标签: assembly
使用GCC生成可读组件?
我想知道如何在我的C源文件中使用GCC来转储机器代码的助记符版本,以便我可以看到我的代码被编译成什么.您可以使用Java执行此操作,但我无法找到GCC的方法.
我试图在汇编中重新编写一个C方法,看看GCC是如何做的,这将是一个很大的帮助.
推荐指数
解决办法
查看次数
'switch'比'if'快吗?
是一种switch说法实际上比更快的if声明?
我使用/Ox标志在Visual Studio 2010的x64 C++编译器上运行下面的代码:
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
#define MAX_COUNT (1 << 29)
size_t counter = 0;
size_t testSwitch()
{
clock_t start = clock();
size_t i;
for (i = 0; i < MAX_COUNT; i++)
{
switch (counter % 4 + 1)
{
case 1: counter += 4; break;
case 2: counter += 3; break;
case 3: counter += 2; break;
case 4: counter += 1; break;
}
}
return …推荐指数
解决办法
查看次数
什么是retpoline?它是如何工作的?
为了减轻内核或跨进程内存泄露(Spectre攻击),Linux内核1将使用新选项进行编译,-mindirect-branch=thunk-extern引入以gcc通过所谓的retpoline执行间接调用.
这似乎是一个新发明的术语,因为Google搜索仅在最近的使用中出现(通常都是在2018年).
什么是retpoline?它如何防止最近的内核信息泄露攻击?
1然而,它不是特定于Linux的 - 类似或相同的构造似乎被用作其他操作系统的缓解策略的一部分.
推荐指数
解决办法
查看次数
多核汇编语言是什么样的?
曾几何时,为了编写x86汇编程序,你会得到一条说明"加载EDX寄存器的值为5","递增EDX"寄存器等的指令.
对于具有4个核心(甚至更多)的现代CPU,在机器代码级别上它看起来就像有4个独立的CPU(即只有4个不同的"EDX"寄存器)?如果是这样,当你说"递增EDX寄存器"时,是什么决定了哪个CPU的EDX寄存器递增?现在x86汇编程序中是否存在"CPU上下文"或"线程"概念?
核心之间的通信/同步如何工作?
如果您正在编写操作系统,那么通过硬件公开哪种机制可以让您在不同的内核上安排执行?这是一些特殊的特权指示吗?
如果您正在为多核CPU编写优化编译器/字节码VM,那么您需要具体了解x86,以使其生成能够在所有内核中高效运行的代码?
对x86机器代码进行了哪些更改以支持多核功能?
推荐指数
解决办法
查看次数
如何在没有操作系统的情况下运行程序?
如何在没有运行操作系统的情况下自行运行程序?你能创建计算机可以在启动时加载和运行的汇编程序,例如从闪存驱动器启动计算机并运行cpu上的程序吗?
推荐指数
解决办法
查看次数
是否可以"反编译"Windows .exe?或者至少查看大会?
我的一个朋友从Facebook下载了一些恶意软件,我很想知道它的作用而不会感染自己.我知道你不能真正反编译.exe,但我至少可以在Assembly中查看它或附加调试器吗?
编辑说它不是.NET可执行文件,没有CLI标头.
推荐指数
解决办法
查看次数
为什么引入无用的MOV指令会加速x86_64汇编中的紧凑循环?
背景:
在使用嵌入式汇编语言优化某些Pascal代码时,我注意到了一条不必要的MOV指令,并将其删除.
令我惊讶的是,删除不必要的指令会导致我的程序变慢.
我发现添加任意无用的MOV指令可以进一步提高性能.
效果不稳定,并且基于执行顺序进行更改:相同的垃圾指令向上或向下移动一行会产生减速.
我知道CPU会进行各种优化和精简,但这看起来更像是黑魔法.
数据:
我的代码版本有条件地在运行时间的循环中编译三个垃圾操作2**20==1048576.(周围的程序只计算SHA-256哈希值).
在我相当老的机器(英特尔(R)Core(TM)2 CPU 6400 @ 2.13 GHz)上的结果:
avg time (ms) with -dJUNKOPS: 1822.84 ms
avg time (ms) without: 1836.44 ms
程序在循环中运行25次,每次运行顺序随机变化.
摘抄:
{$asmmode intel}
procedure example_junkop_in_sha256;
var s1, t2 : uint32;
begin
// Here are parts of the SHA-256 algorithm, in Pascal:
// s0 {r10d} := ror(a, 2) xor ror(a, 13) xor …推荐指数
解决办法
查看次数
为什么不经常在汇编中编写程序?
似乎主流观点认为汇编编程需要更长时间并且比C等更高级别的语言更难编程.因此,似乎建议或假设出于这些原因更好地编写更高级别的语言并且为了更好的便携性.
最近我一直在写x86汇编,我突然意识到这些原因可能不是真的,除了可能的可移植性.也许这更多的是熟悉并且知道如何很好地编写装配.我还注意到汇编中的编程与HLL中的编程完全不同.也许一个优秀且经验丰富的汇编程序员可以像经验丰富的C程序员用C语言一样轻松快速地编写程序.
也许是因为汇编程序设计与HLL完全不同,因此需要不同的思维,方法和方法,这使得为不熟悉的程序编程看起来很尴尬,因此给它编写程序的坏名称.
如果可移植性不是问题,那么真的,C会对NASM这样的好汇编程序有什么影响?
编辑: 只是指出.在汇编时编写时,不必只是在指令代码中编写.您可以使用宏和过程以及您自己的约定来进行各种抽象,以使程序更加模块化,更易于维护和更易于阅读.这是熟悉如何编写良好汇编的地方.
推荐指数
解决办法
查看次数
汇编代码与机器代码对象代码?
目标代码,机器代码和汇编代码之间有什么区别?
你能举出他们差异的视觉例子吗?
推荐指数
解决办法
查看次数
什么是基本指针和堆栈指针?他们指出了什么?
使用来自维基百科的这个例子,其中DrawSquare()调用DrawLine(),
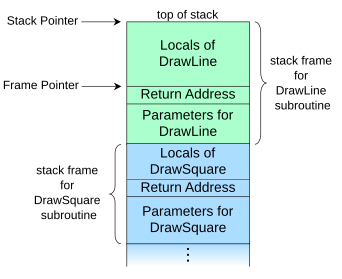
(请注意,此图表底部有高地址,顶部有低地址.)
任何人都可以解释我什么ebp,并esp在这方面?
从我看到的,我会说堆栈指针总是指向堆栈的顶部,而指针指向当前函数的开头?或者是什么?
编辑:我的意思是在Windows程序的上下文中
edit2:eip工作怎么样?
edit3:我有来自MSVC++的以下代码:
var_C= dword ptr -0Ch
var_8= dword ptr -8
var_4= dword ptr -4
hInstance= dword ptr 8
hPrevInstance= dword ptr 0Ch
lpCmdLine= dword ptr 10h
nShowCmd= dword ptr 14h
所有这些似乎都是dwords,因此每个都占用4个字节.所以我可以看到从hInstance到4个字节的var_4之间存在差距.这些是什么?我认为它是返回地址,可以在维基百科的图片中看到?
(编者注:从迈克尔的答案中删除了长篇引文,该答案不属于该问题,但编辑后续问题):
这是因为函数调用的流程是:
* Push parameters (hInstance, etc.)
* Call function, which pushes return address
* Push ebp
* Allocate space for locals
我的问题(最后,我希望!)现在是,从我想要调用到prolog结尾的函数的参数弹出的瞬间发生了什么?我想知道ebp,esp是如何在那些时刻发展的(我已经理解了prolog是如何工作的,我只是想知道在我将参数推到堆栈之后和prolog之前发生了什么).
推荐指数
解决办法
查看次数
标签 统计
assembly ×10
c ×4
x86 ×4
performance ×2
bootloader ×1
c++ ×1
cpu ×1
debugging ×1
decompiling ×1
freepascal ×1
gcc ×1
jump-table ×1
machine-code ×1
multicore ×1
object-code ×1
optimization ×1
osdev ×1
security ×1
smp ×1
winapi ×1
x86-64 ×1