Linux内存管理中的RSS和VSZ是什么?在多线程环境中,如何管理和跟踪这两者?
linux
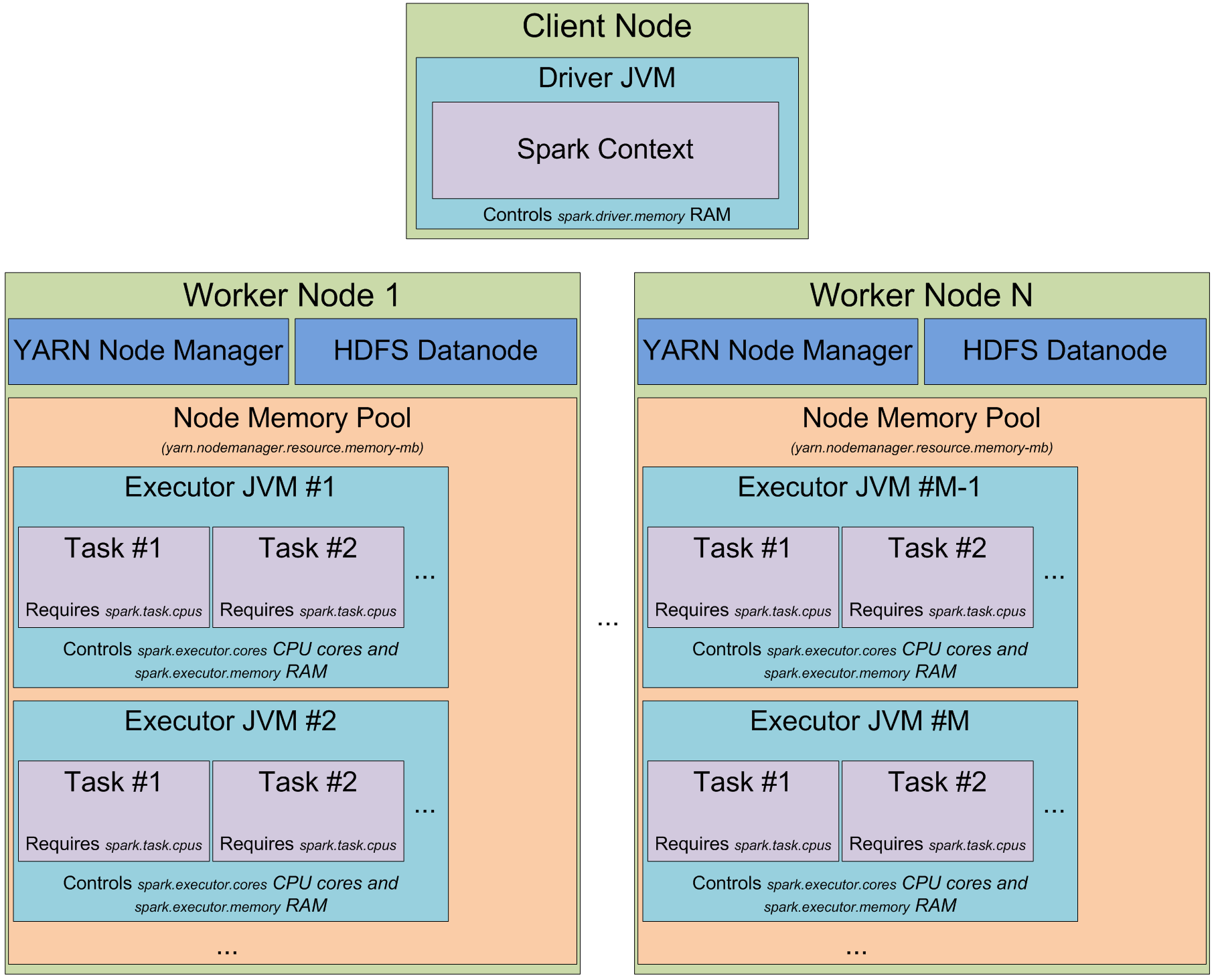
此图非常清楚不同的YARN和Spark内存相关设置之间的关系,除非它涉及到spark.python.worker.memory.
spark.python.worker.memory
如何spark.python.worker.memory适应这种记忆模型?
是Python的过程管辖spark.executor.memory或yarn.nodemanager.resource.memory-mb?
spark.executor.memory
yarn.nodemanager.resource.memory-mb
更新
此问题解释了设置的作用,但没有回答有关内存管理的问题,或者它与其他内存设置的关系.
memory hadoop-yarn apache-spark pyspark
apache-spark ×1
hadoop-yarn ×1
linux ×1
memory ×1
pyspark ×1
{kind=link}