相关疑难解决方法(0)
查找有向图中的所有循环
如何从有向图中找到(迭代)有向图中的所有周期?
例如,我想要这样的东西:
A->B->A
A->B->C->A
但不是:B-> C-> B.
推荐指数
解决办法
查看次数
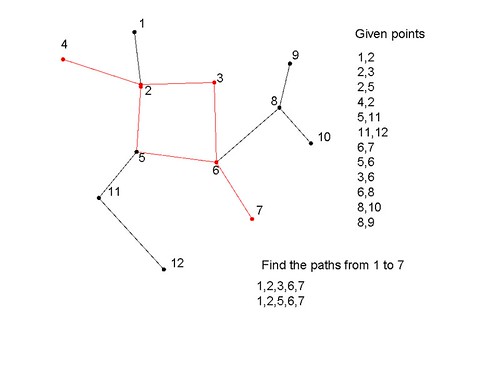
找到两个给定节点之间的路径?
假设我以下面的方式连接节点,我如何得出给定点之间存在的路径数量和路径详细信息?
1,2 //node 1 and 2 are connected
2,3
2,5
4,2
5,11
11,12
6,7
5,6
3,6
6,8
8,10
8,9
找到1到7的路径:
答案:找到2条路径,它们是
1,2,3,6,7
1,2,5,6,7
在这里找到的实现很好,我将使用相同的
这是python中上面链接的片段
# a sample graph
graph = {'A': ['B', 'C','E'],
'B': ['A','C', 'D'],
'C': ['D'],
'D': ['C'],
'E': ['F','D'],
'F': ['C']}
class MyQUEUE: # just an implementation of a queue
def __init__(self):
self.holder = []
def enqueue(self,val):
self.holder.append(val)
def dequeue(self):
val = None
try:
val = self.holder[0]
if len(self.holder) == 1:
self.holder = [] …推荐指数
解决办法
查看次数
找到从A到Z的所有路径的高效算法?
使用一组这样的随机输入(20k行):
A B
U Z
B A
A C
Z A
K Z
A Q
D A
U K
P U
U P
B Y
Y R
Y U
C R
R Q
A D
Q Z
找到从A到Z的所有路径.
- A - B - Y - R - Q - Z.
- A - B - Y - U - Z.
- A - C - R - Q - Z.
- A - Q - Z.
- A - B - Y - …
推荐指数
解决办法
查看次数
用于在有向图中找到不同路径的数量的算法
可能重复:
图算法查找两个任意顶点之间的所有连接
我有一个有向图,我可以使用什么算法来查找2个特定顶点之间的不同非循环路径的数量,并计算在这些不同路径中使用任何路径的最大次数?如果它们访问不同数量的顶点或以不同的顺序访问顶点,则两条路径是不同的.
推荐指数
解决办法
查看次数
在大型网格中路由路径的最佳方法是什么?
我正在研究一种算法,在给定的一对点的网格中找到一组非相交路径.对于这些对,这样:(9,4)和(12,13)

输出应该是这样的:
9,10,11,7,3,4
13,14,15,16,12
如果无法路由所有路径,则打印"已阻止"
首先,我搜索了一个已经制作的算法,以找到图形或网格中2个点之间的所有简单路径.我在@Casey Watson和@svick 这里找到了这个..它的效果非常好,但仅适用于小图.
我将它转换为C#.NET并对其进行了一些增强,以便能够找到最大长度为X的路径.并在其上构建我的总算法.
我建的那个在小图中工作得很好..这是8x8网格中的9对路线..

但它需要花费大量时间在较大的像16x16甚至是我打算做的最后一个,这是一个16x16x2的3D模型像这样

该算法被开发为深度优先搜索RECURSIVE算法,但是花费了大量时间将值返回给用户.所以我决定将它转换为循环而不是递归调用,以便我可以从.NET中的yield return功能中受益,但它仍然没有任何帮助.
算法的循环版本在不到一秒的时间内找到一对点的路径,但递归的路径花费超过90秒.

当我尝试使用2对时,循环版本需要大约342秒,但递归版需要大约200秒.

所以我不知道哪个更快..!?递归或循环一个..
我真的想知道这样做的最好方法..
注意:节点编号中的第一个数字确定图层(从1开始).
这是代码
using System;
using System.Collections;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
namespace AlgorithmTest
{
struct Connection
{
public int FirstNode;
public int SecondNode;
public Connection(int N1,int N2)
{
FirstNode = N1;
SecondNode = N2;
}
}
enum Algorithm
{ Recursion, Loops }
public class Search
{
private const int MAX = 15;
private const int …推荐指数
解决办法
查看次数
两个节点之间所有路径的速度非常快
我是python编码的新手,我正在寻找一种算法,可以快速找到一个非常大的图形的起始节点和结束节点之间的所有路径 - 比如一个有大约1000个节点和10,000个边缘的图形.从起始节点到结束节点实际存在的路径数很少 - 十个或更少.为了帮助提高问题的背景,考虑一个社交网络 - 如果我有1000个朋友,我想知道我的高中朋友有多少方式从大学连接到我的室友,我不关心我的事实高中最好的朋友与我所有的200名高中朋友联系在一起,因为那些路径从未通向我的室友.我想用这个python代码做的很快就是我的两个朋友之间存在的路径的子集,并且基本上摆脱了这两个节点周围存在的所有"噪音".
我试图实现一些代码示例,所有这些代码都适用于小而简单的图形.但是,当我尝试将它们纳入我的大图分析时,它们都需要很长时间才能发挥作用.
你们都有任何调查方法的建议(即已经在networkx中创建的东西,甚至是使用堆栈与递归的信息等等),要实现的代码示例,甚至是python之外的其他路径来追求?请记住,我是一个蟒蛇新手.
推荐指数
解决办法
查看次数
Jackrabbit搜索加入的节点
我在Jackrabbit存储库中标记了对象(实际上是Adobe/Day CQ的CRX,但我认为这是Jackrabbit代码):
- asset:tags = A,B
- 子资产数据1:tags = A,C,E
- 子资产数据2:tags = D,E
我想查询父资产的标签集和一个子集的并集,即"BC"与资产匹配,因为我们在父节点和子节点1中有,但"CD"不匹配,因为没有组合父项和一个匹配的子项,因为C和D在不同的子数据节点之间拆分.
有没有办法在Jackrabbit做到这一点?我们可以编写一个XPath查询
\\element(*, dam:Asset)[(@tags = 'C' or *\@tags='C')
and (@tags = 'D' or *\@tags='D')]
但这不起作用,因为XPath似乎并不保证*加入的子资产是相同的,即这意味着"任何孩子都有C/D",因此将匹配我的资产,因为1个以上的孩子有C和1+孩子们有一个D.相反,我可以使用JCR-SQL2
SELECT * FROM dam:Asset as asset
LEFT OUTER JOIN nt:unstructured as child ON ISCHILDNODE(child,asset)
WHERE (asset.tags = 'C' or child.tags = 'C')
AND (asset.tags = 'D' or child.tags = 'D')
但SELECT DISTINCT在JCR-SQL2中没有:如果我搜索"B E",我会将此资产返回两次,因为这会匹配asset + child1和asset + child2.
我可以在Java中对查询结果进行后处理,即筛选出第一种情况的误报匹配或者过滤掉第二种情况的重复结果,但是我很担心这会如何影响分页性能:我需要扫描更多节点比清除坏节点所需要的,我需要扫描批次以计算正确的分页结果大小.对于第二个SQL2案例,这应该更便宜,因为如果我的搜索是有序的,我可以单独根据节点路径发现重复,并且所有重复都是连续的,所以我只能通过便宜的扫描找到给定页面的数据,但希望无需阅读每个结果的整个节点,但我不知道扫描所有结果的分页计数的成本,即使对于简单的仅路径情况.
我们考虑的另一种选择是将标签非规范化为单个节点.在这种情况下,为了保持搜索准确,这必须意味着在每个子节点中创建一个新的combined_tags属性,并仅对该组子节点执行所有搜索.然而,如果我们匹配同一资产下的两个子节点,这仍然会遇到明显的问题.
谢谢你的任何建议.这已经是一个大型实例,需要进一步扩展.我已经看到其他问题,说ModeShape是一个JCR实现确实有,SELECT DISTINCT但我认为只是为了那个切换到ModeShape必须是最后的手段,如果确实可以在ModeShape上托管CQ.
我们现在提出的一个想法是计算资产标签和子标签的每个联合,并将标签组合成单个字符串,然后将每个值写为资产的多值属性,即asset + child1 ="ABC E"和资产+ child2 ="ABD …
推荐指数
解决办法
查看次数
使用深度优先搜索找到所有简单路径的复杂性?
感谢大家回复想法和替代解决方案.总是欢迎更有效的解决问题的方法,以及提醒我质疑我的假设.也就是说,我希望你暂时忽略我试图通过算法解决的问题,并且只是帮助我分析我编写的算法的大复杂性 - 一个简单的路径在曲线图使用深度限制搜索所描述这里,和实施这里.谢谢!
编辑:这是作业,但我已经提交了这个作业,我只想知道我的答案是否正确.当涉及递归时,我对Big-O的复杂性感到有些困惑.
原始问题如下:
我试图找到这个算法给出的全路径搜索的复杂性.给定两个顶点,我使用深度优先搜索找到它们之间的所有简单路径.
我知道DFS的时间复杂度是O(V + E),它的空间复杂度是O(V),我的直觉是全路径搜索的复杂性将超过这个,但我无法确定它将是什么.
更新(回应下面的评论):
我正在努力解决凯文培根的六度问题.这通常需要找到一对演员之间的最低分离度,但我必须找到所有分离度(目前,小于6,但这可能会改变).
推荐指数
解决办法
查看次数
航班时刻表算法
我有一份所有直飞航班的清单.从这里我想得到从A到B的连接航班.这个问题的算法或数据结构是什么?谢谢.
推荐指数
解决办法
查看次数
查找2人之间的最大连接数
假设我有以下数据:
p1 <- c('a','a','a','a','a','b','b','b','b','c','c')
p2 <- c('b','c','d','e','f','c','a','e','d','e','f')
connections <- data.frame(p1, p2)
在哪里p1和p2在个人和每一行代表一个连接.
问题:如何编写一个函数来查找2个人之间的最大公共连接数?(例如a&b有3个共同连接:c,d,e)
推荐指数
解决办法
查看次数
标签 统计
algorithm ×6
graph ×4
graph-theory ×2
java ×2
python ×2
.net ×1
aem ×1
big-o ×1
c# ×1
crx ×1
jackrabbit ×1
jcr ×1
nodes ×1
path ×1
performance ×1
pseudocode ×1
r ×1