我今天接受了采访.我有一个来自OOP的问题,关于Encapsulation&Abstraction之间的区别?
我回答她的知识,Encapsulation基本上是将数据成员和成员函数绑定到一个名为Class的单元中.而抽象基本上是为了隐藏实现的复杂性并提供对用户的轻松访问.我觉得她的回答会很好.但她问道,如果两者的目的都是隐藏信息,那么这两者之间的实际区别是什么?我不能给她任何答案.
在提出这个问题之前,我在StackOverFlow上阅读了关于这两个OOP概念之间差异的其他线程.但我并没有发现自己有能力说服采访者.
任何人都可以用最简单的例子来证明它的合理性吗?
考虑面向对象的语言:
大多数人来自面向对象的编程背景,熟悉各种语言中常见且直观的界面,这些界面捕获了Java Collection和List界面的本质.Collection"对象"是指不一定具有自然排序/索引的对象集合.A List是具有自然排序/索引的集合.这些接口在Java中抽象了许多库数据结构,其他语言中的等效接口也是如此,并且需要对这些接口有深入的了解才能有效地与大多数库数据结构一起工作.
过渡到Haskell:
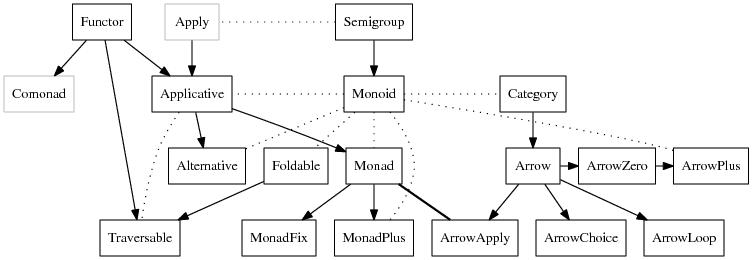
Haskell有一个类型级系统,它类似于对象上的接口作用于类型.当类型考虑功能时,Haskell似乎有一个关于Functors,Applicative,Monads等的设计良好的类型层次结构.他们显然想要正确且抽象良好的类型类.然而,当你看很多Haskell的容器(List,Map,Sequence,Set,Vector)他们几乎都具有非常相似(或相同)的功能,但通过类型类不是抽象的.
一些例子:
null 用于测试"空虚"length/size用于元素计数elem/member用于设置包含empty 和/或 singleton默认构造union 为集合联盟(\\)/diff用于设定差异(!)/(!!)用于不安全的索引(部分功能)(!?)/lookup用于安全索引(总功能)如果我想使用上面的任何函数,但是我已经导入了两个或更多个容器,我必须从导入的模块中开始隐藏函数,或者只从模块中显式导入必要的函数,或者限定导入的模块.但由于所有功能都提供相同的逻辑功能,因此它似乎很麻烦.如果函数是从类型类定义的,而不是在每个模块中单独定义的,那么编译器的类型推理机制可以解决这个问题.只要它们共享类型类,它也会使底层容器切换变得简单(即:让我们只使用一个Sequence而不是List更好的随机访问效率).
为什么Haskell没有Collection和/或Indexable类型类来统一和概括其中的一些功能?
为什么我应该使用人类可读的文件格式而不是二进制格式?有不是这种情况的情况吗?
编辑:我在最初发布问题时确实有这个作为解释,但现在不太相关:
在回答这个问题时,我想让提问者参考一个标准的答案,解答为什么使用人类可读的文件格式是一个好主意.然后我搜索了一个,找不到一个.所以这就是问题所在
在采访中,我被要求解释抽象和封装之间的区别.我的答案一直是这样的
抽象使我们能够以最简单的方式表现复杂的现实世界.它是识别对象应具备的相关品质和行为的过程; 换句话说,表示必要的特征而不表示背景细节.
封装是将对象的所有内部细节隐藏在外部现实世界中的过程."封装"一词,就像"封闭"成"胶囊".它限制客户端看到其实现抽象行为的内部视图.
我认为通过上面的回答,面试官确信,但后来我被问到,如果两者的目的都隐藏了,那么为什么需要使用封装.那时候我没有一个好的答案.
我应该添加什么来使我的答案更完整?
在搜索差异时,我发现了这些定义:
编译是获取用一种语言编写的源代码并转换为另一种语言的通用术语.
Transpiling是一个特定的术语,用于获取用一种语言编写的源代码,并转换为另一种具有相似抽象级别的语言.
我理解抽象是什么.
但是,在上述定义中,"相似的抽象级别"是什么意思呢?我们如何找到语言中的抽象级别?
我有一个对象,它将一些数据存储在列表中.实现可能会在以后更改,我不希望将内部实现公开给最终用户.但是,用户必须能够修改和访问此数据集.目前我有这样的事情:
public List<SomeDataType> getData() {
return this.data;
}
public void setData(List<SomeDataType> data) {
this.data = data;
}
这是否意味着我已经允许内部实现细节泄漏?我应该这样做吗?
public Collection<SomeDataType> getData() {
return this.data;
}
public void setData(Collection<SomeDataType> data) {
this.data = new ArrayList<SomeDataType>(data);
}
引用"间接水平解决每个问题"的含义在计算机科学中意味着什么?
我最近参加了一次采访,他们问我"为什么接口比抽象类更受欢迎?"
我尝试给出一些答案,如:
他们让我带走你使用的任何JDBC api."为什么他们是接口?".
我可以为此得到更好的答案吗?
我知道抽象是关于采取更具体的东西并使其更抽象.这可能是数据结构或过程.例如:
map是对过程的抽象,该过程对值列表执行一组操作以产生全新的值列表.它集中在这样一个事实,即程序遍历列表中的每个项目以生成新列表并忽略对列表中每个项目执行的实际操作.所以我的问题是:抽象与泛化有什么不同?我正在寻找主要与函数式编程相关的答案.但是,如果在面向对象编程中有相似之处,那么我也想了解它们.
oop abstraction functional-programming nomenclature generalization
我是第一次做大项目.我有很多类,其中一些有公共变量,一些有setter和getter方法的私有变量,同样有两种类型.
我决定重写此代码,主要只使用一种类型.但我不知道应该使用哪个(仅用于同一对象中的方法的变量始终是私有的,并且不受此问题的影响).
我知道公共和私人意味着什么,但在现实世界中使用什么以及为什么?
abstraction ×10
oop ×5
java ×2
binary ×1
c++ ×1
collections ×1
data-access ×1
encoding ×1
file ×1
formatting ×1
haskell ×1
indirection ×1
interface ×1
list ×1
nomenclature ×1
transpiler ×1
typeclass ×1
{kind=link}