标签: audio-processing
使用C处理音频wav文件
我正在处理wav文件的幅度并按一些小数因子进行缩放.我试图以有效记忆的方式阅读和重写文件,同时也试图解决语言的细微差别(我是C的新手).该文件可以是8位或16位格式.我想这样做的方法是首先将头数据读入一些预定义的结构,然后在循环中处理实际数据,我将把一大块数据读入缓冲区,做任何需要它,然后将其写入输出.
#include <stdio.h>
#include <stdlib.h>
typedef struct header
{
char chunk_id[4];
int chunk_size;
char format[4];
char subchunk1_id[4];
int subchunk1_size;
short int audio_format;
short int num_channels;
int sample_rate;
int byte_rate;
short int block_align;
short int bits_per_sample;
short int extra_param_size;
char subchunk2_id[4];
int subchunk2_size;
} header;
typedef struct header* header_p;
void scale_wav_file(char * input, float factor, int is_8bit)
{
FILE * infile = fopen(input, "rb");
FILE * outfile = fopen("outfile.wav", "wb");
int BUFSIZE = 4000, i, MAX_8BIT_AMP = 255, MAX_16BIT_AMP …推荐指数
解决办法
查看次数
开源FSK解码器库?
我正在寻找一个库或工具来解码wav文件中的FSK,例如来电显示.
目前使用与vpb-driver捆绑在一起的工具,用于通过debian/ubuntu提供的Voicetronix硬件.但这似乎有一个我正在尝试调试的错误 - 验证音频文件的第二个工具将是有用的.
我不是在寻找从调制解调器或其他硬件设备读取来电显示数据的无数工具 - 我需要纯软件.
推荐指数
解决办法
查看次数
用于读取音频文件的库
我想在线/现场处理音频,我不断从音频文件中读取音频样本,处理这些音频样本(例如应用一些效果),并将处理后的样本转发到音频输出设备,如声卡.输入文件有常见的格式,如wav,mp3,甚至ogg.
是否有类似于libav/ffmpeg的库可用于音频文件,它简化了各种音频格式的读取并为我提供了源源不断的原始音频样本?或者是为每种格式使用单个库的最佳解决方案?这些库应该是c/c ++和cross-plattform兼容的(Mac,Win,Linux,ARM).
编辑感谢您的所有答案.我已经评估了所有库并得出结论,最好只坚持使用libav/ffmpeg,因为大多数库都需要ffmpeg作为后端.
推荐指数
解决办法
查看次数
Android音频对wav文件的影响并保存
需求
Android在SD卡中打开一个.wav文件,播放它,添加一些效果(如回声,音高移等),保存文件有效.简单:(
我知道的
- 我可以使用Soundpool或MediaPlayer打开和播放文件.
- 我可以在使用两者时发挥一些效果.即对于Media Player我可以设置环境混响效果.使用SoundPool我可以设置播放速率,这有点像音高变换.我现在成功地实现了这些.
- 但是这个类中的任何一个都没有任何保存播放文件的方法.所以我只能玩,我无法保存音乐效果.
我想知道什么
- 除了MediaPlayer或SoundPool之外,还有其他感兴趣的类吗?没关系保存,你只要提一下课,我会做关于用它们保存文件的研究.
- 任何第三方库我可以添加效果并保存?如果它是开源和免费的,请高兴.但即使它是专有的,也要提及它们.
- 我可以研究的任何其他领域.OpenAL是否支持语音过滤和语音定位?它适用于Android吗?
准备做肮脏的工作.你请把路径借给我..
编辑:
做了一些搜索,并遇到了AudioTrack.但它也不支持保存到文件.所以那里也没有运气..编辑
好的,如果我自己做的怎么办?从wav文件中获取原始字节,并对其进行处理.我使用AudioRecord录制了一个wav文件,得到了一个wav文件.是否有任何资源描述低级音频处理(我的意思是在字节级别).编辑
好的赏金时间到了,我正在给予我得到的唯一答案赏金.7天后,我理解的是- 我们无法使用MediaPlayer,AudioTrack等保存我们播放的内容.
- 没有可用的音频处理库.
- 您可以获取原始的wav文件,并自己进行音频处理.答案为读/写wav文件提供了一个很好的包装类.一个好的java代码来读取和WAV文件的变化间距是在这里.
android soundpool audio-processing android-mediaplayer audioeffect
推荐指数
解决办法
查看次数
与R的音频比较
我正在一个项目中,我的任务涉及语音/音频/语音比较.该项目用于判断比赛中的获胜者(模仿).实际上我需要捕获用户的语音/语音并将其与原始音频文件进行比较并返回百分比匹配.我需要用R语言开发它.
我已经在R(tuneR,audio,seewave)中尝试过与语音相关的软件包,但在我的搜索中,我无法获得与比较相关的信息.
我需要你们的帮助,在那里,我可以找到与我的工作相关的信息,这是处理这类问题的最佳方法,如果有的话,处理这类音频相关工作的先决条件是什么.
推荐指数
解决办法
查看次数
查找音频文件中的音效
我加载了 3 小时的 MP3 文件,每大约 15 分钟就会播放一次独特的 1 秒音效,这标志着新章节的开始。
是否可以识别每次播放该音效的时间,以便我可以记录时间偏移?
每次的声音效果都相似,但由于它是以有损文件格式编码的,因此会有少量变化。
时间偏移将存储在ID3 章节帧元数据中。
示例 Source,其中声音效果播放两次。
ffmpeg -ss 0.9 -i source.mp3 -t 0.95 sample1.mp3 -acodec copy -y
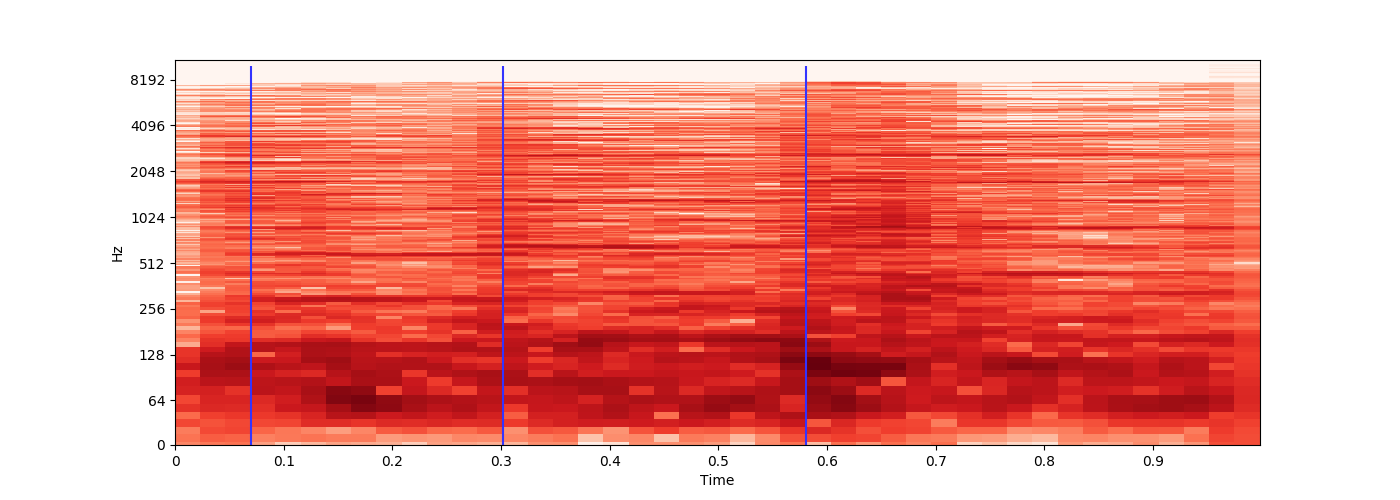{kind=link}
ffmpeg -ss 4.5 -i source.mp3 -t 0.95 sample2.mp3 -acodec copy -y
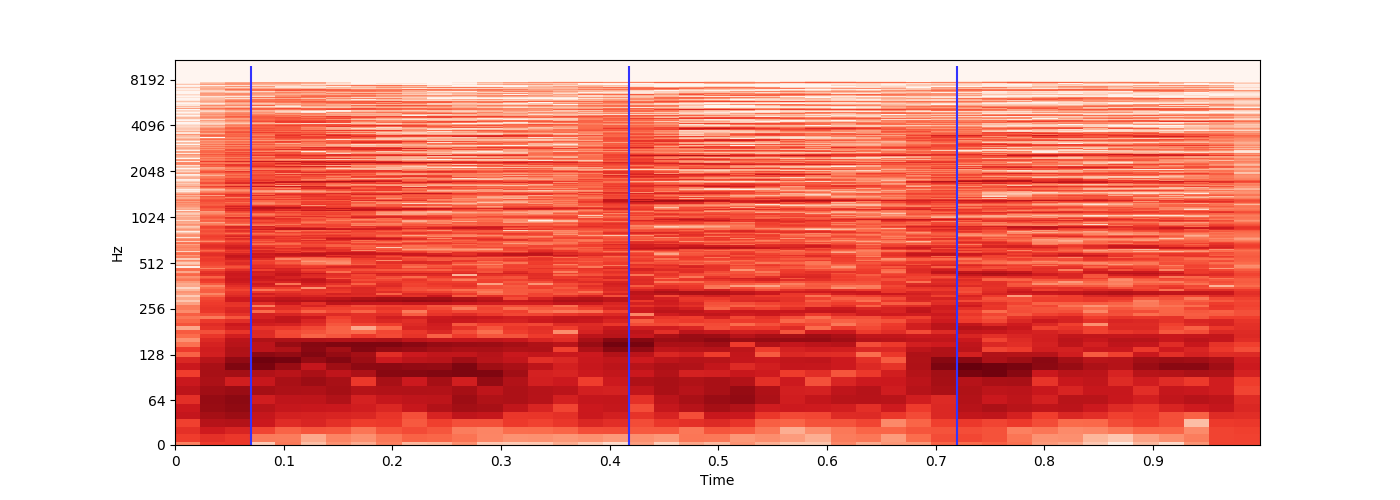{kind=link}
我对音频处理非常陌生,但我最初的想法是提取 1 秒音效的样本,然后librosa在 python 中使用来提取两个文件的浮点时间序列,对浮点数进行舍入,并尝试获取一场比赛。
import numpy
import librosa
print("Load files")
source_series, source_rate = librosa.load('source.mp3') # 3 hour file
sample_series, sample_rate = librosa.load('sample.mp3') # 1 second file
print("Round …推荐指数
解决办法
查看次数
如何使用MFCC系数向量训练机器学习算法?
对于我的最后一年项目,我试图实时识别狗/树皮/鸟的声音(通过录制声音片段).我使用MFCC作为音频功能.最初我使用jAudio库从声音片段中提取了12个MFCC向量.现在我正在尝试训练机器学习算法(目前我尚未确定算法,但它很可能是SVM).声音片段大小约为3秒.我需要澄清一些有关此过程的信息.他们是,
我是否必须使用基于帧的MFCC(每帧12个)或基于整个剪辑的MFCC(每个声音剪辑12个)训练此算法?
为了训练算法,我必须将所有12个MFCC视为12个不同的属性,还是必须将这12个MFCC视为一个属性?
这些MFCC是剪辑的整体MFCCS,
-9.598802712290967 -21.644963856237265 -7.405551798816725 -11.638107212413201 -19.441831623156144 -2.780967392843105 -0.5792847321137902 -13.14237288849559 -4.920408873192934 -2.7111507999281925 -7.336670942457227 2.4687330348335212
任何帮助将非常感谢克服这些问题.我无法在Google上找到很好的帮助.:)
signal-processing machine-learning audio-fingerprinting audio-processing mfcc
推荐指数
解决办法
查看次数
如何获取和解析ITune的EQ预设值
我们正在尝试使用均衡器预设来实现音乐播放器应用.我们成功地从iPod获取预设并通过音频单元应用它.但是,现在我们需要显示滑块并根据所选预设设置频率.但是我们不知道需要为特定频率设置滑块的值.
我们需要实现这种UI.滑块需要使用预设值更改进行更新.

提前致谢.
推荐指数
解决办法
查看次数
Swift 3 中的 AVAudioRecorder:获取字节流而不是保存到文件
我是 iOS 编程新手,我想使用 Swift 3 将 Android 应用程序移植到 iOS。该应用程序的核心功能是从麦克风读取字节流并实时处理该流。因此,将音频流存储到文件并在录音停止后对其进行处理是不够的。
我已经找到了可以工作的 AVAudioRecorder 类,但我不知道如何实时处理数据流(过滤、将其发送到服务器等)。AVAudioRecorder 的 init 函数如下所示:
AVAudioRecorder(url: filename, settings: settings)
我需要的是一个类,我可以在其中注册一个事件处理程序或类似的类,每次读取 x 个字节时都会调用该类,以便我可以处理它。
AVAudioRecorder 可以做到这一点吗?如果没有,Swift 库中是否还有另一个类可以让我实时处理音频流?在 Android 中我使用 android.media.AudioRecord 所以如果 Swift 中有一个等效的类那就太好了。
问候
推荐指数
解决办法
查看次数
使用前置摄像头录制视频时,分别获取视频和音频缓冲区
我在SO和一些不错的博客文章上挖了很多但似乎我有独特的要求分别阅读视频和音频缓冲区,以便在录制时继续进行处理.
我的用例就像当用户启动视频录制时,我需要使用连续处理视频帧ML-Face-Detection-Kit并连续处理音频帧以确保用户说出某些内容并检测噪声级别.为此,我想我需要一个单独的缓冲区中的视频和音频,并在处理后,我将合并它并保存到MP4文件中作为录制.
我尝试过由伟大的家伙Mattia Iavarone开发的CameraView,但它只提供视频帧.
我愿意接受其他有用的建议/反馈来处理这种情况.
android video-processing audio-processing android-camera2 firebase-mlkit
推荐指数
解决办法
查看次数