正则表达式实现细节
如何在Python中实现正则表达式?那里有什么样的效率保证?实施是"标准",还是可以改变?
我认为正则表达式将作为DFA实现,因此非常有效(最多需要对输入字符串进行一次扫描).Laurence Gonsalves提出了一个有趣的观点,即并非所有Python正则表达式都是常规的.(他的例子是r"(a +)b\1",它匹配a的一些数量,ab,然后是与之前相同数量的a).使用DFA显然无法实现这一点.
那么,重申一下:Python正则表达式的实现细节和保证是什么?
如果有人可以给出某种解释(根据实现),为什么正则表达式"cat | catdog"和"catdog | cat"导致字符串"catdog"中的搜索结果不同,这也是很好的.在我之前提到的问题中提到过.
Unk*_*own 18
Python的re模块基于PCRE,但已经转移到他们自己的实现上.
这是C代码的链接.
当采用不正确的路径时,似乎库是基于递归回溯的.
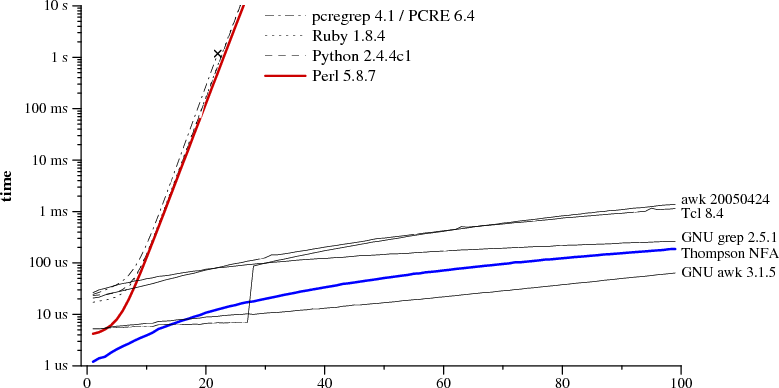
正则表达式和文本大小n
?n a n匹配n
请记住,此图表不代表正常的正则表达式搜索.
http://swtch.com/~rsc/regexp/regexp1.html
Python RE上没有任何"效率保证",而不是语言的任何其他部分(C++的标准库是我所知道的唯一广泛的语言标准,试图建立这样的标准 - 但是没有标准,即使在C++中,指定,比如说,乘以两个整数必须花费恒定的时间,或类似的东西); 也不保证任何时候都不会应用大的优化.
今天,F.Lundh(最初负责实现Python当前的RE模块等),在Pycon Italia上展示Unladen Swallow,他们提到他们将探索的一个途径是将正则表达式直接编译为LLVM中间代码(而不是他们的由ad-hoc运行时解释自己的字节码风格 - 因为普通的Python代码也被编译到LLVM(在即将发布的Unladen Swallow版本中),RE及其周围的Python代码可以一起优化,甚至有时甚至以非常激进的方式 我怀疑这样的事情很快就会接近"生产就绪",尽管如此;-).