hob*_*ave 21 mysql sql optimization derived-table query-optimization
更新:我找到了解决方案.请参阅下面的答案.
如何优化此查询以最大限度地减少停机时间?我需要更新50多个模式,门票数量从100,000到200万不等.是否可以尝试同时在tickets_extra中设置所有字段?我觉得这里有一个解决方案,我只是没有看到.我一直在打击这个问题超过一天.
另外,我最初尝试不使用子SELECT,但表现得太多比我现在有更坏.
我正在尝试优化我的数据库以获取需要运行的报告.我需要聚合的字段计算起来非常昂贵,因此我对现有模式进行了非规范化以适应此报告.请注意,通过删除几十个不相关的列,我简化了故障单表.
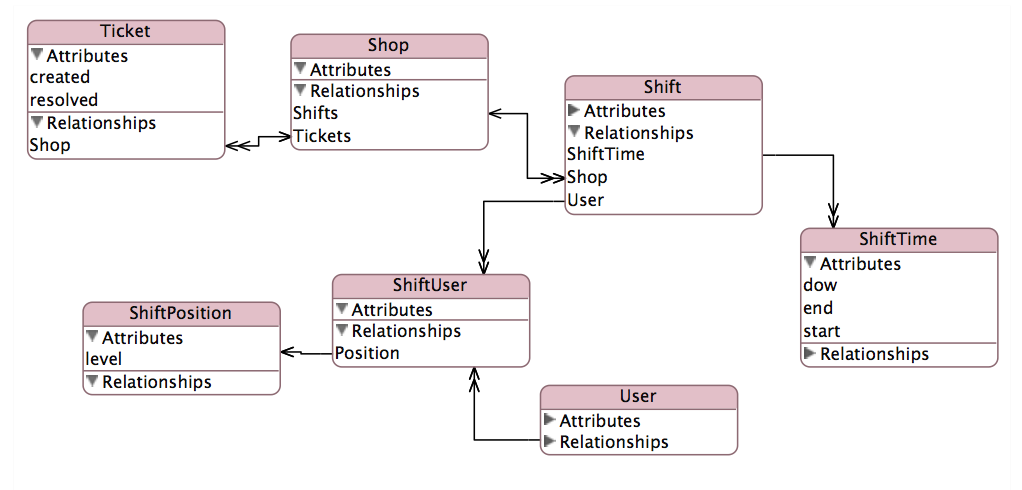
我的报告将按创建时管理器和解析后管理器聚合票证计数.这个复杂的关系如下图所示:
EAV http://cdn.cloudfiles.mosso.com/c163801/eav.png
为了避免在运行中计算这个需要的六个令人讨厌的连接,我已经将以下表添加到我的模式中:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
现在的问题是,我没有将这些数据存储在任何地方.经理总是动态计算.我在几个数据库中拥有数百万张票,这些数据库具有需要填充此表的相同模式.我希望以尽可能高效的方式执行此操作,但是在优化我正在使用的查询时未能成功:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
此查询需要一个多小时才能在具有> 170万票证的架构上运行.这对我的维护窗口来说是不可接受的.此外,它甚至不处理计算manager_resolved字段,因为尝试将其组合到同一查询中会将查询时间推入平流层.我目前的倾向是将它们分开,并使用UPDATE填充manager_resolved字段,但我不确定.
最后,这是该查询的SELECT部分的EXPLAIN输出:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
非常感谢您的阅读!
hob*_*ave 13
好吧,我找到了解决方案.这需要大量的实验,我认为这是一个很好的盲目运气,但这里是:
CREATE TABLE magic ENGINE=MEMORY
SELECT
s.shop_id AS shop_id,
s.id AS shift_id,
st.dow AS dow,
st.start AS start,
st.end AS end,
su.user_id AS manager_id
FROM shifts s
JOIN shift_times st ON s.id = st.shift_id
JOIN shifts_users su ON s.id = su.shift_id
JOIN shift_positions sp ON su.shift_position_id = sp.id AND sp.level = 1
ALTER TABLE magic ADD INDEX (shop_id, dow);
CREATE TABLE tickets_extra ENGINE=MyISAM
SELECT
t.id AS ticket_id,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.created) = m.dow
AND TIME(t.created) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_created,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.resolved) = m.dow
AND TIME(t.resolved) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_resolved
FROM tickets t;
DROP TABLE magic;
现在,我将解释为什么这样做,以及我的相对过程和步骤来到这里.
首先,我知道我正在尝试的查询因为巨大的派生表而受到影响,以及随后的JOIN到此.我正在使用我的索引良好的票证表并将所有shift_times数据加入其中,然后让MySQL在尝试加入shift和shift_positions表时咀嚼它.这个衍生出来的庞然大物将达到200万行无法估量的混乱.
现在,我知道这种情况正在发生.我之所以走这条路,是因为采用"JOINs"的"正确"方式,需要花费更长的时间.这是由于确定给定班次的经理是谁所需的一些混乱.我必须加入shift_times以找出正确的移位是什么,同时加入shift_positions以找出用户的等级.我不认为MySQL优化器能很好地处理这个问题,最终会创建一个临时连接表的巨大怪异,然后过滤掉不适用的内容.
所以,由于派生表似乎是"走的路",我顽固地坚持了一段时间.我试着把它变成一个JOIN条款,没有改进.我尝试使用派生表创建一个临时表,但是由于临时表没有索引,所以它太慢了.
我开始意识到我必须妥善处理这种转变,时间,位置的计算.我想,也许是一个VIEW将是要走的路.如果我创建了包含此信息的VIEW,该怎么办:( shop_id,shift_id,dow,start,end,manager_id).然后,我只需要通过shop_id和整个DAYOFWEEK/TIME计算加入门票表,我就会开展业务.当然,我没记得MySQL非常谨慎地处理VIEW.它根本没有实现它们,它只是运行您用来获取视图的查询.因此,通过加入门票,我基本上运行我的原始查询 - 没有改进.
因此,我决定使用TEMPORARY TABLE而不是VIEW.如果我一次只获取一个管理员(创建或解决),但这仍然很好.另外,我发现使用MySQL你不能在同一个查询中两次引用同一个表(我必须加入我的临时表两次才能区分manager_created和manager_resolved).这是一个很大的WTF,因为只要我没有指定"TEMPORARY"就能做到 - 这就是CREATE TABLE magic ENGINE = MEMORY的用武之地.
有了这个伪临时表,我尝试了另一个manager_created的JOIN.它表现不错,但仍然很慢.然而,当我再次加入以在同一查询中获得manager_resolved时,查询时间又回到了平流层.查看EXPLAIN显示了票据的全表扫描(行~2mln),如预期的那样,以及每个~2087的魔术表上的JOIN.再一次,我似乎陷入了失败.
我现在开始考虑如何完全避免JOINs,当我发现一些不起眼的古老留言板帖子时,有人建议使用子选择(在我的历史记录中找不到链接).这导致了上面显示的第二个SELECT查询(tickets_extra创建一个).在仅选择单个管理器字段的情况下,它表现良好,但同样两者都是垃圾.我查看了EXPLAIN并看到了这个:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 2. row ***************************
id: 3
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
3 rows in set (0.00 sec)
Ack,可怕的相关信息.通常建议避免这些,因为MySQL通常以外向的方式执行它们,为外部的每一行执行内部查询.我忽略了这一点,并想知道:"好吧......如果我只是将这个愚蠢的魔法表编入索引怎么办?" 因此,ADD指数(shop_id,dow)诞生了.
看一下这个:
mysql> CREATE TABLE magic ENGINE=MEMORY
<snip>
Query OK, 3220 rows affected (0.40 sec)
mysql> ALTER TABLE magic ADD INDEX (shop_id, dow);
Query OK, 3220 rows affected (0.02 sec)
mysql> CREATE TABLE tickets_extra ENGINE=MyISAM
<snip>
Query OK, 1933769 rows affected (24.18 sec)
mysql> drop table magic;
Query OK, 0 rows affected (0.00 sec)
现在THAT'S我对你说一下!
这绝对是我第一次动态创建非TEMPORARY表,并在运行中对其进行索引,只是为了有效地进行单个查询.我想我一直认为在运行中添加索引是一项非常昂贵的操作.(在我的票证表上添加2mln行的索引可能需要一个多小时).然而,仅仅3000行,这就是一个小路.
不要害怕相关的SUBQUERIES,创建真正没有的TEMPORARY表,即时索引或外星人.在适当的情况下,它们都可以成为好事.
感谢StackOverflow的所有帮助.:-D
{kind=link}