swi*_*one 7 optimization performance assembly arm neon
考虑以下在 ARM Cortex-A72 处理器上运行的代码(此处为优化指南)。我已经包含了我期望的每个执行端口的资源压力:
| 操作说明 | 乙 | Ⅰ0 | Ⅰ1 | 中号 | L | S | F0 | F1 |
|---|---|---|---|---|---|---|---|---|
.LBB0_1: |
||||||||
ldr q3, [x1], #16 |
0.5 | 0.5 | 1 | |||||
ldr q4, [x2], #16 |
0.5 | 0.5 | 1 | |||||
add x8, x8, #4 |
0.5 | 0.5 | ||||||
cmp x8, #508 |
0.5 | 0.5 | ||||||
mul v5.4s, v3.4s, v4.4s |
2 | |||||||
mul v5.4s, v5.4s, v0.4s |
2 | |||||||
smull v6.2d, v5.2s, v1.2s |
1 | |||||||
smull2 v5.2d, v5.4s, v2.4s |
1 | |||||||
smlal v6.2d, v3.2s, v4.2s |
1 | |||||||
smlal2 v5.2d, v3.4s, v4.4s |
1 | |||||||
uzp2 v3.4s, v6.4s, v5.4s |
1 | |||||||
str q3, [x0], #16 |
0.5 | 0.5 | 1 | |||||
b.lo .LBB0_1 |
1 | |||||||
| 端口总压力 | 1 | 2.5 | 2.5 | 0 | 2 | 1 | 8 | 1 |
虽然uzp2可以在 F0 或 F1 端口上运行,但我选择将其完全归因于 F1,因为除此指令外,F0 上的压力较高,而 F1 上的压力为零。
除了循环计数器和数组指针之外,循环迭代之间没有任何依赖关系;与循环体其余部分所花费的时间相比,这些问题应该很快得到解决。
因此,我的直觉是该代码应该受到吞吐量限制,并且考虑到最严重的压力是在 F0 上,每次迭代运行 8 个周期(除非它遇到解码瓶颈或缓存未命中)。考虑到流式访问模式以及数组可以轻松放入 L1 缓存的事实,后者不太可能出现。对于前者,考虑到优化手册第4.1节列出的约束,我预计循环体只需8个周期即可解码。
然而,微基准测试表明,循环体的每次迭代平均需要 12.5 个周期。如果不存在其他合理的解释,我可以编辑问题,包括有关如何对这段代码进行基准测试的更多详细信息,但我相当确定这种差异不能仅归因于基准测试工件。另外,我尝试增加迭代次数,以查看性能是否因启动/冷却效应而提高到渐近极限,但对于上面显示的 128 次迭代的选定值,似乎已经这样做了。
手动展开循环以在每次迭代中包含两次计算,从而将性能降低至 13 个周期;但是,请注意,这也会增加加载和存储指令的数量。有趣的是,如果将双倍加载和存储替换为单个LD1/ST1指令(双寄存器格式)(例如ld1 { v3.4s, v4.4s }, [x1], #32),则每次迭代的性能将提高到 11.75 个周期。进一步将循环展开为每次迭代四次计算,同时使用四寄存器格式LD1/ ST1,将性能提高到每次迭代 11.25 个周期。
尽管有所改进,但性能与我仅考虑资源压力时预期的每次迭代 8 个周期仍然相去甚远。即使CPU进行了错误的调度调用并发出uzp2给F0,修改资源压力表也会表明每次迭代有9个周期,与实际测量值仍然相去甚远。那么,是什么导致这段代码的运行速度比预期慢得多呢?我的分析中遗漏了哪些类型的影响?
编辑:正如所承诺的,一些更多的基准测试细节。我运行循环 3 次进行预热,假设 n = 512 运行循环 10 次,然后运行 n = 256 10 次。我采用 n = 512 次运行的最小循环计数,并从 n = 256 的最小值中减去。差异应该给出 n = 256 运行需要多少个周期,同时抵消固定设置成本(代码未显示)。此外,这应该确保所有数据都在 L1 I 和 D 缓存中。通过直接读取周期计数器 ( ) 进行测量pmccntr_el0。任何开销都应该通过上面的测量策略来抵消。
首先,您可以通过将第一个替换mul为uzp1并执行以下操作smull和smlal相反的操作,进一步将理论周期减少到 6 个:mul, mul, smull, smlal=> smull, uzp1, mul,smlal
这也大大减少了寄存器压力,以便我们可以做更深的展开(每次迭代最多 32 个)
你不需要v2系数,但你可以将它们打包到较高的部分v1
让我们通过展开这个深度并将其写入汇编来排除一切:
.arch armv8-a
.global foo
.text
.balign 64
.func
// void foo(int32_t *pDst, int32_t *pSrc1, int32_t *pSrc2, intptr_t count);
pDst .req x0
pSrc1 .req x1
pSrc2 .req x2
count .req x3
foo:
// initialize coefficients v0 ~ v1
stp d8, d9, [sp, #-16]!
.balign 64
1:
ldp q16, q18, [pSrc1], #32
ldp q17, q19, [pSrc2], #32
ldp q20, q22, [pSrc1], #32
ldp q21, q23, [pSrc2], #32
ldp q24, q26, [pSrc1], #32
ldp q25, q27, [pSrc2], #32
ldp q28, q30, [pSrc1], #32
ldp q29, q31, [pSrc2], #32
smull v2.2d, v17.2s, v16.2s
smull2 v3.2d, v17.4s, v16.4s
smull v4.2d, v19.2s, v18.2s
smull2 v5.2d, v19.4s, v18.4s
smull v6.2d, v21.2s, v20.2s
smull2 v7.2d, v21.4s, v20.4s
smull v8.2d, v23.2s, v22.2s
smull2 v9.2d, v23.4s, v22.4s
smull v16.2d, v25.2s, v24.2s
smull2 v17.2d, v25.4s, v24.4s
smull v18.2d, v27.2s, v26.2s
smull2 v19.2d, v27.4s, v26.4s
smull v20.2d, v29.2s, v28.2s
smull2 v21.2d, v29.4s, v28.4s
smull v22.2d, v31.2s, v20.2s
smull2 v23.2d, v31.4s, v30.4s
uzp1 v24.4s, v2.4s, v3.4s
uzp1 v25.4s, v4.4s, v5.4s
uzp1 v26.4s, v6.4s, v7.4s
uzp1 v27.4s, v8.4s, v9.4s
uzp1 v28.4s, v16.4s, v17.4s
uzp1 v29.4s, v18.4s, v19.4s
uzp1 v30.4s, v20.4s, v21.4s
uzp1 v31.4s, v22.4s, v23.4s
mul v24.4s, v24.4s, v0.4s
mul v25.4s, v25.4s, v0.4s
mul v26.4s, v26.4s, v0.4s
mul v27.4s, v27.4s, v0.4s
mul v28.4s, v28.4s, v0.4s
mul v29.4s, v29.4s, v0.4s
mul v30.4s, v30.4s, v0.4s
mul v31.4s, v31.4s, v0.4s
smlal v2.2d, v24.2s, v1.2s
smlal2 v3.2d, v24.4s, v1.4s
smlal v4.2d, v25.2s, v1.2s
smlal2 v5.2d, v25.4s, v1.4s
smlal v6.2d, v26.2s, v1.2s
smlal2 v7.2d, v26.4s, v1.4s
smlal v8.2d, v27.2s, v1.2s
smlal2 v9.2d, v27.4s, v1.4s
smlal v16.2d, v28.2s, v1.2s
smlal2 v17.2d, v28.4s, v1.4s
smlal v18.2d, v29.2s, v1.2s
smlal2 v19.2d, v29.4s, v1.4s
smlal v20.2d, v30.2s, v1.2s
smlal2 v21.2d, v30.4s, v1.4s
smlal v22.2d, v31.2s, v1.2s
smlal2 v23.2d, v31.4s, v1.4s
uzp2 v24.4s, v2.4s, v3.4s
uzp2 v25.4s, v4.4s, v5.4s
uzp2 v26.4s, v6.4s, v7.4s
uzp2 v27.4s, v8.4s, v9.4s
uzp2 v28.4s, v16.4s, v17.4s
uzp2 v29.4s, v18.4s, v19.4s
uzp2 v30.4s, v20.4s, v21.4s
uzp2 v31.4s, v22.4s, v23.4s
subs count, count, #32
stp q24, q25, [pDst], #32
stp q26, q27, [pDst], #32
stp q28, q29, [pDst], #32
stp q30, q31, [pDst], #32
b.gt 1b
.balign 16
ldp d8, d9, [sp], #16
ret
.endfunc
.end
上面的代码即使按顺序也具有零延迟。唯一可能影响性能的是缓存未命中损失。
你可以测量一下循环次数,如果每次迭代远远超过48次,那么芯片或者文档肯定有问题。
否则,A72 的 OoO 发动机可能会像 Peter 指出的那样黯淡无光。
PS:或者 A72 上的加载/存储端口可能不会并行发出。考虑到您展开的实验,这是有道理的。
从Jake的代码开始,将展开因子减少一半,更改一些寄存器分配,并尝试加载/存储指令的许多不同变体(以及不同的寻址模式)和指令调度,我最终得到了以下解决方案:
ld1 {v16.4s, v17.4s, v18.4s, v19.4s}, [pSrc1], #64
ld1 {v20.4s, v21.4s, v22.4s, v23.4s}, [pSrc2], #64
add count, pDst, count, lsl #2
// initialize v0/v1
loop:
smull v24.2d, v20.2s, v16.2s
smull2 v25.2d, v20.4s, v16.4s
uzp1 v2.4s, v24.4s, v25.4s
smull v26.2d, v21.2s, v17.2s
smull2 v27.2d, v21.4s, v17.4s
uzp1 v3.4s, v26.4s, v27.4s
smull v28.2d, v22.2s, v18.2s
smull2 v29.2d, v22.4s, v18.4s
uzp1 v4.4s, v28.4s, v29.4s
smull v30.2d, v23.2s, v19.2s
smull2 v31.2d, v23.4s, v19.4s
uzp1 v5.4s, v30.4s, v31.4s
mul v2.4s, v2.4s, v0.4s
ldp q16, q17, [pSrc1]
mul v3.4s, v3.4s, v0.4s
ldp q18, q19, [pSrc1, #32]
add pSrc1, pSrc1, #64
mul v4.4s, v4.4s, v0.4s
ldp q20, q21, [pSrc2]
mul v5.4s, v5.4s, v0.4s
ldp q22, q23, [pSrc2, #32]
add pSrc2, pSrc2, #64
smlal v24.2d, v2.2s, v1.2s
smlal2 v25.2d, v2.4s, v1.4s
uzp2 v2.4s, v24.4s, v25.4s
str q24, [pDst], #16
smlal v26.2d, v3.2s, v1.2s
smlal2 v27.2d, v3.4s, v1.4s
uzp2 v3.4s, v26.4s, v27.4s
str q25, [pDst], #16
smlal v28.2d, v4.2s, v1.2s
smlal2 v29.2d, v4.4s, v1.4s
uzp2 v4.4s, v28.4s, v29.4s
str q26, [pDst], #16
smlal v30.2d, v5.2s, v1.2s
smlal2 v31.2d, v5.4s, v1.4s
uzp2 v5.4s, v30.4s, v31.4s
str q27, [pDst], #16
cmp count, pDst
b.ne loop
请注意,虽然我仔细检查了代码,但我尚未测试它是否真正有效,因此可能缺少一些会影响性能的东西。需要进行循环的最后一次迭代,删除加载指令,以防止越界内存访问;我省略了这个以节省一些空间。
对原始问题进行类似的分析,假设代码完全吞吐量受限,则表明该循环将需要 24 个周期。标准化为与其他地方使用的相同度量(即每 4 元素迭代的周期),这将计算为 6 个周期/迭代。对代码进行基准测试,结果是每个循环执行 26 个周期,或者按照标准化指标,6.5 个周期/迭代。虽然不是据说可以实现的最低限度,但它已经非常接近了。
对于其他在对 Cortex-A72 性能摸不着头脑后偶然发现这个问题的人,请注意以下几点:
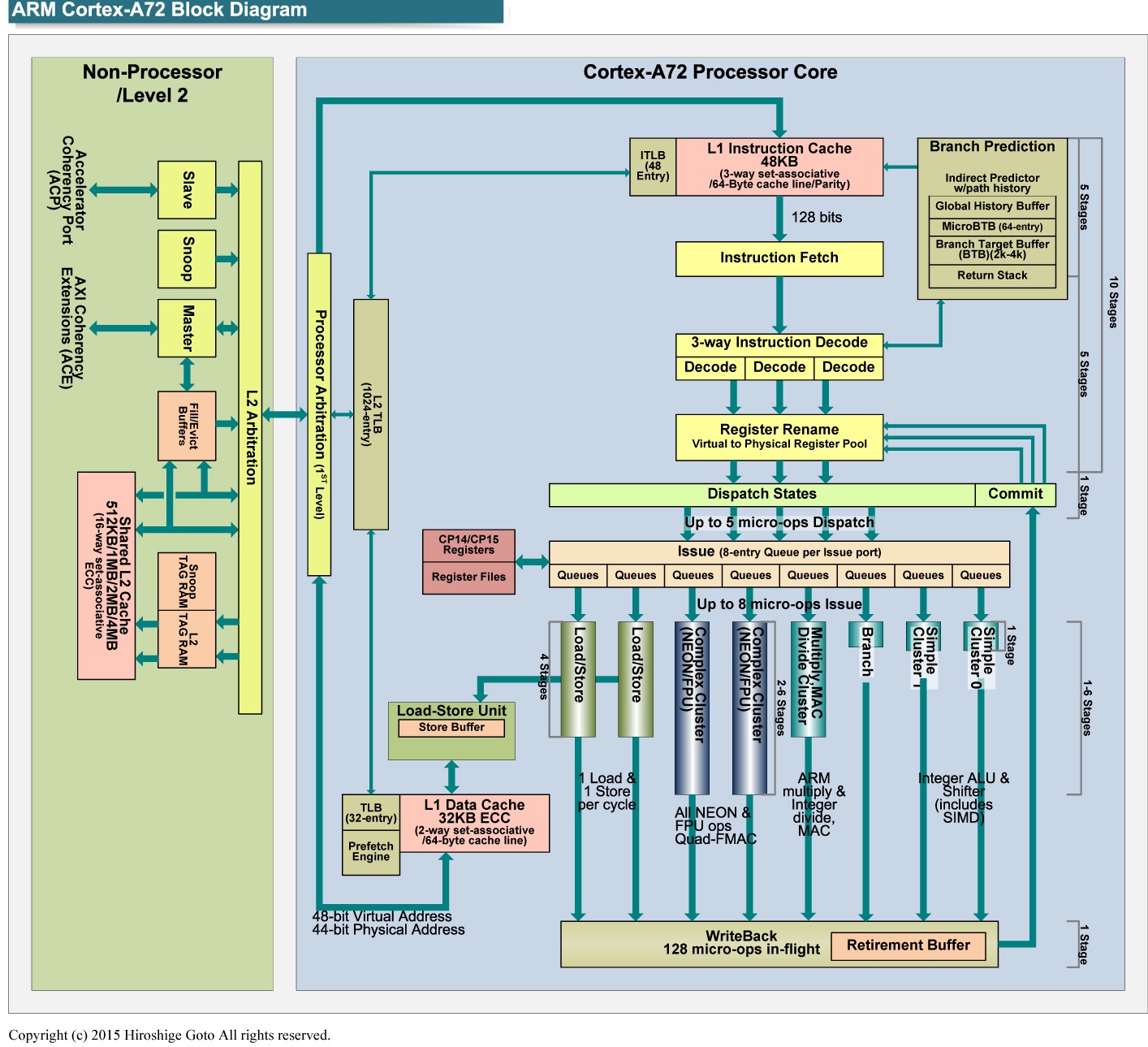
调度程序(保留站)是每个端口的而不是全局的(请参阅本文和此框图)。除非您的代码在加载、存储、标量、Neon、分支等之间具有非常平衡的指令组合,否则 OoO 窗口将比您预期的小,有时甚至非常小。对于每端口调度程序来说,这段代码尤其是一个病态的情况。因为所有指令的 70% 是 Neon,所有指令的 50% 是乘法(仅在 F0 端口上运行)。对于这些乘法,OoO 窗口是非常贫乏的 8 条指令,因此不要指望 CPU 在执行当前迭代时查看下一个循环迭代的指令。
尝试将展开因子进一步降低一半会导致大幅减速 (23%)。我猜测原因是 OoO 窗口较浅,这是由于每个端口的调度程序以及绑定到端口 F0 的指令的普遍性较高,如上面第 1 点所述。如果无法查看下一次迭代,则需要提取的并行性就会减少,因此代码会受到延迟而不是吞吐量的限制。因此,交错循环的多次迭代似乎是该核心需要考虑的重要优化策略。
必须注意负载所使用的特定寻址模式。将原始代码中使用的立即后索引寻址模式替换为立即偏移,然后在其他地方手动执行递增指针,会带来性能提升,但仅限于加载(存储不受影响)。在优化手册的第 4.5 节(“加载/存储吞吐量”)中,在内存复制例程的上下文中对此进行了暗示,但没有给出任何理由。不过,我相信下面的第 4 点对此进行了解释。
显然,这段代码的主要瓶颈是写入寄存器文件:根据另一个SO问题的答案,寄存器文件仅支持每个周期写入192位。这可以解释为什么加载应避免使用带回写(索引前和索引后)的寻址模式,因为这会消耗额外的 64 位将结果写回寄存器文件。LDP在使用 Neon 指令和向量加载时(使用2/3/4 寄存器版本时更是如此),很容易超出此限制LD1,而不会增加写回递增地址的压力。subs知道这一点后,我还决定用与 的比较来替换 Jake 代码中的原始代码pDst,因为比较不会写入寄存器文件 - 这实际上将性能提高了 1/4 个周期。
有趣的是,在一次循环执行期间将写入寄存器文件的位数相加,结果为 4992 位(我不知道写入 PC,特别是通过指令b.ne,是否应包含在计数中;我任意选择不)。考虑到 192 位/周期限制,至少需要 26 个周期才能跨循环将所有这些结果写入寄存器文件。因此,似乎仅通过重新安排指令无法使上面的代码变得更快。
理论上,通过将存储的寻址模式切换为立即偏移,然后包含一条额外的指令来显式递增,可以减少 1 个周期pDst。对于原始代码,4 个存储中的每一个都将向 写入 64 位pDst,总共 256 位,而如果pDst显式递增一次,则仅写入一次 64 位。因此,此更改将导致节省 192 位,即 1 个周期的寄存器文件写入量。我尝试了这种更改,试图在代码的许多不同点上安排pSrc1//pSrc2的增量pDst,但不幸的是我只能减慢而不是加快代码的速度。也许我遇到了不同的瓶颈,例如指令解码。
{kind=link}