计算ctr时如何避免印象偏差?
Tim*_*Tim 9 statistics ads machine-learning
当我们训练ctr(点击率)模型时,有时我们需要从历史数据中计算出真实的ctr,就像这样
#(click)
ctr = ----------------
#(impressions)
我们知道,如果展示次数太少,则计算的ctr不是真实的.因此,我们始终设置一个阈值来过滤掉足够大的展示次数.
但我们知道更高的印象,对中国的信心更高.然后我的问题是:是否有一个印象规范化的统计方法来计算ctr?
谢谢!
gre*_*ess 12
您可能需要为估计的ctr表示置信区间.威尔逊得分间隔是一个很好的尝试.
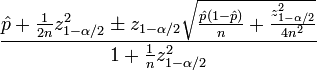
您需要以下统计数据来计算置信度分数:
\hat p是观察到的ctr(#clicked vs #impressions的分数)n是总展示次数zα/ 2是(1-?/2)标准正态分布的分位数
python中的一个简单实现如下所示,我使用z(1-α/ 2) = 1.96,它对应于95%的置信区间.我在代码的末尾添加了3个测试结果.
# clicks # impressions # conf interval
2 10 (0.07, 0.45)
20 100 (0.14, 0.27)
200 1000 (0.18, 0.22)
现在,您可以设置一些阈值以使用计算的置信区间.
from math import sqrt
def confidence(clicks, impressions):
n = impressions
if n == 0: return 0
z = 1.96 #1.96 -> 95% confidence
phat = float(clicks) / n
denorm = 1. + (z*z/n)
enum1 = phat + z*z/(2*n)
enum2 = z * sqrt(phat*(1-phat)/n + z*z/(4*n*n))
return (enum1-enum2)/denorm, (enum1+enum2)/denorm
def wilson(clicks, impressions):
if impressions == 0:
return 0
else:
return confidence(clicks, impressions)
if __name__ == '__main__':
print wilson(2,10)
print wilson(20,100)
print wilson(200,1000)
"""
--------------------
results:
(0.07048879557839793, 0.4518041980521754)
(0.14384999046998084, 0.27112660859398174)
(0.1805388068716823, 0.22099327100894336)
"""
- 实际上,我不确定我是否了解您想要什么以及为什么要那样做。贝叶斯估计量怎么样?或者像 IMDB 分数之类的东西?http://en.wikipedia.org/wiki/Bayes_estimator (2认同)
如果将此视为二项式参数,则可以进行贝叶斯估计。如果您的点击率先验是统一的(带有参数(1,1)的Beta分布),则您的后验就是Beta(1 +#click,1 +#impressions-#click)。如果您想要该后验的单个汇总统计信息,但您可能不希望这样做,则您的后验均值为#click + 1 /#impressions + 2,这就是为什么:
我不知道您用于确定点击率是否足够高的方法,但是假设您对点击率> 0.9的所有内容都感兴趣。然后,您可以使用beta分布的累积密度函数查看概率质量在0.9阈值之上的比例(这将是1-cdf在0.9)。这样,由于样本量有限,您的阈值自然会包含估计的不确定性。
| 归档时间: |
|
| 查看次数: |
3523 次 |
| 最近记录: |