hhh*_*hhh 8 couchdb terminology mapreduce data-structures
我正在阅读O'Reilly CouchDB的书.我对第64页的reduce/re-reduce/incremental-MapReduce部分感到困惑.在O'Reilly的书中,有太多的东西留给了修辞版.
如果您有兴趣推动CouchDB的增量减少功能,请查看Google关于Sawzall的论文,......
如果我正确理解"增量"这个词,它指的是B树数据结构中的某种加法运算.我还不明白为什么它比典型的map-reduce有些特别,可能还没有理解它.在CouchDB中,它提到地图功能没有副作用 - 这是否也适用于减少?
为什么CouchDB中的MapReduce被称为"增量"?
小智 8
您链接的此页面对其进行了解释.
可以通过仅重新索引自上次索引更新以来已更改的文档来更新视图(这是CouchDB中映射reduce的整个点).这是增量部分.
这可以通过要求reduce函数是引用透明来实现,这意味着它总是返回给定输入的相同输出.
对于数组值输入,reduce函数也必须是可交换的和关联的,这意味着如果在同一个reducer的输出上运行reducer,您将收到相同的结果.在那个维基页面中,它表达如下:
f(Key, Values) == f(Key, [ f(Key, Values) ] )
Rereduce是从多个reducer调用中获取输出并再次通过reducer运行的地方.这有时是必需的,因为CouchDB通过减速器批量发送内容,因此有时并不是所有需要减少的密钥都会在一次性发送后发送.
为了略微添加user1087981所说的内容,reduce功能是增量的,因为CouchDB执行reduce过程的方式.
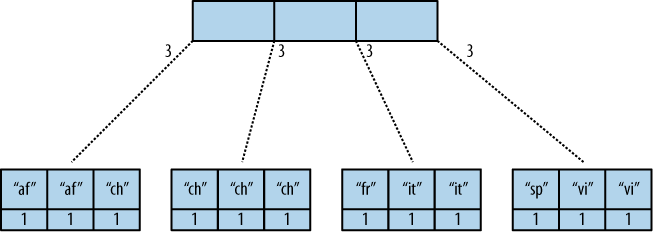
CouchDB使用它从视图函数创建的B树,实质上它在一堆值中执行reduce计算.这是O'Reilly指南中 B树的一个非常简单的模型,显示了您引用的部分中示例的叶节点.
减少B-tree http://guide.couchdb.org/draft/views/02.png
那么,为什么这种增量呢?好吧,最终的reduce只在查询时执行,所有reduce计算都存储在B-Tree视图索引中.因此,假设您向数据库添加一个新值,这是另一个"fr"值.上面第1,第2和第4个节点的计算不需要重做."fr"添加新值,仅为该第3叶节点重新计算reduce函数.
然后在查询时rereduce=true,对索引值执行final()计算,并返回最终值.您可以看到reduce的这种增量特性允许重新计算相对于添加的新值而不是现有数据集的大小所花费的时间.
没有副作用是这个过程的另一个重要部分.例如,如果您的reduce函数依赖于在遍历所有值时维护的其他某个状态,那么这可能适用于第一次运行,但是当添加新值并进行增量reduce计算时,它将不会没有相同的状态可用 - 因此无法获得正确的结果.这就是为什么reduce函数需要无副作用的原因,或者user1087981将其称为"引用透明"
{kind=link}