在下面的方法定义,什么是*和**为做param2?
def foo(param1, *param2):
def bar(param1, **param2):
python syntax parameter-passing variadic-functions argument-unpacking
我有一个像这样的字符串列表:
X = ["a", "b", "c", "d", "e", "f", "g", "h", "i"]
Y = [ 0, 1, 1, 0, 1, 2, 2, 0, 1]
使用Y中的值对X进行排序以获得以下输出的最短方法是什么?
["a", "d", "h", "b", "c", "e", "i", "f", "g"]
具有相同"密钥"的元素的顺序无关紧要.我可以使用for构造,但我很好奇是否有更短的方法.有什么建议?
可能重复:
Python中的转置/解压缩功能
我有一个元组列表,我想将这个列表解压缩到两个独立的列表中.我正在寻找Python中的一些标准化操作.
>>> l = [(1,2), (3,4), (8,9)]
>>> f_xxx (l)
[ [1, 3, 8], [2, 4, 9] ]
我正在寻找一种简洁和pythonic的方法来实现这一目标.
基本上,我正在寻找zip()函数的逆运算.
可能重复:
Python中的转置/解压缩功能
我有一个如下所示的列表:
list = (('1','a'),('2','b'),('3','c'),('4','d'))
我想将列表分成2个列表.
list1 = ('1','2','3','4')
list2 = ('a','b','c','d')
我可以这样做:
list1 = []
list2 = []
for i in list:
list1.append(i[0])
list2.append(i[1])
但我想知道是否有更优雅的解决方案.
可能重复:
Python中的转置/解压缩功能
我使用numpy库中的zip()函数来排序元组,现在我有一个包含所有元组的列表.我已经修改了该列表,现在我想恢复元组,以便我可以使用我的数据.我怎样才能做到这一点?
我有一个对列表(a, b),我想matplotlib在python中作为实际的xy坐标绘制.目前,它正在制作两个图,其中列表的索引给出x坐标,第一个图的y值是a成对中的s,第二个图的y值是b成对中的s.
为了澄清,我的数据看起来像这样:li = [(a,b), (c,d), ... , (t, u)]
我想做一个只调用plt.plot()不正确的单线程.如果我不需要单行程,我可以琐碎地做:
xs = [x[0] for x in li]
ys = [x[1] for x in li]
plt.plot(xs, ys)
感谢您的帮助!
我有格式为token/tag的标记文件,我尝试了一个函数,它返回一个带有来自(word,tag)列表的单词的元组.
def text_from_tagged_ngram(ngram):
if type(ngram) == tuple:
return ngram[0]
return " ".join(zip(*ngram)[0]) # zip(*ngram)[0] returns a tuple with words from a (word,tag) list
在python 2.7中它运行良好,但在python 3.4中它给我以下错误:
return " ".join(list[zip(*ngram)[0]])
TypeError: 'zip' object is not subscriptable
有人可以帮忙吗?
我想编写一个代码来计算和求和任何正数和负数系列。
数字为正数或负数(无零)。
我用for循环编写了代码。有没有创意的替代品?
set.seed(100)
x <- round(rnorm(20, sd = 0.02), 3)
x = [-0.01, 0.003, -0.002, 0.018, 0.002, 0.006, -0.012, 0.014, -0.017, -0.007,
0.002, 0.002, -0.004, 0.015, 0.002, -0.001, -0.008, 0.01, -0.018, 0.046]
sign_indicator <- ifelse(x > 0, 1,-1)
number_of_sequence <- rep(NA, 20)
n <- 1
for (i in 2:20) {
if (sign_indicator[i] == sign_indicator[i - 1]) {
n <- n + 1
} else{
n <- 1
}
number_of_sequence[i] <- n
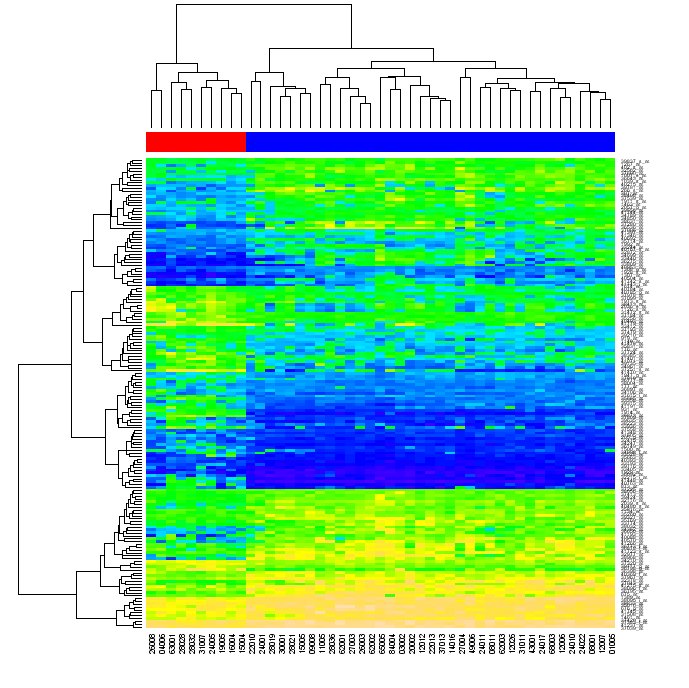
} …我正在寻找一种在矩阵行上分别执行聚类的方法,而不是在其列上,重新排序矩阵中的数据以反映聚类并将它们放在一起.聚类问题很容易解决,树形图创建也是如此(例如在本博客或"编程集体智慧"中).但是,如何重新排序数据仍然不清楚.
最后,我正在寻找一种使用朴素Python创建类似下图的方法(使用任何"标准"库,如numpy,matplotlib等,但不使用R或其他外部工具).
树形图http://www2.warwick.ac.uk/fac/sci/moac/currentstudents/peter_cock/r/heatmap/no_scaling.png
澄清
我被问到重新排序是什么意思.当您首先按矩阵行将数据聚类在矩阵中时,然后通过其列,每个矩阵单元可以通过两个树形图中的位置进行标识.如果对原始矩阵的行和列进行重新排序,使得在树形图中彼此靠近的元素在矩阵中彼此靠近,然后生成热图,则数据的聚类对于查看者来说可能变得明显(如上图所示)
我在元组中有一组点,如下所示:
>>> s
set([(209, 147),
(220, 177),
(222, 181),
(225, 185),
(288, 173),
(211, 155),
(222, 182)])
做这套散点图的正确方法是什么?
python ×10
list ×3
tuples ×3
matplotlib ×2
numpy ×2
coordinates ×1
plot ×1
python-3.x ×1
r ×1
scipy ×1
set ×1
sorting ×1
statistics ×1
syntax ×1
{kind=link}