为什么对于两个核心,同一核心(超线程)中的两个线程的L1写访问访问最差?
Man*_*uel 5 c++ x86 multithreading
我已经制作了ac/c ++程序(printf和的混合std::)来了解不同的缓存性能.我想并行化一个计算大块内存的进程.我必须在相同的内存位置上进行多次计算,因此我会在结果上写入结果,覆盖源数据.当第一个微积分完成后,我再做一个以前的结果.
I've guessed if I have two threads, one making the first calculus, and the other the second, I would improve performance because each thread does half the work, thus making the process twice as fast. I've read how caches work, so I know if this isn't done well, it may be even worse, so I've write a small program to measure everything.
(See below for machine topology, CPU type and flags and source code.)
I've seen some strange results.
Apparently, there is no difference in taking data from L1, L2, L3 or RAM in order to do the calculations. I doesn't matter if I'm working in the same buffer or two different buffers (with distance in memory between them) unless they are in the same core.
I mean: the worst results are when the two threads are in the same core (hyper-threading). I set them with CPU affinity
There are some options for my program, but they are self explanatory.
These are the commands and the results:
./main --loops 200 --same-buffer --flush
200000 loops.
Flushing caches.
Cache size: 32768
Using same buffer.
Running in cores 0 and 1.
Waiting 2 seconds just for threads to be ready.
Post threads to begin work 200000 iterations.
Thread two created, pausing.
Go ahead and calculate in 2...
Buffer address: 0x7f087c156010.
Waiting for thread semaphores.
Thread one created, pausing.
Go ahead and calculate in 1...
Buffer address: 0x7f087c156010.
Time 1 18.436685
Time 2 18.620263
We don't wait anymore.
Joining threads.
Dumping data.
Exiting from main thread.
We can see it is running in cores 0 and 1, according to my topology, different cores. The buffer address is the same: 0x7f087c156010.
The time: 18secs.
Now in the same core:
./main --loops 200 --same-buffer --same-core --flush
200000 loops.
Flushing caches.
Cache size: 32768
Using same buffer.
Using same core. (HyperThreading)
Thread one created, pausing.
Thread two created, pausing.
Running in cores 0 and 6.
Waiting 2 seconds just for threads to be ready.
Post threads to begin work 200000 iterations.
Waiting for thread semaphores.
Go ahead and calculate in 1...
Buffer address: 0x7f0a6bbe1010.
Go ahead and calculate in 2...
Buffer address: 0x7f0a6bbe1010.
Time 1 26.572419
Time 2 26.951195
We don't wait anymore.
Joining threads.
Dumping data.
Exiting from main thread.
We can see it is running in cores 0 and 6, according to my topology, same core, two hyper-threads. Same buffer.
The time: 26secs.
So 10 seconds slower.
How's that possible? I've understood if the cache line isn't dirty, it wouldn't be fetched from memory (either, L1, 2, 3 or RAM). I've made the program writing alternative 64 byte arrays, so same as one cache line. If one thread writes cache line 0, the other writes cache line 1, so there is no cache line clash.
Does this means two hyper-threads, even if they share the L1 cache, can't write to it at the same time?
Apparently, working in two distinct cores does better than one alone.
-- Edit --
As suggested by commenters and Max Langhof, I've included code to align buffers. I've also added an option to misalign the buffers only to see the difference.
I'm not sure about the align and misaling code, but I've copied from here
Just like they told me, it's a waste of time to measure non optimized code.
And for optimized code the results are pretty interesting. What I found surprising is that it takes the same time, even misaligning data and with two cores, but I suppose that's because the small amount of work in the inner loop. (And I guess that shows how well designed are today processors.)
Numbers (taken with perf stat -d -d -d):
*** Same core
No optimization
---------------
No aligment
39.866.074.445 L1-dcache-loads # 1485,716 M/sec (21,75%)
10.746.914 L1-dcache-load-misses # 0,03% of all L1-dcache hits (20,84%)
Aligment
39.685.928.674 L1-dcache-loads # 1470,627 M/sec (22,77%)
11.003.261 L1-dcache-load-misses # 0,03% of all L1-dcache hits (27,37%)
Misaligment
39.702.205.508 L1-dcache-loads # 1474,958 M/sec (24,08%)
10.740.380 L1-dcache-load-misses # 0,03% of all L1-dcache hits (29,05%)
Optimization
------------
No aligment
39.702.205.508 L1-dcache-loads # 1474,958 M/sec (24,08%)
10.740.380 L1-dcache-load-misses # 0,03% of all L1-dcache hits (29,05%)
2,390298203 seconds time elapsed
Aligment
19.450.626 L1-dcache-loads # 25,108 M/sec (23,21%)
1.758.012 L1-dcache-load-misses # 9,04% of all L1-dcache hits (22,95%)
2,400644369 seconds time elapsed
Misaligment
2.687.025 L1-dcache-loads # 2,876 M/sec (24,64%)
968.413 L1-dcache-load-misses # 36,04% of all L1-dcache hits (12,98%)
2,483825841 seconds time elapsed
*** Two cores
No optimization
---------------
No aligment
39.714.584.586 L1-dcache-loads # 2156,408 M/sec (31,17%)
206.030.164 L1-dcache-load-misses # 0,52% of all L1-dcache hits (12,55%)
Aligment
39.698.566.036 L1-dcache-loads # 2129,672 M/sec (31,10%)
209.659.618 L1-dcache-load-misses # 0,53% of all L1-dcache hits (12,54%)
Misaligment
2.687.025 L1-dcache-loads # 2,876 M/sec (24,64%)
968.413 L1-dcache-load-misses # 36,04% of all L1-dcache hits (12,98%)
Optimization
------------
No aligment
16.711.148 L1-dcache-loads # 9,431 M/sec (31,08%)
202.059.646 L1-dcache-load-misses # 1209,13% of all L1-dcache hits (12,87%)
2,898511757 seconds time elapsed
Aligment
18.476.510 L1-dcache-loads # 10,484 M/sec (30,99%)
202.180.021 L1-dcache-load-misses # 1094,25% of all L1-dcache hits (12,83%)
2,894591875 seconds time elapsed
Misaligment
18.663.711 L1-dcache-loads # 11,041 M/sec (31,28%)
190.887.434 L1-dcache-load-misses # 1022,77% of all L1-dcache hits (13,22%)
2,861316941 seconds time elapsed
-- End edit --
The program creates log files with buffer dumps, so I've verified it works as expected (you can see below).
我也有ASM,我们可以看到循环正在做的事情.
269:main.cc **** for (int x = 0; x < 64; ++x)
1152 .loc 1 269 0 is_stmt 1
1153 0c0c C745F000 movl $0, -16(%rbp) #, x
1153 000000
1154 .L56:
1155 .loc 1 269 0 is_stmt 0 discriminator 3
1156 0c13 837DF03F cmpl $63, -16(%rbp) #, x
1157 0c17 7F26 jg .L55 #,
270:main.cc **** th->cache->cache[i].data[x] = '2';
1158 .loc 1 270 0 is_stmt 1 discriminator 2
1159 0c19 488B45E8 movq -24(%rbp), %rax # th, tmp104
1160 0c1d 488B4830 movq 48(%rax), %rcx # th_9->cache, _25
1161 0c21 8B45F0 movl -16(%rbp), %eax # x, tmp106
1162 0c24 4863D0 movslq %eax, %rdx # tmp106, tmp105
1163 0c27 8B45F4 movl -12(%rbp), %eax # i, tmp108
1164 0c2a 4898 cltq
1165 0c2c 48C1E006 salq $6, %rax #, tmp109
1166 0c30 4801C8 addq %rcx, %rax # _25, tmp109
1167 0c33 4801D0 addq %rdx, %rax # tmp105, tmp110
1168 0c36 C60032 movb $50, (%rax) #, *_25
269:main.cc **** for (int x = 0; x < 64; ++x)
这是转储的一部分:
== buffer ==============================================================================================================
00000001 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
00000002 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
00000003 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
00000004 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
00000005 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32
00000006 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32
00000007 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32
00000008 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32 0x32
我的机器拓扑:

这是CPU类型和标志.
processor : 11
vendor_id : GenuineIntel
cpu family : 6
model : 45
model name : Intel(R) Xeon(R) CPU E5-2640 0 @ 2.50GHz
stepping : 7
microcode : 0x70b
cpu MHz : 1504.364
cache size : 15360 KB
physical id : 0
siblings : 12
core id : 5
cpu cores : 6
apicid : 11
initial apicid : 11
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx lahf_lm epb kaiser tpr_shadow vnmi flexpriority ept vpid xsaveopt dtherm ida arat pln pts
bugs : cpu_meltdown spectre_v1 spectre_v2
bogomips : 4987.77
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
这是完整的源代码:
//
//
//
//
#include <emmintrin.h>
#include <x86intrin.h>
#include <stdio.h>
#include <time.h>
#include <ctime>
#include <semaphore.h>
#include <pthread.h>
#include <string.h>
#include <string>
struct cache_line {
char data[64];
};
//
// 32768 = 32 Kb = 512 64B cache lines
struct cache_l1 {
struct cache_line cache[512];
};
size_t TOTAL = 100000;
void * thread_one (void * data);
void * thread_two (void * data);
void dump (FILE * file, char * buffer, size_t size);
class thread {
public:
sem_t sem;
sem_t * glob;
pthread_t thr;
struct cache_l1 * cache;
};
bool flush = false;
int main (int argc, char ** argv)
{
bool same_core = false;
bool same_buffer = false;
bool align = false;
bool misalign = false;
size_t reserve_mem = 32768; // 15MB 15.728.640
std::string file_name ("pseudobench_");
std::string core_option ("diffcore");
std::string buffer_option ("diffbuff");
std::string cache_option ("l1");
for (int i = 1; i < argc; ++i) {
if (::strcmp("--same-core", argv[i]) == 0) {
same_core = true;
core_option = "samecore";
} else if (::strcmp("--same-buffer", argv[i]) == 0) {
same_buffer = true;
buffer_option = "samebuffer";
} else if (::strcmp("--l1", argv[i]) == 0) {
// nothing already L1 cache size
} else if (::strcmp("--l2", argv[i]) == 0) {
reserve_mem *= 8; // 256KB, L2 cache size
cache_option = "l2";
} else if (::strcmp("--l3", argv[i]) == 0) {
reserve_mem *= 480; // 15MB, L3 cache size
cache_option = "l3";
} else if (::strcmp("--ram", argv[i]) == 0) {
reserve_mem *= 480; // 15MB, plus two times L1 cache size
reserve_mem += sizeof(struct cache_l1) * 2;
cache_option = "ram";
} else if (::strcmp("--loops", argv[i]) == 0) {
TOTAL = ::strtol(argv[++i], nullptr, 10) * 1000;
printf ("%ld loops.\n", TOTAL);
} else if (::strcmp("--align", argv[i]) == 0) {
align = true;
printf ("Align memory to 16 bytes.\n");
} else if (::strcmp("--misalign", argv[i]) == 0) {
misalign = true;
printf ("Misalign memory.\n");
} else if (::strcmp("--flush", argv[i]) == 0) {
flush = true;
printf ("Flushing caches.\n");
} else if (::strcmp("-h", argv[i]) == 0) {
printf ("There is no help here. Please put loops in units, "
"they will be multiplicated by thousands. (Default 100.000 EU separator)\n");
} else {
printf ("Unknown option: '%s', ignoring it.\n", argv[i]);
}
}
char * ch = new char[(reserve_mem * 2) + (sizeof(struct cache_l1) * 2) + 16];
struct cache_l1 * cache4 = nullptr;
struct cache_l1 * cache5 = nullptr;
if (align) {
// Align memory (void *)(((uintptr_t)ch+15) & ~ (uintptr_t)0x0F);
cache4 = (struct cache_l1 *) (((uintptr_t)ch + 15) & ~(uintptr_t)0x0F);
cache5 = (struct cache_l1 *) &cache4[reserve_mem - sizeof(struct cache_l1)];
cache5 = (struct cache_l1 *)(((uintptr_t)cache5) & ~(uintptr_t)0x0F);
} else {
cache4 = (struct cache_l1 *) ch;
cache5 = (struct cache_l1 *) &ch[reserve_mem - sizeof(struct cache_l1)];
}
if (misalign) {
cache4 = (struct cache_l1 *) ((char *)cache4 + 5);
cache5 = (struct cache_l1 *) ((char *)cache5 + 5);
}
(void)cache4;
(void)cache5;
printf ("Cache size: %ld\n", sizeof(struct cache_l1));
if (cache_option == "l1") {
// L1 doesn't allow two buffers, so same buffer
buffer_option = "samebuffer";
}
sem_t globsem;
thread th1;
thread th2;
if (same_buffer) {
printf ("Using same buffer.\n");
th1.cache = cache5;
} else {
th1.cache = cache4;
}
th2.cache = cache5;
sem_init (&globsem, 0, 0);
if (sem_init(&th1.sem, 0, 0) < 0) {
printf ("There is an error with the 1 semaphore.\n");
}
if (sem_init(&th2.sem, 0, 0) < 0) {
printf ("There is an error with the 2 semaphore.\n");
}
th1.glob = &globsem;
th2.glob = &globsem;
cpu_set_t cpuset;
int rc = 0;
pthread_create (&th1.thr, nullptr, thread_one, &th1);
CPU_ZERO (&cpuset);
CPU_SET (0, &cpuset);
rc = pthread_setaffinity_np(th1.thr,
sizeof(cpu_set_t),
&cpuset);
if (rc != 0) {
printf ("Can't change affinity of thread one!\n");
}
pthread_create (&th2.thr, nullptr, thread_two, &th2);
CPU_ZERO (&cpuset);
int cpu = 1;
if (same_core) {
printf ("Using same core. (HyperThreading)\n");
cpu = 6; // Depends on CPU topoglogy (see that with lstopo)
}
CPU_SET (cpu, &cpuset);
rc = pthread_setaffinity_np(th2.thr,
sizeof(cpu_set_t),
&cpuset);
if (rc != 0) {
printf ("Can't change affinity of thread two!\n");
}
printf ("Running in cores 0 and %d.\n", cpu);
fprintf (stderr, "Waiting 2 seconds just for threads to be ready.\n");
struct timespec time;
time.tv_sec = 2;
nanosleep (&time, nullptr);
fprintf (stderr, "Post threads to begin work %ld iterations.\n", TOTAL);
sem_post (&globsem);
sem_post (&globsem);
printf ("Waiting for thread semaphores.\n");
sem_wait (&th1.sem);
sem_wait (&th2.sem);
printf ("We don't wait anymore.\n");
printf ("Joining threads.\n");
pthread_join (th1.thr, nullptr);
pthread_join (th2.thr, nullptr);
printf ("Dumping data.\n");
file_name += core_option;
file_name += "_";
file_name += buffer_option;
file_name += "_";
file_name += cache_option;
file_name += ".log";
FILE * file = ::fopen(file_name.c_str(), "w");
if (same_buffer)
dump (file, (char *)cache5, sizeof(struct cache_l1));
else {
dump (file, (char *)cache4, sizeof(struct cache_l1));
dump (file, (char *)cache5, sizeof(struct cache_l1));
}
printf ("Exiting from main thread.\n");
return 0;
}
void * thread_one (void * data)
{
thread * th = (thread *) data;
printf ("Thread one created, pausing.\n");
if (flush)
_mm_clflush (th->cache);
sem_wait (th->glob);
printf ("Go ahead and calculate in 1...\n");
printf ("Buffer address: %p.\n", th->cache);
clock_t begin, end;
double time_spent;
register uint64_t counter = 0;
begin = clock();
for (size_t z = 0; z < TOTAL; ++z ) {
++counter;
for (int i = 0; i < 512; i += 2) {
++counter;
for (int x = 0; x < 64; ++x) {
++counter;
th->cache->cache[i].data[x] = '1';
}
}
}
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
printf ("Time 1 %f %ld\n", time_spent, counter);
sem_post (&th->sem);
return nullptr;
}
void * thread_two (void * data)
{
thread * th = (thread *) data;
printf ("Thread two created, pausing.\n");
if (flush)
_mm_clflush (th->cache);
sem_wait (th->glob);
printf ("Go ahead and calculate in 2...\n");
printf ("Buffer address: %p.\n", th->cache);
clock_t begin, end;
double time_spent;
register uint64_t counter = 0;
begin = clock();
for (size_t z = 0; z < TOTAL; ++z ) {
++counter;
for (int i = 1; i < 512; i += 2) {
++counter;;
for (int x = 0; x < 64; ++x) {
++counter;
th->cache->cache[i].data[x] = '2';
}
}
}
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
printf ("Time 2 %f %ld\n", time_spent, counter);
sem_post (&th->sem);
return nullptr;
}
void dump (FILE * file, char * buffer, size_t size)
{
size_t lines = 0;
fprintf (file, "\n");
fprintf (file, "== buffer =================================================="
"============================================================\n");
for (size_t i = 0; i < size; i += 16) {
fprintf (file, "%08ld %p ", ++lines, &buffer[i]);
for (size_t x = i; x < (i+16); ++x) {
if (buffer[x] >= 32 && buffer[x] < 127)
fprintf (file, "%c ", buffer[x]);
else
fprintf (file, ". ");
}
for (size_t x = i; x < (i+16); ++x) {
fprintf (file, "0x%02x ", buffer[x]);
}
fprintf (file, "\n");
}
fprintf (file, "== buffer =================================================="
"============================================================\n");
}
Max*_*hof 10
显然,从L1,L2,L3或RAM获取数据以进行计算没有区别.
在请求下一个级别之前,您将完全遍历每个级别(和每个页面)的每个缓存行.内存访问速度很慢,但它们并不慢,以至于您可以在下一次访问之前遍历整个页面.如果您每次访问时都要访问不同的L3缓存行或不同的RAM页面,那么您肯定会发现存在差异.但是你采用这种方式,你可以通过每个L2,L3或RAM请求之间的大量指令来完成CPU的流失,完全隐藏任何类型的缓存未命中延迟.
因此,你没有丝毫的记忆.您基本上可以使用最良好的使用模式:您的所有数据几乎一直都在缓存.有时候你会得到一个缓存未命中,但是与你使用缓存数据的时间相比,它的获取时间相形见绌.此外,您的CPU可能会预测您的(非常可预测的)使用模式,并且在您访问它之前已经预先获取了内存.
所以慢了10秒.
怎么可能?我已经知道如果高速缓存行不是脏的,它将不会从内存中获取(L1,2,3或RAM).
如上所示,您不受内存限制.你受到CPU指令流动的速度的限制(编辑:这会因禁用优化而加剧,这会使指令数量膨胀),两个超线程线程不会擅长这一点并不奇怪作为独立物理核心上的两个线程.
对于这种观察而言特别重要的是,并非所有资源都是针对每对超线程核心重复的.例如,执行端口(例如加法器,分频器,浮点单元等)不是 - 那些是共享的.以下是Skylake调度程序的示意图,用于演示以下概念:
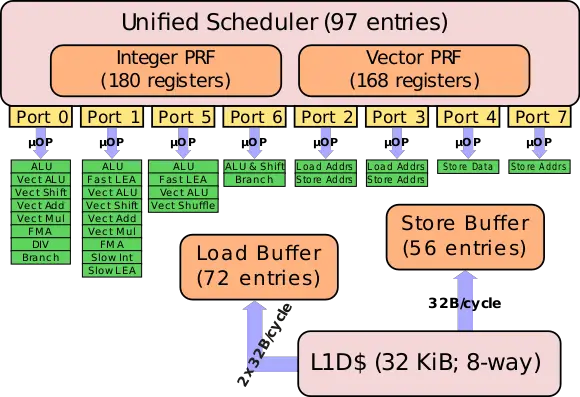
在超线程中,两个线程都必须争夺这些资源(即使是单线程程序也会因为无序执行而受到此设计的影响).此设计中有四个简单的整数ALU,但只有一个Store Data端口.因此,同一核心上的两个线程(在此Haswell CPU中)不能同时存储数据,但它们可以同时计算几个整数运算(注意:不能保证它实际上是端口4,这是争用的来源 - 一些英特尔工具可能能够为你解决这个问题).在两个不同的物理核心之间拆分负载时,不存在此限制.
在不同的物理内核之间同步L2缓存线可能会有一些开销(因为L2缓存显然不会在CPU的所有内核之间共享),但这很难从这里进行评估.
我在这个页面中找到了上面的图片,它对上面的内容进行了更深入的解释(以及更多):https://en.wikichip.org/wiki/intel/microarchitectures/skylake_ ( client)
- 如果这就是"指令管道"的意思,那么前端也不会重复.前端(解码/重命名+问题)在逻辑核心之间交替,因此物理流水线宽度仍然每个时钟只有4个融合域uop.OP的未优化代码(用`-O0`编译)存在/重载延迟的瓶颈(将循环计数器保留在内存中),因此超线程有获得总吞吐量的空间,但我想有很多浪费的指令线程竞争一些. (2认同)
- L2是Intel Sandybridge系列中的私有核心.但是OP没有*对齐*它们的缓冲区(并且它们打印地址,所以我们可以看到`malloc`保留了元数据的前16个字节),因此在每个线程中触摸交替的64字节块意味着它们必须在核心之间跳转,因为每个线程都接触每个缓存行.据推测,一个人会落后并进一步落后,直到它不再是一个问题.如果它们对齐,则相邻线L2空间预取器可能会引起问题.(当然假设这使用了16字节存储而不是1字节来使mem b/w饱和.) (2认同)