数据存储浏览器建模
Dav*_*542 2 database relational-database hierarchical-data database-schema
我有一个连接对象浏览器,我希望允许用户查看他们连接到的各种数据源。对象的查看器看起来像这样:
连接:Remote.1234.MySQL(3级源)
- 数据库:销售
- 表:用户
- 字段:名称 -- CHAR(80)
- 字段:年龄 -- INT32
- 表:产品
- ...
- 表:购买
- ...
- 表:用户
- 数据库:其他
- ...
- 数据库:销售
连接:Remote.abc.ElasticSearch(2级源)
- 索引:库存
- 字段:ID——整数
- 字段:产品 -- STRING
- ...
- 索引:库存
连接:Local.xyz.MongoDB(3级源)
- 数据库:邮件
- 集合:用户
- 字段:邮箱 ID -- INTEGER
- 字段:名称 -- STRING
- 收藏:文件
- ...
- 集合:用户
- 数据库:邮件
连接:Local.xyz.SQLServer(4级源)
- 数据库:主要
- 架构:公共
- 表:用户
- 字段:名称 -- STRING
- 表:用户
- 架构:公共
- 数据库:历史
- ...
- 数据库:主要
换句话说,“源”是具有已知数量的级别和每个级别的已知“名称”的层次结构。虽然整个层次结构是可变的,但任何给定源的层次结构将始终具有相同的级别数和名称。建立关系模型的好方法是什么?我的想法是:
联系:
- ID
- 主持人
- (其他详情)
来源类型:
- ID
- 姓名
源类型级别映射:
- 源类型ID
- 级别(整数)
- 姓名
ThreeLevelSource_Level1: # 例如,数据库
- ID
- 父 ID(连接 ID)
- 姓名
- (其他详情)
ThreeLevelSource_Level2: # 例如,表
- ID
- 家长ID (Level1ID)
- 姓名
- (其他详情)
ThreeLevelSource_Level3: # 例如,字段
- ID
- 家长 ID (Level2ID)
- 字段名
- 字段类型
- (其他详情)
然后对其他级别的层次结构执行相同的操作:
- TwoLevelSource_Level1、TwoLevelSource_Level2
- FourLevelSource_Level1、FourLevelSource_Level2、FourLevelSource_Level3、FourLevelSource_Level4
因此,基本上定义已知的层次结构,对于我们添加的每个新源,我们会将其附加到已知的层次结构级别之一。我正在考虑的替代方法是为每个新源创建一个新的层次结构,但是如果我们允许访问 25-50 个源,那么我们实际上将查看数百个表。
对这种类型的分层数据进行建模的好方法是什么?
(另外,是的,我熟悉现有的用于建模分层数据的一般方法,如此处所述 - What are the options for storage hierarchical data in a relational database? , How can yourepresent Heritage in a database? - 以下不是重复。)
关系解决方案
\n响应 和relational-database标签hierarchic-data,后者在前者中是行人。
1.1 初步
\n由于以下要求和之间的差异:
\n- \n
- 真正的 SQL 平台(符合标准、服务器架构、统一语言等)以及 \n
- 假装的“SQL”程序(没有体系结构;跨这些程序的语言位;没有事务;没有 ACID 等)不符合标准,因此错误地使用了该术语,以及 \n
- 非 SQL \n
因此,我使用RecordandField来涵盖所有可能性,而不是传达关系定义的关系术语。
所有可能性都得到满足,但关系型和 SQL 兼容方法(例如 MS SQL Server)被认为是最佳方法,因为它已有 40 年的建立和成熟度,并且没有替代方案。
\n- \n
- SQL 平台的集合;假装“SQL”应用程序;和非 SQL 套件,标记为
DataSource。 \n
1.2 合规性
\n这个解决方案是 100% 关系型的:Codd 的关系模型,而不是学术界宣传为“关系型”的不合格替代方案:
\n- \n
它可以在任何兼容 SQL 的平台上实现
\n \n它具有关系完整性(逻辑完整性,超越引用完整性,即 SQL 和物理完整性);关系力量;和关系速度。
\n \n通过 SQL ACID 事务,所有更新交互都很简单。
\n \n对于假冒的“SQL”和非 SQL,我们不提供任何保证。
\n \n
\n
2 解决方案
\n2.1 概念
\n我很欣赏作为一名开发人员,您关注数据值以及如何检索它。然而,为了支持第三个数据级别,首先需要两个级别的定义:
\n- \n
目录潜力
\n
\n蓝色(参考簇)。
\n市场上可用、组织可能使用的 DtaSource 和定义。根据您的描述,假设为 42。- \n
- 我只会将其委托给 a
developer,而不是 auser_admin,因为设置很重要(较低级别取决于它),并且它描述了每个数据源的物理功能和限制。 \n
\n- 我只会将其委托给 a
目录实际
\n
\n绿色(识别簇)。
\n组织实际签订和使用的数据源和定义。比方说12。此时我们有了连接地址;港口;和users。它直接并通过CHECKS调用函数来约束 CataloguePotential。该级别定义内容(实际存在的表),它不包含数据值。
\n- \n
保持 SQL 思维方式,因为这将是最谨慎的做法,因为它是一个已建立的标准,已经成熟了 40 年,因为它为我们提供了最大的灵活性:CatalogueActual 形成了 SQL Catalogue。
\n \n同样,我对集合中的对象使用了术语
\nRecordand ,而不是and ,后者暗示了关系和 SQL 含义。FieldTableColumn\nSQL 平台
\n
\n该级别可以由查询 SQL 目录的程序自动填充。 \n“SQL”应用程序和非 SQL 套件
\n
\n由于缺少目录,填充是手动的。这可以通过user_admin. 约束将是您的程序尝试尝试查询以验证用户提供的表定义。 \n
\n当前数据
\n
\n黄色(事务群集)
\nuser通过其连接从数据源查询网页的当前数据。假设是,我已将 user::webpage 视为中心并进行管理(每个user连接一个;每个user网页一个),而不是 OO 对象。- \n
- 如果 OO 对象不可靠(取决于您使用的库),或者所有用户网页中只有一组对象,则需要添加更多约束。 \n
\n
2.2 方法
\n你需要:
\n- \n
简单层次结构
\n
\na 单父层次结构,用于复制 SQL 服务器中目录中的固定定义级别,以及为假装“SQL”和非 SQL 构建的目录中的变量级别。- \n
- 关系层次结构以及 SQL 实现细节在层次结构文档中得到了完整定义。简单或单亲模型在 [\xc2\xa7 2.2] 中给出。 \n
- 根级别(不是锚点)是潜在的数据源 \n
- 叶级别是包含数据的级别,可以是 a或 a (对于集合中允许的数据)。\ n
RecordStruct- \n
- 在潜在数据源中,它具有代表性,真正
RecordType具有代表性FieldType\n - 在Actual DataSource 中,它是一个actual
Record,它是 的实例RecordType,而actualField是 的一个更狭义的定义FieldType。 \n
\n - 在潜在数据源中,它具有代表性,真正
\n方法/结构
\n
\n为了处理 aStruct,其在定义方面与 a 相同Record,并允许 aStruct包含 aStruct,我们需要一个抽象级别,即...- \n
\nArticle
\n 要么- \n
- a
Field,这是存储的原子单位,异或 \n - 一个
Struct,其中包含Articles\n
\n- a
需要一个 Exclusive Subtype 集群,在Subtype文档中完全定义了 SQL 实现细节
\n \n
\n方法/数组
\n
\n支持以下Array内容Fields:- \n
- 这些是 的多值依赖项
Field,因此作为子表实现。\n- \n
- 对于标量,其
NumElement值为 1。 \n Field这使得标量所需的独占子类型簇变得多余。 \n
\n - 对于标量,其
\n- 这些是 的多值依赖项
2.3 关系数据模型
\n这是七次迭代后的进度。\xc2\xa0\xc2\xa0它显示了表关系级别(属性级别对于内联图形来说太大)。
\n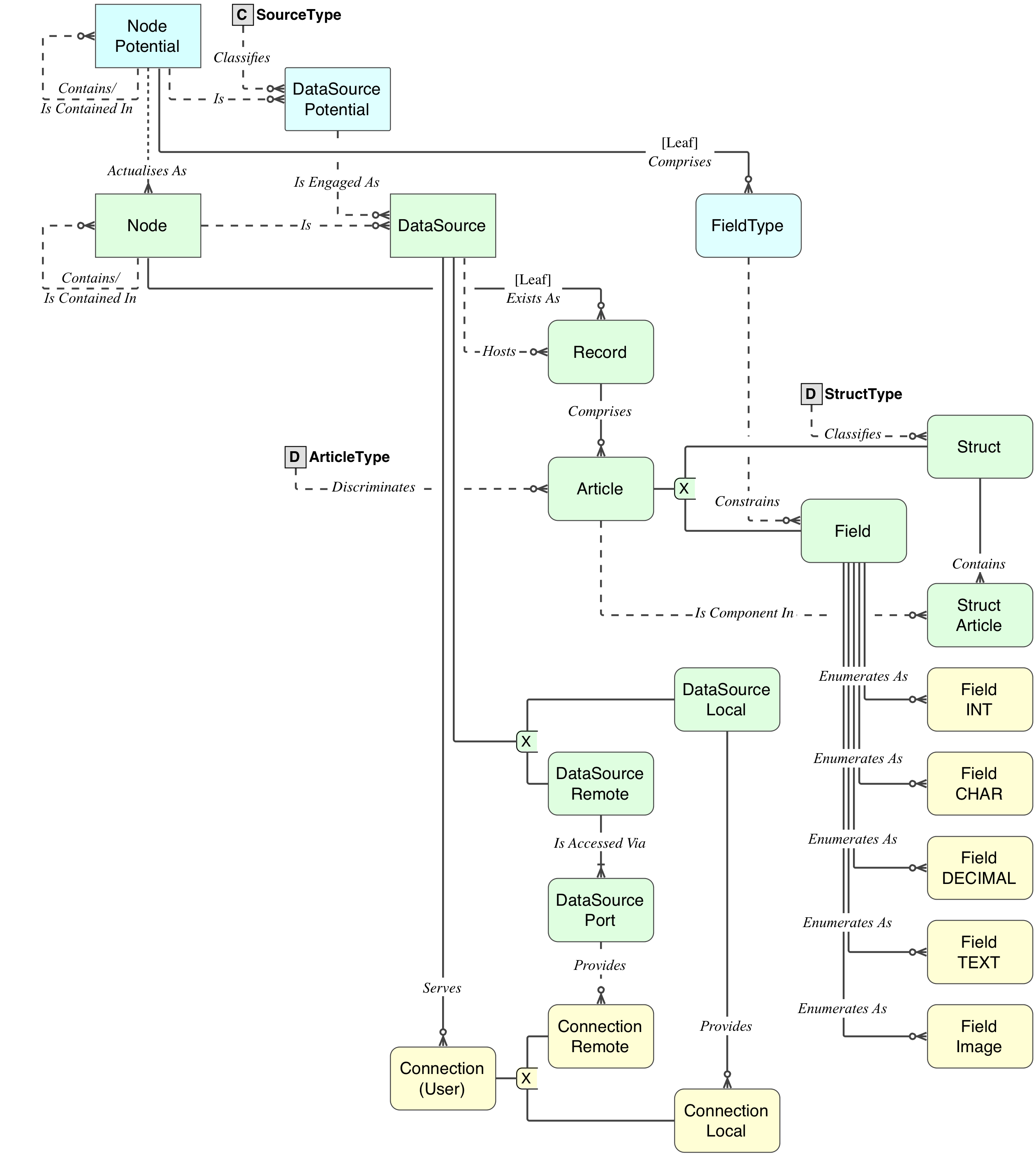
- \n
假设
\n
\nJS(或其他)对象对于网页/用户来说是本地的。\xc2\xa0\xc2\xa0如果您的对象是全局的,则值表需要限制为连接。 \n数据模型在单个PDF中给出:
\n- \n
- 表关系级别 \n
- 表关系级别+样本数据 \n
- 表属性级别+样本数据。 \n
\n
2.4 符号
\n- \n
我所有的数据模型都是在IDEF1X中呈现的,它从 1980 年代初就可用,这是关系数据建模的唯一符号,自 1993 年以来一直是标准。
\n \n对于刚接触 Codd 关系模型或其建模方法的人来说, IDEF1X简介是必不可少的读物。请注意,IDEF1X 模型是完整的,它们具有丰富的细节和精度,显示了所有必需的细节,而本土模型由于不了解标准的要求,因此定义要少得多。这意味着,需要完全理解该符号。
\n \n