排序列表差异
use*_*579 6 language-agnostic algorithm comparison
我有以下问题.
我有一组元素,我可以通过某种算法A排序.分拣很好,但非常昂贵.
还有一个算法B可以近似A的结果.它更快,但排序不会完全相同.
将A的输出作为"黄金标准",我需要对在相同数据上使用B所导致的误差进行有意义的估计.
任何人都可以建议我可以看看解决我的问题的任何资源?提前致谢!
编辑:
根据要求:添加一个例子来说明这种情况:如果数据是字母表的前10个字母,
A输出:a,b,c,d,e,f,g,h,i,j
B输出:a,b,d,c,e,g,h,f,j,i
产生错误的可能措施是什么,这将允许我调整算法B的内部参数以使结果更接近A的输出?
斯皮尔曼的罗
我认为您想要的是Spearman的秩相关系数。使用两个排序(完美A和近似B)的索引[rank]向量,您可以计算出rho从-1(完全不同)到1(完全相同)的等级相关性:
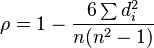
其中d(i)是A和B之间每个字符的等级差
您可以将误差的度量定义为距离D := (1-rho)/2。