yaq*_*awa 6 gitlab gitlab-ci gitlab-ci-runner
根据文档:
\n\n\n\n\n由于缓存在作业之间共享,如果您\xe2\x80\x99对不同的作业使用不同的路径,您还应该设置不同的cache:key,否则缓存内容可能会被覆盖。
\n
这对我来说听起来很奇怪。
\n\n所以如果我像这样“对不同的工作使用不同的路径”
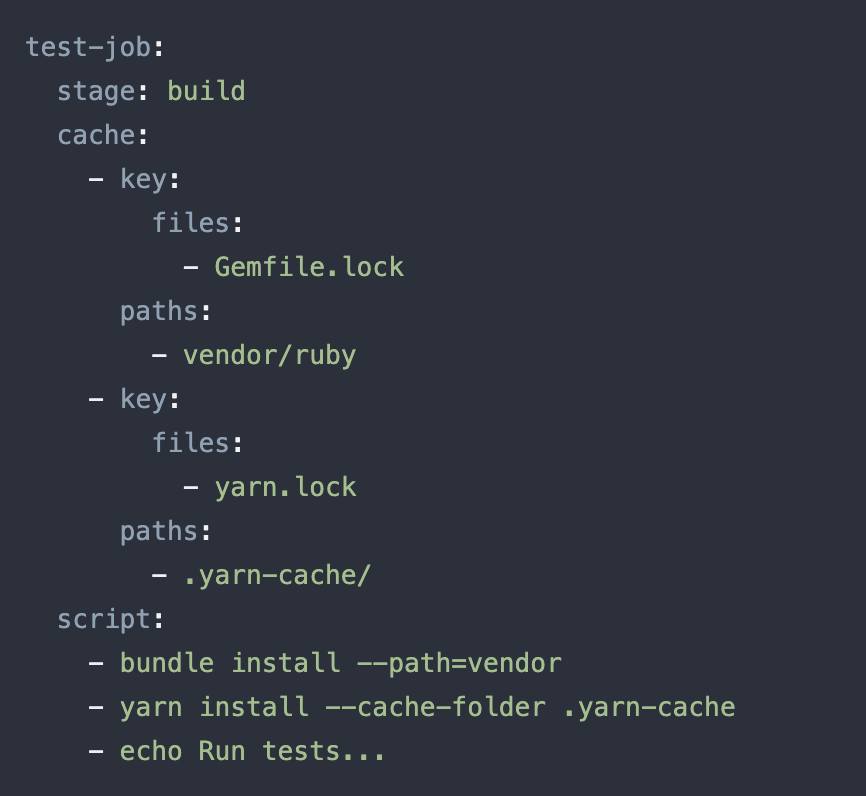
\n\njob_a:\n paths:\n - binaries/\n\njob_b:\n paths:\n - node_modules/\n缓存怎么会被覆盖..?
\n\n这是否意味着node_modules将覆盖binaries?因为缓存键是相同的?
有谁知道gitlab中缓存的实现细节吗?
\n\n是这样操作的吗??
\n\n\n$job_cache_key = $job_cache_key || \'default\';\n\nif ($cache[$job_cache_key]){\n return $cache[$job_cache_key];\n}\n\n$cache[$job_cache_key] = $job_cache;\n\nreturn $job_cache;\n在 GitLab 中缓存键模仿Rails 缓存,不过,正如app/models/concerns/faster_cache_keys.rb提到的:
# Rails' default "cache_key" method uses all kind of complex logic to figure
# out the cache key. In many cases this complexity and overhead may not be
# needed.
#
# This method does not do any timestamp parsing as this process is quite
# expensive and not needed when generating cache keys. This method also relies
# on the table name instead of the cache namespace name as the latter uses
# complex logic to generate the exact same value (as when using the table
# name) in 99% of the cases.
管道本身从初始化其本地缓存开始:lib/gitlab/ci/pipeline/seed/build/cache.rb
您可以在中查看缓存示例spec/lib/gitlab/ci/pipeline/seed/build/cache_spec.rb
这是否意味着
node_modules将覆盖binaries?因为缓存键是相同的?
否:每个作业将使用自己的路径集,这会覆盖全局缓存中定义的任何路径集。
gitlab-org/gitlab-runnerIssue 2838询问每个作业的缓存,并给出示例:
stages:
- build
- build-image
# the following line is the global cache configuration but also defines an anchor with the name of "cache"
# you can refer to the anchor and reuse this cache configuration in your jobs.
# you can also add and replace properties
# In the job definitions you will find examples.
# for more information regarding reuse in YAML files, see https://blog.daemonl.com/2016/02/yaml.html
cache: &cache
paths:
- api/node_modules/
- global/node_modules/
- frontend/node_modules/
# first job, it does not have an explicit cache definition:
# therefore it uses the global cache definition!
build-app:
stage: build
image: node:8
before_script:
- yarn
- cd frontend
script:
- npm run build
# a job in a later stage, have a look at the cache block!
# it "inherits" from the global cache block and adds the "policy: pull" key / value
build-image-api:
stage: build-image
image: docker
dependencies: []
cache:
<<: *cache
policy: pull
before_script:
# .... and so on
该继承机制也记录在缓存的“继承全局配置,但覆盖每个作业的特定设置”部分
您可以使用锚点覆盖缓存设置,而无需覆盖全局缓存。
例如,如果您想要覆盖一项作业的策略:
cache: &global_cache
key: ${CI_COMMIT_REF_SLUG}
paths:
- node_modules/
- public/
- vendor/
policy: pull-push
job:
cache:
# inherit all global cache settings
<<: *global_cache
# override the policy
policy: pull
一年多后(2021 年第二季度):
请参阅GitLab 13.11(2021 年 4 月)
在同一个作业中使用多个缓存
GitLab CI/CD 提供了缓存机制,可以在作业运行时节省宝贵的开发时间。以前,不可能在同一个作业中配置多个缓存键。此限制可能导致您使用工件进行缓存,或使用具有不同缓存路径的重复作业。在此版本中,我们提供了在单个作业中配置多个缓存键的功能,这将帮助您提高管道性能。
https://about.gitlab.com/images/13_11/cache.png -- 在同一作业中使用多个缓存
| 归档时间: |
|
| 查看次数: |
9387 次 |
| 最近记录: |
{kind=link}