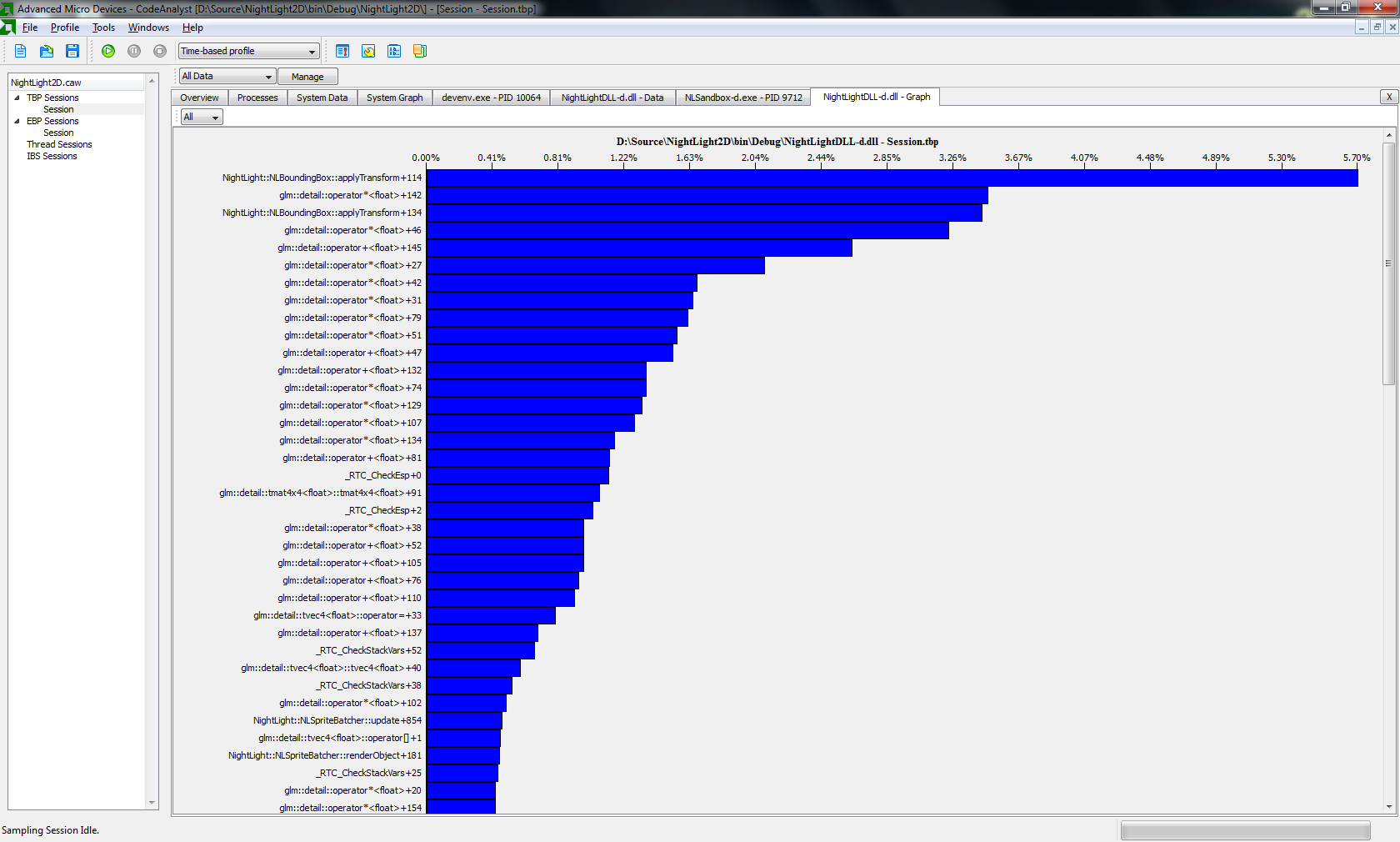
我正在编写一个OpenGL3 2D引擎.目前,我正在努力解决瓶颈问题.因此,AMD Profiler的以下输出:http: //h7.abload.de/img/profilerausa.png
数据是使用数千个精灵制作的.
然而,在50,000个精灵上,testapp已经无法以5 fps的速度使用.
这表明,我的瓶颈是我使用的转换功能.这是相应的功能:http: //code.google.com/p/nightlight2d/source/browse/NightLightDLL/NLBoundingBox.cpp#130
void NLBoundingBox::applyTransform(NLVertexData* vertices)
{
if ( needsTransform() )
{
// Apply Matrix
for ( int i=0; i<6; i++ )
{
glm::vec4 transformed = m_rotation * m_translation * glm::vec4(vertices[i].x, vertices[i].y, 0, 1.0f);
vertices[i].x = transformed.x;
vertices[i].y = transformed.y;
}
m_translation = glm::mat4(1);
m_rotation = glm::mat4(1);
m_needsTransform = false;
}
}
我无法在着色器中执行此操作,因为我正在同时批处理所有精灵.这意味着,我必须使用CPU来计算变换.
我的问题是:解决这个瓶颈的最佳方法是什么?
我不使用任何线程atm,所以当我使用vsync时,我也会获得额外的性能,因为它等待屏幕完成.这告诉我应该使用线程.
另一种方法是使用OpenCL吗?我想避免使用CUDA,因为据我所知它只能在NVIDIA显卡上运行.是对的吗?
后脚本:
如果您愿意,可以在此处下载演示:
http://www63.zippyshare.com/v/45025690/file.html
请注意,这需要安装VC++ 2008,因为它是运行探查器的调试版本.
我要做的第一件事是在进入 for 循环之前将旋转和变换矩阵连接成一个矩阵......这样您就不会在每个 for 循环上计算两个矩阵乘法和一个向量;相反,您只需将单个向量和矩阵相乘。其次,您可能想要研究展开循环,然后使用更高的优化级别进行编译(g++我至少会使用-O2,但我不熟悉 MSVC,因此您必须自己翻译该优化级别)。这将避免代码中的分支可能产生的任何开销,尤其是在缓存刷新时。最后,如果您还没有研究过它,请检查一下进行一些 SSE 优化,因为您正在处理向量。
更新:我要添加最后一个涉及线程的想法......基本上在进行线程处理时管道化你的顶点。举例来说,假设您有一台具有八个可用 CPU 线程(即具有超线程的四核)的计算机。设置六个线程用于顶点管道处理,并使用非锁定单消费者/生产者队列在管道各阶段之间传递消息。每个阶段都会变换六成员顶点数组中的一个成员。我猜测有很多这样的六成员顶点数组,因此在通过管道传递的流中进行设置,您可以非常有效地处理流,并避免使用互斥体和其他锁定信号量等。有关快速非锁定单一生产者/消费者队列的更多信息,请参阅我的回答。
更新 2:你只有一个双核处理器……所以放弃管道的想法,因为它会遇到瓶颈,因为每个线程都会争夺 CPU 资源。
{kind=link}