标签: apache-spark-standalone
Spark Streaming - 已停止的工作程序抛出FileNotFoundException
我在由三个节点组成的集群上运行一个火花流应用程序,每个节点都有一个worker和三个执行器(所以总共有9个执行器).我正在使用spark独立模式(版本2.1.1).
应用程序使用带选项--deploy-mode client和的spark-submit命令运行--conf spark.streaming.stopGracefullyOnShutdown=true.submit命令从其中一个节点运行,我们称之为节点1.
作为容错测试,我通过调用脚本来停止节点2上的worker stop-slave.sh.
在节点2上的执行程序日志中,我可以看到在shuffle操作期间与FileNotFoundException相关的几个错误:
ERROR Executor: Exception in task 5.0 in stage 5531241.0 (TID 62488319)
java.io.FileNotFoundException: /opt/spark/spark-31c5b4b0-56e1-45d2-88dc-772b8712833f/executor-0bad0669-57fe-43f9-a77e-1b69cd284523/blockmgr-2aa295ac-78ca-4df6-ab89-51d422e8860e/1c/shuffle_2074211_5_0.index.ecb8e397-c3a3-4c1a-96ba-e153ed92b05c (No such file or directory)
at java.io.FileOutputStream.open(Native Method)
at java.io.FileOutputStream.<init>(FileOutputStream.java:206)
at java.io.FileOutputStream.<init>(FileOutputStream.java:156)
at org.apache.spark.shuffle.IndexShuffleBlockResolver.writeIndexFileAndCommit(IndexShuffleBlockResolver.scala:144)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:99)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
我可以在节点2上的3个执行程序中的每个执行程序中看到同一任务中的4种此类错误.
在驱动程序日志中我可以看到:
ERROR TaskSetManager: Task 5 in stage 5531241.0 failed 4 times; aborting job
...
ERROR JobScheduler: Error running job streaming job 1503995015000 ms.1
org.apache.spark.SparkException: …apache-spark spark-streaming apache-spark-standalone apache-spark-2.0
推荐指数
解决办法
查看次数
在独立模式下运行时,SparkUI 不显示选项卡(作业、阶段、存储、环境...)
我通过以下命令运行 Spark Master:
./sbin/start-master.sh
之后我去了http://localhost:8080,我看到了以下页面。
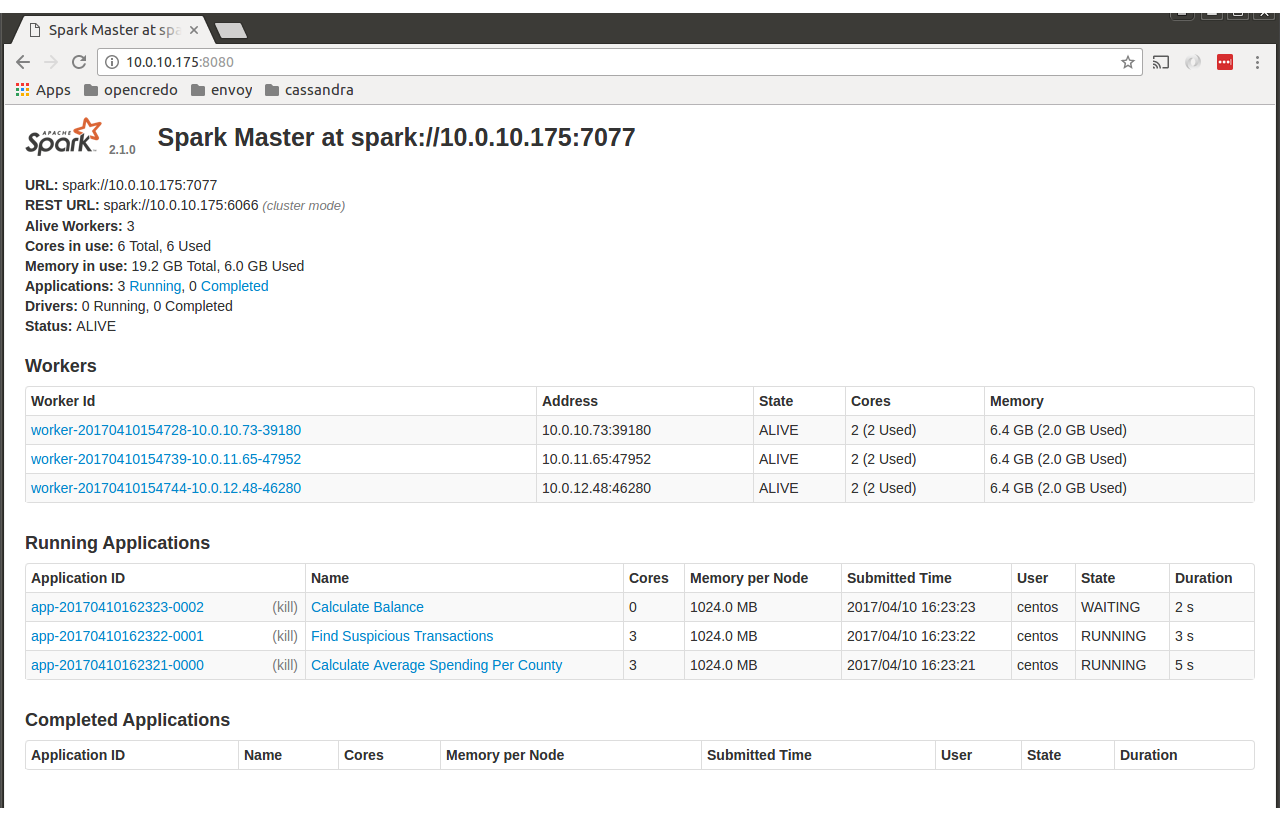
我期待看到包含“工作”、“环境”等的选项卡,如下所示
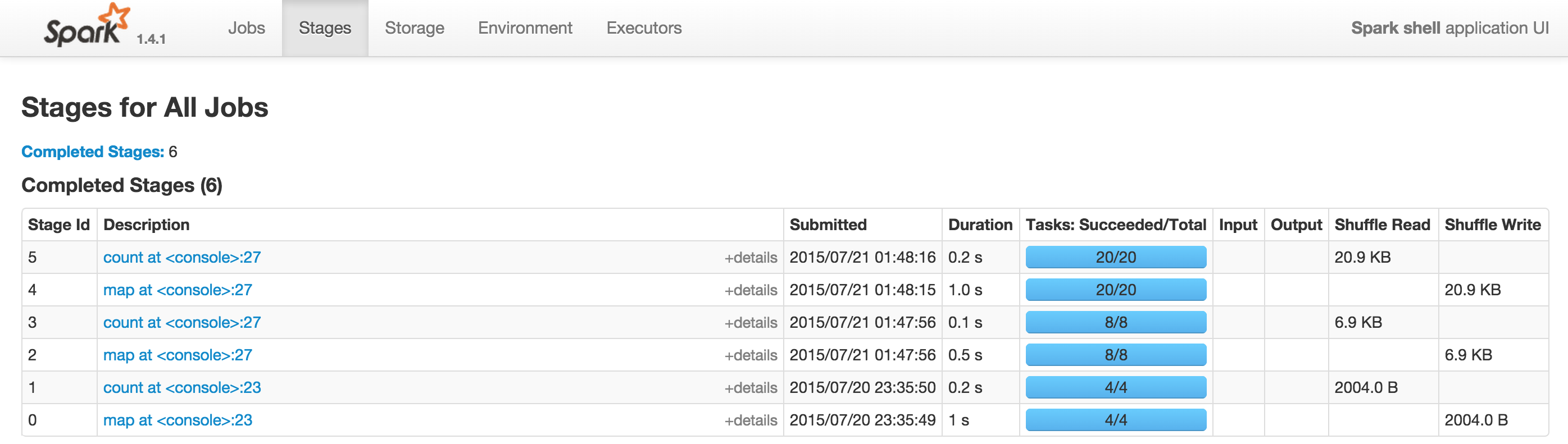
有人可以帮助我了解问题出在哪里吗?
我需要额外的配置吗?
谢谢
朱塞佩
推荐指数
解决办法
查看次数
成功创建 Spark 上下文后,Livy 会话一直停留在启动状态
我一直在尝试使用在 Ubuntu 18.04 上运行的 Livy 0.7 服务器创建一个新的 Spark 会话。在同一台机器上,我有一个正在运行的 Spark 集群,有 2 个工作人员,我可以创建一个正常的 Spark 会话。
我的问题是,在向 Livy 服务器运行以下请求后,会话停留在启动状态:
import json, pprint, requests, textwrap
host = 'http://localhost:8998'
data = {'kind': 'spark'}
headers = {'Content-Type': 'application/json'}
r = requests.post(host + '/sessions', data=json.dumps(data), headers=headers)
r.json()
我可以看到会话正在启动并从会话日志中创建了 Spark 会话:
20/06/03 13:52:31 INFO SparkEntries: Spark context finished initialization in 5197ms
20/06/03 13:52:31 INFO SparkEntries: Created Spark session.
20/06/03 13:52:46 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (xxx.xx.xx.xxx:1828) with ID 0
20/06/03 13:52:47 INFO BlockManagerMasterEndpoint: Registering block manager …推荐指数
解决办法
查看次数
从不同 Spark 版本访问 Spark-Shell
TL;DR:运行 Spark-Shell(驱动程序)的 Spark 是否绝对有必要具有与 Spark 主版本完全相同的版本?
我正在使用Spark 1.5.0通过 Spark-shell连接到Spark 1.5.0-cdh5.5.0 :
spark-shell --master spark://quickstart.cloudera:7077 --conf "spark.executor.memory=256m"
它可以很好地连接、实例化 SparkContext 和 sqlContext。如果我运行:
sqlContext.sql("show tables").show()
它按预期显示了我的所有表格。
但是,如果我尝试访问表中的数据:
sqlContext.sql("select * from t1").show()
我收到此错误:
java.io.InvalidClassException: org.apache.spark.sql.catalyst.expressions.AttributeReference; local class incompatible: stream classdesc serialVersionUID = 370695178000872136, local class serialVersionUID = -8877631944444173448
它说serialVersionUID不匹配。我的假设是问题是由于尝试连接两个不同版本的 Spark 引起的。如果我是对的,有什么想法吗?
apache-spark cloudera-cdh apache-spark-sql apache-spark-standalone
推荐指数
解决办法
查看次数
如何在特定节点上运行Spark作业
例如,我的 Spark 集群有 100 个节点(工作人员),当我运行一项作业时,我只想让它在大约 10 个特定节点上运行,我应该如何实现这一点。顺便说一句,我正在使用 Spark 独立模块。
为什么我需要上述要求:
One of my Spark job needs to access NFS, but there are only 10 nodes were
permitted to access NFS, so if the job was distributed on each Worker nodes(100 nodes),
then access deny exception would happen and the job would failed.
推荐指数
解决办法
查看次数
Spark流作业突然退出-收到的信号条款
应该连续运行的正在运行的Spark Streaming作业突然退出,并出现以下错误(在执行程序日志中找到):
2017-07-28 00:19:38,807 [SIGTERM handler] ERROR org.apache.spark.util.SignalUtils$$anonfun$registerLogger$1$$anonfun$apply$1 (SignalUtils.scala:43) - RECEIVED SIGNAL TERM
在收到此信号之前,火花流作业运行了约62小时。
我在执行程序日志中找不到其他任何错误/警告。不幸的是,我还没有设置驱动程序日志,因此我无法更深入地检查这个特定问题。
我在独立模式下使用Spark集群。
驾驶员为什么会发送此信号?(火花流运行良好且持续60多个小时后)
推荐指数
解决办法
查看次数
在Docker容器中运行Spark驱动程序-没有从执行程序到驱动程序的连接返回?
更新:问题已解决。Docker镜像在这里:docker-spark-submit
我在Docker容器中使用胖子运行spark-submit。我的独立Spark集群在3个虚拟机上运行-一个主服务器和两个工作服务器。从工作计算机上的执行程序日志中,我看到该执行程序具有以下驱动程序URL:
“ --driver-url”“ spark://CoarseGrainedScheduler@172.17.0.2:5001”
172.17.0.2实际上是具有驱动程序的容器的地址,而不是运行容器的主机。无法从工作计算机访问该IP,因此工作计算机无法与驱动程序通信。从StandaloneSchedulerBackend的源代码中可以看到,它使用spark.driver.host设置构建driverUrl:
val driverUrl = RpcEndpointAddress(
sc.conf.get("spark.driver.host"),
sc.conf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
它没有考虑SPARK_PUBLIC_DNS环境变量-这是正确的吗?在容器中,除容器“内部” IP地址(在此示例中为172.17.0.2)之外,我无法将spark.driver.host设置为其他任何内容。尝试将spark.driver.host设置为主机的IP地址时,出现如下错误:
WARN Utils:服务'sparkDriver'无法在端口5001上绑定。尝试使用端口5002。
我尝试将spark.driver.bindAddress设置为主机的IP地址,但是出现了相同的错误。那么,如何配置Spark使用主机IP地址而不是Docker容器地址与驱动程序通信?
UPD:来自执行程序的堆栈跟踪:
ERROR RpcOutboxMessage: Ask timeout before connecting successfully
Exception in thread "main" java.lang.reflect.UndeclaredThrowableException
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1713)
at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:66)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.run(CoarseGrainedExecutorBackend.scala:188)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.main(CoarseGrainedExecutorBackend.scala:284)
at org.apache.spark.executor.CoarseGrainedExecutorBackend.main(CoarseGrainedExecutorBackend.scala)
Caused by: org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36)
at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:216)
at scala.util.Try$.apply(Try.scala:192)
at scala.util.Failure.recover(Try.scala:216)
at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:326)
at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:326)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32)
at …推荐指数
解决办法
查看次数
为什么 Apache Livy 会话显示应用程序 ID 为 NULL?
我已经实现了一个功能齐全的 Spark 2.1.1 独立集群,其中我使用 Apache Livy 0.4 通过命令发布作业批次curl。当咨询 Spark WEB UI 时,我会看到我的作业及其应用程序 ID(类似这样:)app-20170803115145-0100、应用程序名称、核心、时间、状态等。但是当咨询 Livy WEB UI(http://localhost:8998 by默认),我看到以下结构:
| Batch Id | Application Id | State |
| -------- | -------------- | ------- |
| 219 | null | success |
| 220 | null | running |
如果我获取所有批次的状态,我将获得以下结果:
{
"from": 0,
"total": 17,
"sessions": [
{
"id": 219,
"state": "success",
"appId": null,
"appInfo": {
"driverLogUrl": null,
"sparkUiUrl": null
},
"log": ["* …推荐指数
解决办法
查看次数
PySpark:无法创建SparkSession。(Java网关错误)
我已经在Windows上安装了PySpark,直到昨天都没有问题。我使用windows 10,PySpark version 2.3.3(Pre-build version),java version "1.8.0_201"。昨天,当我尝试创建Spark会话时,遇到了以下错误。
Exception Traceback (most recent call last)
<ipython-input-2-a9ef4ac1a07d> in <module>
----> 1 spark = SparkSession.builder.appName("Hello").master("local").getOrCreate()
C:\spark-2.3.3-bin-hadoop2.7\python\pyspark\sql\session.py in getOrCreate(self)
171 for key, value in self._options.items():
172 sparkConf.set(key, value)
--> 173 sc = SparkContext.getOrCreate(sparkConf)
174 # This SparkContext may be an existing one.
175 for key, value in self._options.items():
C:\spark-2.3.3-bin-hadoop2.7\python\pyspark\context.py in getOrCreate(cls, conf)
361 with SparkContext._lock:
362 if SparkContext._active_spark_context is None:
--> 363 SparkContext(conf=conf or SparkConf())
364 return SparkContext._active_spark_context
365 …推荐指数
解决办法
查看次数
Spark Standalone VS YARN
对于仅运行 Spark 应用程序的多租户集群,YARN 的哪些功能使其优于 Spark Standalone 模式?也许除了身份验证。
谷歌有很多答案,其中很多对我来说听起来都是错误的,所以我不确定真相在哪里。
例如:
-
Standalone 适用于小型 Spark 集群,但不适用于大型集群(在集群节点中运行 Spark 守护进程 - master + slave - 存在开销)
但是其他集群管理器也需要在集群节点上运行代理。即 YARN 的奴隶被称为节点管理器。它们可能比 Spark 的 slave 消耗更多的内存(Spark 默认为 1 GB)。
Spark 独立模式要求每个应用程序在集群中的每个节点上运行一个执行器;而使用 YARN,您可以选择要使用的执行程序数量
再次使用Spark Standalone # executor/cores control,它展示了如何在 Standalone 模式下指定消耗的资源数量。
独立集群模式目前仅支持跨应用程序的简单 FIFO 调度程序。
与事实相反,独立模式可以使用动态分配,您可以指定spark.dynamicAllocation.minExecutors& spark.dynamicAllocation.maxExecutors。此外,我还没有发现有关 Standalone 不支持 FairScheduler 的说明。
YARN 直接处理机架和机器位置
YARN 如何知道我工作中的数据局部性?假设,我将文件位置存储在 AWS Glue(由 EMR 用作 Hive 元存储)。在 Spark 工作中,我正在查询some-db.some-table. YARN 如何知道哪种 …
resourcemanager hadoop-yarn apache-spark apache-spark-standalone
推荐指数
解决办法
查看次数
标签 统计
apache-spark ×10
livy ×2
cloudera-cdh ×1
docker ×1
hadoop ×1
hadoop-yarn ×1
java ×1
mesos ×1
pyspark ×1
spark-ui ×1
ubuntu ×1