标签: bayesian
在JAGS中以"计数过程"形式表示参数生存模型
问题
我正在尝试在JAGS中建立一个生存模型,允许时变协变量.我希望它是一个参数模型 - 例如,假设生存遵循威布尔分布(但我想让危险变化,所以指数太简单了).因此,这基本上是可以在flexsurv包中完成的贝叶斯版本,它允许参数模型中的时变协变量.
因此,我希望能够以"计数过程"形式输入数据,其中每个主题有多行,每行对应于其协变量保持不变的时间间隔(如本pdf或此处所述).这是包或包允许的(start, stop]配方.survivalflexurv
不幸的是,关于如何在JAGS中进行生存分析的每一个解释似乎都假设每个主题一行.
我试图采用这种更简单的方法并将其扩展到计数过程格式,但模型没有正确估计分布.
失败的尝试:
这是一个例子.首先,我们生成一些数据:
library('dplyr')
library('survival')
## Make the Data: -----
set.seed(3)
n_sub <- 1000
current_date <- 365*2
true_shape <- 2
true_scale <- 365
dat <- data_frame(person = 1:n_sub,
true_duration = rweibull(n = n_sub, shape = true_shape, scale = true_scale),
person_start_time = runif(n_sub, min= 0, max= true_scale*2),
person_censored = (person_start_time + true_duration) > current_date,
person_duration = ifelse(person_censored, current_date - person_start_time, true_duration)
)
person person_start_time …推荐指数
解决办法
查看次数
什么是以5星评级排序的更好方法?
我正在尝试使用5星系统按客户评级对一堆产品进行排序.我设置的网站没有很多评级,并继续添加新产品,所以它通常会有一些评级较低的产品.
我尝试使用平均星级评级,但是当评级很少时,该算法会失败.
例如,具有3x5星评级的产品将比具有100x5星评级和2x2星评级的产品更好.
第二个产品是否应该显得更高,因为它在统计上更值得信赖,因为评级数量更多?
推荐指数
解决办法
查看次数
用于特定应用的贝叶斯网络的pythonic实现
这就是我问这个问题的原因: 去年我制作了一些C++代码来计算特定类型模型的后验概率(由贝叶斯网络描述).该模型工作得很好,其他一些人开始使用我的软件.现在我想改进我的模型.由于我已经为新模型编写了略微不同的推理算法,因此我决定使用python,因为运行时并不重要,python可以让我制作更优雅和易于管理的代码.
通常在这种情况下我会在python中搜索现有的贝叶斯网络包,但我正在使用的推理算法是我自己的,我也认为这将是一个很好的机会,可以在python中学习更多有关优秀设计的知识.
我已经为网络图(networkx)找到了一个很棒的python模块,它允许你将字典附加到每个节点和每个边缘.从本质上讲,这将让我给出节点和边缘属性.
对于特定网络及其观察数据,我需要编写一个函数来计算模型中未分配变量的可能性.
例如,在经典的"亚洲"网络(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png)中,以"XRay Result"和"Dyspnea"状态着称,我需要编写一个函数计算其他变量具有某些值的可能性(根据某些模型).
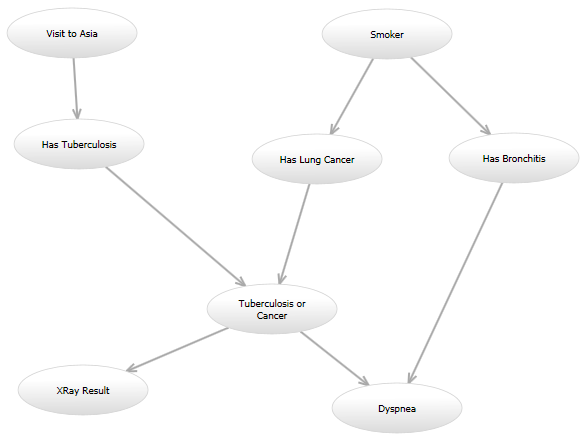{kind=link}
这是我的编程问题: 我将尝试一些模型,将来我可能会想要尝试另一种模型.例如,一个模型看起来可能与亚洲网络完全一样.在另一个模型中,可以从"访问亚洲"到"有肺癌"添加有针对性的边缘.另一个模型可能使用原始有向图,但给定"肺结核或癌症"和"支气管炎"节点的"呼吸困难"节点的概率模型可能不同.所有这些模型都将以不同的方式计算可能性.
所有模型都会有很大的重叠; 例如,如果所有输入都为"0",则进入"或"节点的多个边将始终为"0",否则为"1".但是一些模型将具有在某个范围内采用整数值的节点,而其他模型将是布尔值.
在过去,我一直在努力解决如何编程这样的事情.我不会撒谎; 有相当数量的复制和粘贴代码,有时我需要将单个方法中的更改传播到多个文件.这次我真的想花时间以正确的方式做到这一点.
一些选择:
- 我已经以正确的方式做到了这一点.首先编码,稍后再提问.复制和粘贴代码更快,每个模型都有一个类.世界是一个黑暗无序的地方......
- 每个模型都是它自己的类,但也是一般BayesianNetwork模型的子类.这个通用模型将使用一些将被覆盖的函数.Stroustrup会感到自豪.
- 在同一个类中创建几个函数来计算不同的可能性.
- 对一般的BayesianNetwork库进行编码,并将此推理问题作为此库读入的特定图形来实现.应给予节点和边缘属性,如"布尔"和"OrFunction",给定父节点的已知状态,可用于计算不同结果的概率.这些属性字符串,如"OrFunction"甚至可用于查找和调用正确的函数.也许在几年后我会制作类似于1988版Mathematica的东西!
非常感谢你的帮助.
Update: Object oriented ideas help a lot here (each node has a designated set of predecessor nodes of a certain node subtype, and each node has a likelihood function that computes its likelihood of different outcome states given the states of the predecessor nodes, etc.). OOP FTW!
推荐指数
解决办法
查看次数
如何使用多因子加权排序提供最相关的结果
我需要对2+个因子进行加权排序,按"相关性"排序.然而,这些因素并非完全孤立,因为我希望一个或多个因素影响其他因素的"紧迫性"(权重).
示例:贡献的内容(文章)可以上/下投票,因此具有评级; 他们有一个发布日期,他们也被标记为类别.用户撰写文章并可以投票,并且可能有也可能没有自己的某种排名(专家等).可能与StackOverflow类似,对吧?
我想为每个用户提供按标签分组但按"相关性"排序的文章列表,其中相关性是根据文章的评级和年龄计算的,并且可能受作者排名的影响.IE是几年前写的一篇排名很高的文章可能不一定像昨天写的中等文章一样重要.也许如果一篇文章是由专家撰写的,那么它将被视为比"Joe Schmoe"所写的文章更具相关性.
另一个很好的例子是为酒店分配一个由价格,评级和景点组成的"元评分".
我的问题是,多因素排序的最佳算法是什么?这可能是该问题的重复,但我对任意数量因素的通用算法感兴趣(更合理的期望是2 - 4个因素),最好是我不需要的"全自动"功能调整或要求用户输入,我无法解析线性代数和特征向量古怪.
到目前为止我找到的可能性:
注意:S是"排序分数"
推荐指数
解决办法
查看次数
PyMC:利用自适应大都市MCMC中的稀疏模型结构
我有一个模型,如下图所示:

我有几个人口(在这张照片中索引1 ... 5).人口参数(A和B,但可以有更多)确定每个人的潜在变量的分布L[i].潜在变量以概率方式L[i]确定观察X[i].在大多数节点没有直接连接它们的边缘的意义上,该模型是"稀疏的".
我试图使用PyMC来推断人口参数,以及每个人的潜在变量.(一个相关的问题,其中详细描述了我的具体情况,是在这里.)我的问题是:我应该使用自适应大都市,而不是另一种方法,如果是这样,有没有"猫腻",以正确分组随机变量?
如果我理解正确的自适应都市报采样(和我可能不会...),该算法提出了一种未知的新值(A,B以及所有L[i]通过考虑这些变量是如何在目前为止在运行构造的后验分布相关) .如果A且B是负相关的,那么增加的提案A将倾向于减少B,反之亦然,以增加提案被接受的机会.
问题是,在这个模型中,每个L[i]都是由A和确定的基础人口分布的独立抽取B.因此,虽然他们将被视为在后方相关联,但这些相关性实际上是由于A并且是B单独的,因此它们以某种方式"混淆".所以当我调用这个函数时
M.use_step_method(pymc.AdaptiveMetropolis, stochastics)
是否所有人都应该L[i]在随机指标列表中?或者我应该多次调用use_step_method,每次stochastics=[A, B, L[i]]只调用一个L[i]?我的想法是,对于不同的随机指标组多次调用该函数将构成问题并使PyMC更容易通过告诉它只关注重要的相关性.它是否正确?
推荐指数
解决办法
查看次数
使用贝叶斯优化的深度学习结构的超参数优化
我已经为原始信号分类任务构建了CLDNN(卷积,LSTM,深度神经网络)结构.
每个训练时期运行大约90秒,超参数似乎很难优化.
我一直在研究各种方法来优化超参数(例如随机或网格搜索),并发现贝叶斯优化.
虽然我还没有完全理解优化算法,但我喜欢它会对我有很大帮助.
我想问几个关于优化任务的问题.
- 如何针对深层网络设置贝叶斯优化?(我们尝试优化的成本函数是多少?)
- 我想要优化的功能是什么?它是N个时代之后验证集的成本吗?
- 留兰香是这项任务的良好起点吗?有关此任务的任何其他建议吗?
我非常感谢对此问题的任何见解.
optimization machine-learning bayesian deep-learning tensorflow
推荐指数
解决办法
查看次数
构建NetHack机器人:贝叶斯分析是一个好策略吗?
我的一个朋友开始构建一个NetHack bot(一个玩Roguelike游戏的机器人:NetHack).类似的游戏Angband有一个非常好的工作机器人,但它部分工作,因为回到城镇很容易,并总是能够低水平获得物品.
在NetHack中,问题要困难得多,因为游戏奖励了鼓舞人心的实验,并且基本上构建为1000个边缘案例.
最近我建议使用某种天真的贝叶斯分析,就像创建垃圾邮件一样.
基本上,机器人首先会建立一个语料库,通过尝试每个可能的行动来查找它所发现的每个物品或生物,并将这些信息存储起来,例如,死亡的接近程度,负面影响的伤害.随着时间的推移,您似乎可以生成一个合理的可玩模型.
任何人都能指出我们正确的方向是一个良好的开端吗?我是在吠叫错误的树还是误解了贝叶斯分析的想法?
编辑:我的朋友提出了他的NetHack补丁的github回购,允许python绑定.它仍处于一个非常原始的状态,但如果有人感兴趣...
推荐指数
解决办法
查看次数
pymc如何代表先前的分布和似然函数?
如果pymc实现Metropolis-Hastings算法从感兴趣的参数中提取后验密度的样本,那么为了决定是否移动到马尔可夫链中的下一个状态,它必须能够评估与后验成比例的事物.所有给定参数值的密度.
后验密度与基于观察数据乘以先前密度的似然函数成比例.
如何在pymc中代表这些?它如何从模型对象计算这些数量?
我想知道是否有人能给我一个关于这种方法的高级描述,或者指出我能找到它的地方.
推荐指数
解决办法
查看次数
用于Python的贝叶斯垃圾邮件过滤库
我正在寻找一个进行贝叶斯垃圾邮件过滤的Python库.我查看了SpamBayes和OpenBayes,但两者似乎都没有维护(我可能错了).
任何人都可以建议一个很好的Python(或Clojure,Common Lisp,甚至Ruby)库实现贝叶斯垃圾邮件过滤?
提前致谢.
澄清:我实际上在寻找贝叶斯垃圾邮件分类器,而不一定是垃圾邮件过滤器.我只想用一些数据训练它,然后告诉我一些给定的数据是否是垃圾邮件.对不起任何困惑.
推荐指数
解决办法
查看次数
贝叶斯网络与贝叶斯分类器
贝叶斯网络和朴素贝叶斯分类器有什么区别?我注意到一个是在matlab中实现的,因为classify另一个有一个完整的网络工具箱.
如果你能在答案中解释哪一个更有可能提供更好的准确性,我将不胜感激(不是先决条件).
matlab machine-learning bayesian bayesian-networks naivebayes
推荐指数
解决办法
查看次数
标签 统计
bayesian ×10
python ×4
algorithm ×2
mcmc ×2
pymc ×2
sorting ×2
bots ×1
jags ×1
matlab ×1
naivebayes ×1
nethack ×1
optimization ×1
r ×1
rating ×1
relevance ×1
statistics ×1
tensorflow ×1
weibull ×1