相关疑难解决方法(0)
混合声音的算法
我有两个原始声音流,我需要加在一起.出于这个问题的目的,我们可以假设它们具有相同的比特率和比特深度(例如16比特样本,44.1khz采样率).
显然,如果我只是将它们加在一起,我将溢出并下溢我的16位空间.如果我将它们加在一起并除以2,那么每个的体积减半,这是不正确的声音 - 如果两个人在一个房间里说话,他们的声音不会变得安静一半,麦克风可以选择它们两者都没有击中限制器.
- 那么在我的软件混音器中将这些声音组合在一起的正确方法是什么?
- 我错了,正确的方法是将每个的体积减少一半?
- 我是否需要添加压缩器/限制器或其他处理阶段以获得我正在尝试的音量和混音效果?
-亚当
推荐指数
解决办法
查看次数
给定一个音频流,找到一个门猛击(声压级计算?)
与拍手探测器不同("Clap on!clap clap Clap off!clap clap Clap on,clap off,Clapper! clap clap ")我需要检测门何时关闭.这是一辆车,比房间或家门更容易:
听:http://ubasics.com/so/van_driver_door_closing.wav
看:

它的采样速率为16位4khz,我希望避免大量处理或存储样本.
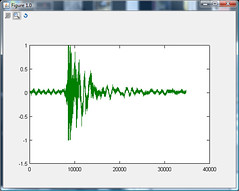
当您在大胆或其他波形工具中查看它时,它非常独特,并且由于车辆中声压的增加而几乎总是剪辑 - 即使窗户和其他门打开时:
听:http://ubasics.com/so/van_driverdoorclosing_slidingdoorsopen_windowsopen_engineon.wav
看:

我希望有一个相对简单的算法可以读取4kHz,8位的读数,并跟踪"稳态".当算法检测到声级显着增加时,它将标记该点.
- 你的想法是什么?
- 你怎么会发现这个事件?
- 声压级计算的代码示例是否有帮助?
- 我可以减少采样频率(1kHz甚至更慢?)
更新:使用Octave(开源数值分析 - 类似于Matlab)并查看均方根是否会给我我需要的东西(这导致与SPL非常相似的东西)
Update2:在简单的情况下,计算RMS可以轻松地关闭门:
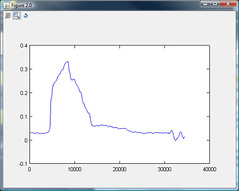
现在我只需要看看困难的情况(收音机,高温/高空等).CFAR看起来非常有趣 - 我知道我将不得不使用自适应算法,CFAR肯定符合要求.
-亚当
推荐指数
解决办法
查看次数
音频编程入门
我正在寻找为Windows音频构建一些压缩接口,我想知道是否有人可能知道一些提示/技巧?我想建立自己的软件均衡器,它将与整个Windows音频系统一起工作,而不仅仅是一个特定的程序.我知道这可以做到 - 我的声卡有一个内置,但没有足够的渠道来满足我的口味.
我对音频编程完全不熟悉,但我真的很想闯入它并弄脏我的手.如果您能想到任何教程/参考/文章/建议,我很乐意听到它们!
我正在使用Visual Studio C++ 2008.
推荐指数
解决办法
查看次数
检测基频
在印度的IIT-Bombay有这个技术节,在那里他们有一个名为"Artbots"的活动,我们应该设计具有艺术能力的艺术机器人.我有一个关于音乐机器人的想法,它以歌曲作为输入,检测歌曲中的音符并在钢琴上播放.我需要一些方法来帮助我计算歌曲音符的音高.关于如何去做的任何想法/建议?
推荐指数
解决办法
查看次数
我应该使用哪种算法进行信号(声音)一类分类?
更新此问题以前标题为" 给我一个简单的信号(声音)模式检测算法的名称 "
- 我的目标是在嘈杂的信号中检测给定模式的存在.我想检测一种用麦克风录制声音的昆虫种类.我以前用数字格式记录了昆虫的声音.
- 我不是想做语音识别.
- 我已经在输入信号和模式之间使用卷积来确定它们的相似性水平.但我认为这种技术更适合于离散时间(即数字通信,其中信号以固定间隔发生)并且在两个给定模式之间区分输入信号(我只有一种模式).
- 我害怕使用神经网络,因为我从来没有使用它们,我不知道我是否可以嵌入那些代码.
你能否指点一些其他的方法,或试着说服我,我目前的方法仍然是一个好主意或神经网络可能是一种可行的方式?
更新我已经有2个好的答案,但另一个会受到欢迎,甚至奖励.
algorithm audio pattern-recognition signal-processing pattern-matching
推荐指数
解决办法
查看次数