相关疑难解决方法(0)
用JS解析HTML字符串
我搜索了一个解决方案,但没有任何相关性,所以这是我的问题:
我想解析一个包含HTML文本的字符串.我想用JavaScript做.
我试过这个库,但它似乎解析了我当前页面的HTML,而不是字符串.因为当我尝试下面的代码时,它会更改我的页面标题:
var parser = new HTMLtoDOM("<html><head><title>titleTest</title></head><body><a href='test0'>test01</a><a href='test1'>test02</a><a href='test2'>test03</a></body></html>", document);
我的目标是从HTML外部页面中提取链接,就像字符串一样.
你知道一个API来做吗?
推荐指数
解决办法
查看次数
正则表达式匹配任何字符,包括新行
是否有正则表达式匹配"包括换行符在内的所有字符"?
例如,在下面的正则表达式中,没有输出,$2因为(.+?)匹配时不包括新行.
$string = "START Curabitur mollis, dolor ut rutrum consequat, arcu nisl ultrices diam, adipiscing aliquam ipsum metus id velit. Aenean vestibulum gravida felis, quis bibendum nisl euismod ut.
Nunc at orci sed quam pharetra congue. Nulla a justo vitae diam eleifend dictum. Maecenas egestas ipsum elementum dui sollicitudin tempus. Donec bibendum cursus nisi, vitae convallis ante ornare a. Curabitur libero lorem, semper sit amet cursus at, cursus id purus. Cras varius metus eu diam …推荐指数
解决办法
查看次数
参考 - 这个正则表达式意味着什么?
推荐指数
解决办法
查看次数
从纯文本中解析包含换行符的项目符号
我正在尝试解析包含多个项目符号的文本文档.
我想解析具有单个换行符的子弹点,但是当找到2个或更多换行符时想要中断.
for example :
-----------------------------------
* bullet
text on new line
more text
this should be a separate block
-----------------------------------
when passed through the function, this should capture :
-----------------------------------
-> start
bullet
text on new line
more text
<- end capture
this should be a seperate block
-----------------------------------
这是我到目前为止,我已经编写了一个javascript函数,可以递归地解析有序/无序的mediawiki'sh列表到HTML.唯一不同的是,块在2个换行符上插入,而对于1个换行符的mediawiki方式.
function parseLists(str)
{
//How can I capture bulleted lines with less than or equal to "1" newline character?
return str.replace(/(?:(?:(?:^|\n)[\*#].*)+)/g, function (match) {
var listType = match.match(/(^|\n)#/) ? 'ol' …推荐指数
解决办法
查看次数
如何删除两个特定字符之间的子字符串
所以我有一个字符串:
"this is the beginning, this is what i want to remove/ and this is the end"
如何使用Javascript来定位逗号和正斜杠之间的字符串?(我也想删除逗号和斜杠)
推荐指数
解决办法
查看次数
如何使用正则表达式查找多行 JavaScript 注释块?
我正在尝试从 JavaScript 文件中提取代码注释块。我正在制作一个轻量级的代码文档。
一个例子是:
/** @Method: setSize
* @Description: setSize DESCRIPTION
* @param: setSize PARAMETER
*/
我需要像这样拉出评论设置,最好是放到一个数组中。
我已经做到了这一点,但意识到它可能无法处理新行标签等:
\/\*\*(.*?)\*\/
(好吧,这看起来很简单,但我正在绕圈子试图让它工作。)
推荐指数
解决办法
查看次数
为什么这个正则表达式不起作用?
这是正则表达式: /<\?nib.+\?>/im
我在这样的文件上测试它:
<html>
<head>
<title>OPEN LARK</title>
</head>
<body>
<h1>THIS IS A HEADER
<?nib
asdf
?>
</h1>
</body>
</html>
我没有比赛.我怎样才能解决这个问题?
推荐指数
解决办法
查看次数
正则表达式跨多行捕获两个标记之间的所有内容
我在Ruby中有这个正则表达式:http://rubular.com/r/eu9LOQxfTj
/<sometag>(.*?)<\/sometag>/im
它成功匹配输入如下:
<sometag>
123
456
</sometag>
哪会回来
123
456
但是,当我在javascript(在chrome中测试)中尝试此操作时,它与任何内容都不匹配.javascript的多行标志是否意味着别的什么?
我想在两个给定标签之间非贪婪地捕获所有内容.如何使用正则表达式在javascript中完成此操作?这是一个Debuggex演示
<sometag>(.*?)<\/sometag>
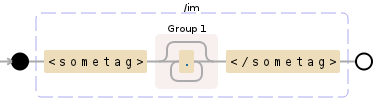
这不是XML解析.
推荐指数
解决办法
查看次数