ASCII码的排序背后有什么逻辑吗?
我正在教我的弟弟学习工程学.我向他解释了不同的数据类型实际存储在内存中的方式.我向他解释了签名/无符号数字背后的物流和十进制数字的浮点位.当我告诉他C中的char类型时,我还带他通过ASCII代码系统,以及char也被存储为1字节数.
他问我为什么'A'被给予ascii代码65而不是其他什么?同样,为什么'a'具体代码为97?为什么在大写字母和小写字母之间存在6个ascii代码的差距?我不知道这个.你能帮助我理解这一点吗,因为这也给我带来了很大的好奇心.到目前为止,我从未找到任何讨论过该主题的书.
这背后的原因是什么?ASCII码是否逻辑组织?
FWH*_*FWH 71
有历史原因,主要是为了使ASCII码易于转换:
数字(0x30至0x39)具有二进制前缀110000:
0 is 110000
1 is 110001
2 is 110010
因此,如果你清除前缀(前两个'1'),你最终会得到二进制编码的十进制数字.
大写字母的二进制前缀为1000000:
A is 1000001
B is 1000010
C is 1000011
同样的,如果你删除前缀(第一个'1'),你最终会得到字母索引字符(A是1,Z是26等).
小写字母的二进制前缀为1100000:
a is 1100001
b is 1100010
c is 1100011
等同上.因此,如果您将32(100000)添加到大写字母,则您具有小写版本.
- 为什么'A'65而不是64?任何编码都有一定程度的逻辑和某种程度的随意性. (2认同)
- @JimBalter 抱歉,我应该打一个问号 - “因为他们希望字母表是 1 索引的?” 我在猜测。至于 65 是 1,这个答案说“大写字母的二进制前缀是 1000000”,即 64。所以如果你去掉这个前缀(减去 64),A 是 01(1),B 是 10(2),等等. (2认同)
Mes*_*esh 10
这个图表从维基百科中很好地显示:注意下面的上部2的控制2的两列,然后用misc填充间隙.
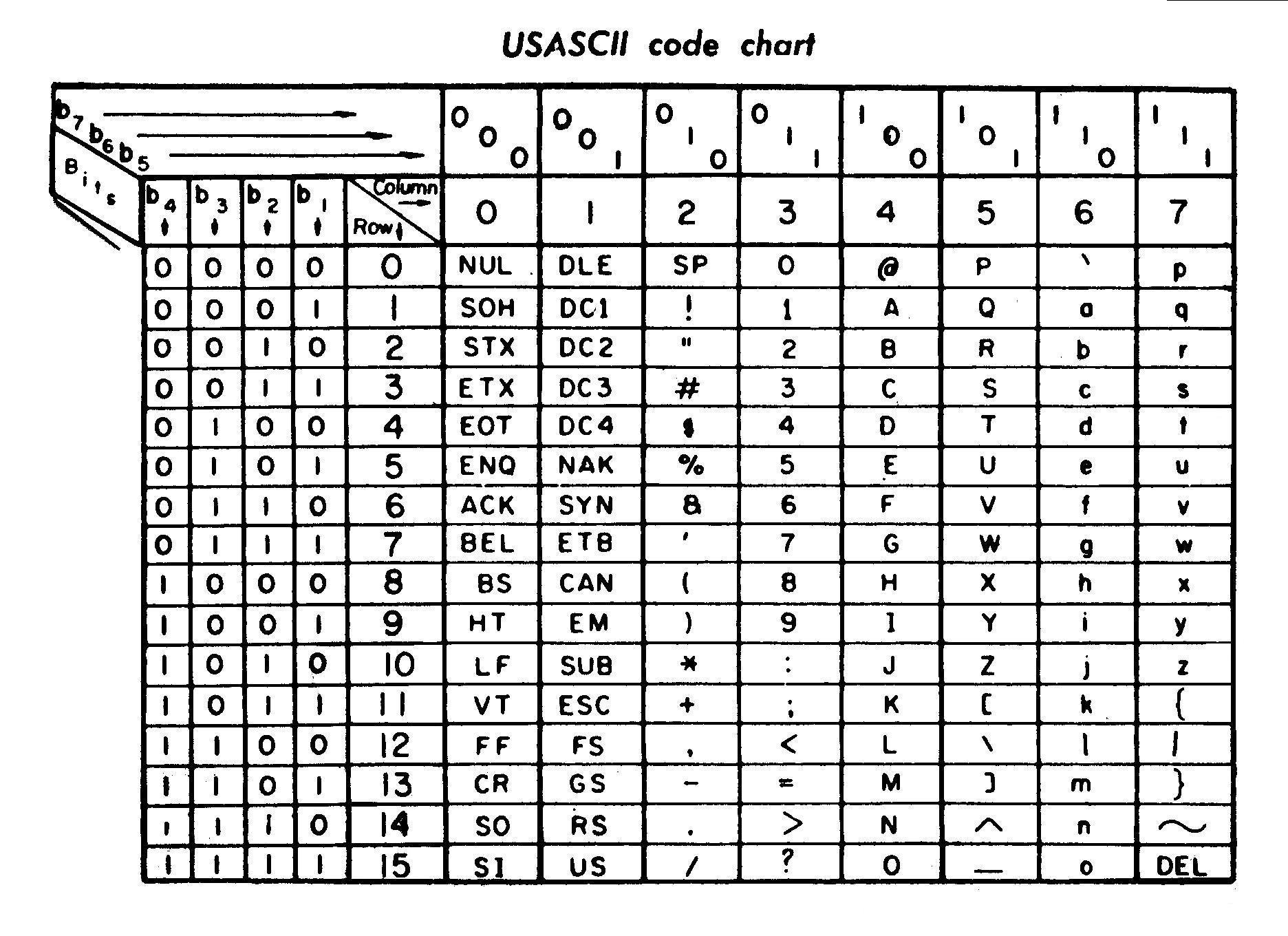
还要记住,ASCII是基于之前的过程开发的.有关ASCII历史的更多详细信息,请参阅Tom Jennings的这篇精彩文章,其中还包括一些陌生人控制角色的含义和用法.
以下是ASCII代码的非常详细的历史和描述:http://en.wikipedia.org/wiki/ASCII
简而言之:
- ASCII基于电传打字机编码标准
- 前30个字符是"不可打印的" - 用于文本格式
- 然后他们继续使用可打印的字符,大致是为了将它们放在键盘上.检查你的键盘:
- 空间,
- 数字上限的大写标志:!,",#,...,
- 数字
- 标志通常放在键盘行的末尾,带数字 - 大写字母
- 大写字母,按字母顺序
- 标志通常放在键盘行的末尾,带有字母 - 大写字母
- 小字母,按字母顺序排列
- 标志通常放在键盘行的末尾,带有字母 - 小写字母
A和之间的距离a是32.这是相当圆的数字,不是吗?
大写字母和小写字母之间的6个字符的间隙是因为(32 - 26)= 6.(注意:英文字母中有26个字母).
- 如果你对借来的词做出天真的假设,那么英文字母有26个字符. (3认同)
- 实际上,ï与我的字母相同,但带有变音符号.虽然英语借用了不少单词,但我认为它并没有借用像þ(冰岛语)或IJ(荷兰语)这样的字母. (2认同)