方法.
我还尝试创建UTF8Encoding类实例并将布尔值(true)传递给其构造函数以包含BOM,但它也不起作用.
有人有解决方案吗?谢谢!
推荐指数
解决办法
查看次数
将UTF-8 BOM添加到字符串/ Blob
我需要在客户端为生成的文本数据添加UTF-8字节顺序标记.我怎么做?
当然,使用new Blob(['\xEF\xBB\xBF' + content])产量'"my data"'.
也没有'\uBBEF\x22BF'工作('\x22' == '"'成为下一个角色content).
是否可以将JavaScript中的UTF-8 BOM添加到生成的文本中?
是的,在这种情况下我确实需要UTF-8 BOM.
推荐指数
解决办法
查看次数
使用Emacs删除字节顺序标记(BOM)
我有一个包含带字节顺序标记的UTF-8编码文本的文件.这个BOM会妨碍事情,我想删除它.
使用其他工具(如perl或awk)或奇怪的编辑模式(如hexl-mode),每次我想摆脱BOM都有点烦人.
有没有办法告诉Emacs删除现有的BOM,而不是在后续保存时再将其写入磁盘?
推荐指数
解决办法
查看次数
将BOM添加到UTF-8文件
我正在搜索(没有成功)一个脚本,它可以作为一个批处理文件使用,如果它没有,我可以在它前面添加一个带有BOM的UTF-8文本文件.
它所写的语言(perl,python,c,bash)和它所使用的操作系统都不重要.我可以使用各种计算机.
我发现有很多脚本可以反向(剥离BOM),这听起来有些愚蠢,因为许多Windows程序如果没有BOM,就会无法读取UTF-8文本文件.
我错过了明显的吗?
谢谢!
推荐指数
解决办法
查看次数
如何避免在读取文件时跳过UTF-8 BOM
我正在使用最近添加了Unicode BOM头(U + FEFF)的数据源,而我的rake任务现在被它搞砸了.
我可以跳过前3个字节,file.gets[3..-1]但有没有更优雅的方式来读取Ruby中的文件,无论BOM是否存在,都能正确处理?
推荐指数
解决办法
查看次数
XML - 根级别的数据无效
我有一个用UTF-8编码的XSD文件,我运行它的任何文本编辑器都没有在文件开头显示任何字符,但是当我在Visual Studio的调试器中提取它时,我清楚地看到一个空的文件前面的框.
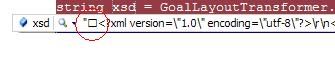
我也得到错误:
根级别的数据无效.第1行,第1位.
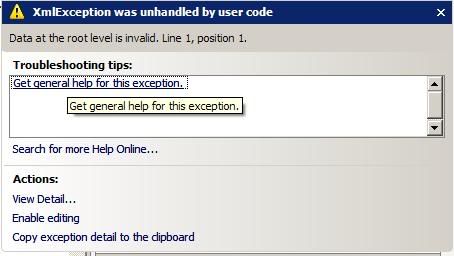
有谁知道这是什么吗?
更新:编辑帖子以限定文件类型.这是由Microsoft的XSD创建者创建的XSD文件.
推荐指数
解决办法
查看次数
标签 统计
byte-order-mark ×10
utf-8 ×5
unicode ×2
xml ×2
.net ×1
asp.net-3.5 ×1
asp.net-mvc ×1
batch-file ×1
blob ×1
c# ×1
emacs ×1
encoding ×1
file ×1
fileapi ×1
javascript ×1
php ×1
python ×1
ruby ×1
scripting ×1
text-files ×1
utf-16 ×1
xsd ×1
xslt ×1