Cra*_*cis 8 python audio audio-processing librosa
我加载了 3 小时的 MP3 文件,每大约 15 分钟就会播放一次独特的 1 秒音效,这标志着新章节的开始。
是否可以识别每次播放该音效的时间,以便我可以记录时间偏移?
每次的声音效果都相似,但由于它是以有损文件格式编码的,因此会有少量变化。
时间偏移将存储在ID3 章节帧元数据中。
示例 Source,其中声音效果播放两次。
ffmpeg -ss 0.9 -i source.mp3 -t 0.95 sample1.mp3 -acodec copy -y
ffmpeg -ss 4.5 -i source.mp3 -t 0.95 sample2.mp3 -acodec copy -y
我对音频处理非常陌生,但我最初的想法是提取 1 秒音效的样本,然后librosa在 python 中使用来提取两个文件的浮点时间序列,对浮点数进行舍入,并尝试获取一场比赛。
import numpy
import librosa
print("Load files")
source_series, source_rate = librosa.load('source.mp3') # 3 hour file
sample_series, sample_rate = librosa.load('sample.mp3') # 1 second file
print("Round series")
source_series = numpy.around(source_series, decimals=5);
sample_series = numpy.around(sample_series, decimals=5);
print("Process series")
source_start = 0
sample_matching = 0
sample_length = len(sample_series)
for source_id, source_sample in enumerate(source_series):
if source_sample == sample_series[sample_matching]:
sample_matching += 1
if sample_matching >= sample_length:
print(float(source_start) / source_rate)
sample_matching = 0
elif sample_matching == 1:
source_start = source_id;
else:
sample_matching = 0
这不适用于上面的 MP3 文件,但适用于 MP4 版本 - 它能够找到我提取的样本,但只是那一个样本(并非全部 12 个样本)。
我还应该注意到,这个脚本只需要 1 分钟多一点的时间来处理 3 小时的文件(其中包括 237,426,624 个样本)。所以我可以想象,对每个循环进行某种平均会导致花费相当长的时间。
为了跟进 @jonnor 和 @paul-john-leonard 的答案,他们都是正确的,通过使用帧(FFT),我能够进行音频事件检测。
我已经在以下位置编写了完整的源代码:
https://github.com/craigfrancis/audio-detect
但有一些注意事项:
为了创建模板,我使用了 ffmpeg:
ffmpeg -ss 13.15 -i source.mp4 -t 0.8 -acodec copy -y templates/01.mp4;
我决定使用librosa.core.stft,但我需要为我正在分析的 3 小时文件自行实现此stft函数,因为它太大而无法保存在内存中。
使用时stft,我首先尝试使用 64 的 hop_length,而不是默认值(512),因为我认为这会给我更多的数据来处理......理论可能是正确的,但 64 太详细了,导致大多数时候它都会失败。
我仍然不知道如何使帧和模板之间的互相关起作用(通过numpy.correlate)...相反,我获取了每帧的结果(1025 个桶,而不是 1024,我相信这与找到的 Hz 频率有关)并执行了一个非常简单的平均差异检查,然后确保平均值高于某个值(我的测试用例工作在 0.15,我使用它的主文件需要 0.55 - 大概是因为主文件已被压缩得更多):
hz_score = abs(source[0:1025,x] - template[2][0:1025,y])
hz_score = sum(hz_score)/float(len(hz_score))
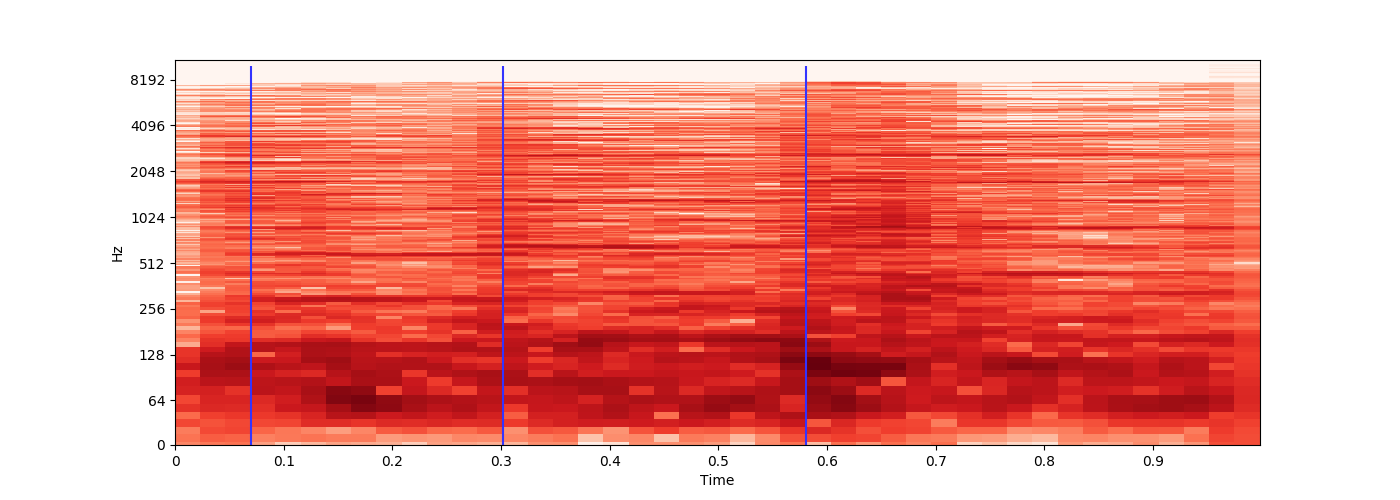
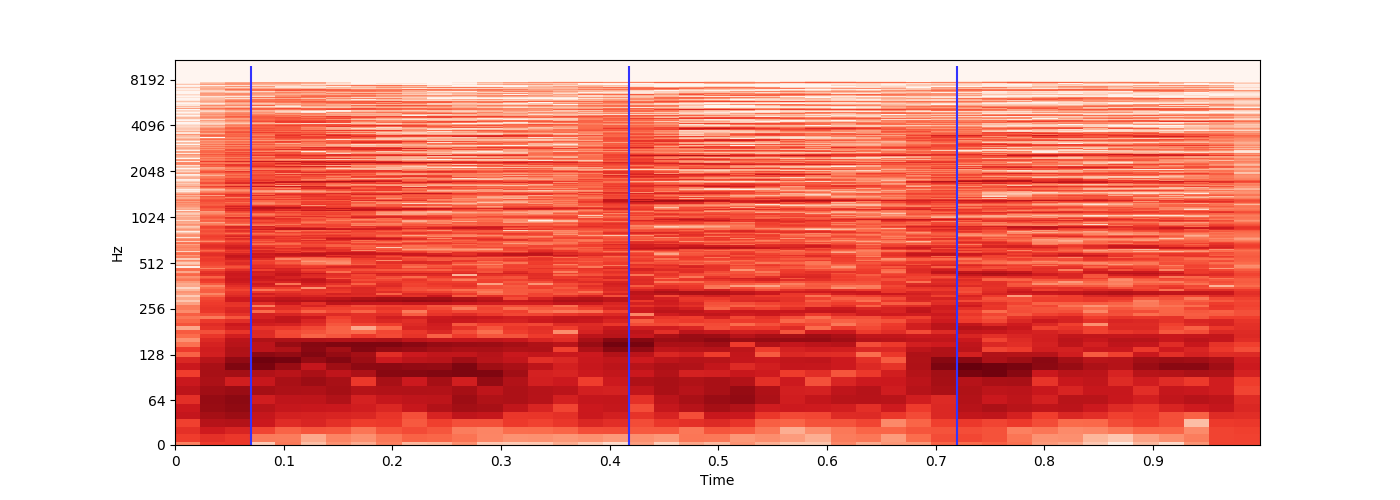
在检查这些分数时,将它们显示在图表上确实很有用。我经常使用类似以下的东西:
import matplotlib.pyplot as plt
plt.figure(figsize=(30, 5))
plt.axhline(y=hz_match_required_start, color='y')
while x < source_length:
debug.append(hz_score)
if x == mark_frame:
plt.axvline(x=len(debug), ymin=0.1, ymax=1, color='r')
plt.plot(debug)
plt.show()
创建模板时,您需要修剪掉任何领先的沉默(以避免不良匹配),以及额外的约 5 帧(似乎压缩/重新编码过程会改变这一点)...同样,删除最后 2 个帧帧(我认为这些帧包含来自周围环境的一些数据,特别是最后一个可能有点偏离)。
当您开始寻找匹配项时,您可能会发现前几帧没问题,然后就失败了……您可能需要在一两帧后重试。我发现拥有一个支持多个模板(声音略有变化)的流程会更容易,并且会检查它们的第一个可测试(例如第 6 个)帧,如果匹配,则将它们放入潜在匹配列表中。然后,当它继续处理源的下一帧时,它可以将其与模板的下一帧进行比较,直到模板中的所有帧都匹配(或失败)。
{kind=link}
{kind=link}