sql中的表分配和表分区有什么区别?
Ami*_*oni 3 sql database partitioning azure-sqldw azure-sql-database
我仍然在努力确定azure sql数据仓库中表分发的概念与Sql server中的表分区的概念有何不同?
两者的定义似乎都取得了相同的结果.
Azure DW具有多达60个计算节点,作为其MPP架构的一部分.在Azure DW上存储表时,您将其存储在这些节点中.您的表数据分布在这些节点上(根据您的需要使用散列分布或循环分布).您还可以选择在这些节点上复制您的表(最好是一个非常小的表).

那是分配.每个节点都有自己独特的记录,只有该节点在与数据交互时才会担心.这是一个无共享的架构.

分区完全脱离了这种分配概念.当我们对表进行分区时,我们根据某种方案决定哪些行属于哪些分区(比如order通过order.create_datefor 分区表).create_date然后,每个记录的一大块记录被存储在它自己的表中,与任何其他create_date记录集分开(在幕后无形中).
{kind=link}
分区很不错,因为您可能会发现您只想orders从表中选择10天,因此您只需要阅读10个较小的表,而不必扫描多年的order数据来查找您所追踪的10天.
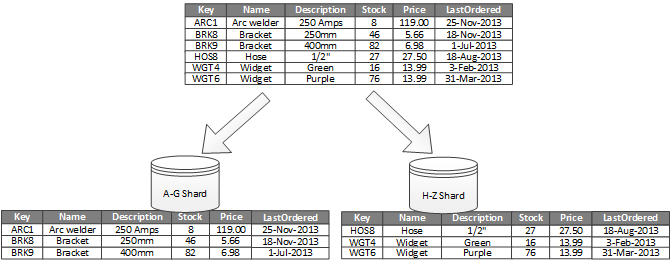
以下是Microsoft网站上的一个示例,其中对name列进行了水平分区,其中两个"分片"基于names字母顺序:

表分发是一种仅在Azure DW或Teradata等MPP类型的RDBMS上可用的概念.最容易将其视为与数据有些分离(在某种程度上)的硬件概念.Azure为您提供了很多控制权,其他MPP数据库基于主键进行分发.几乎每个RDBMS(MPP或非MPP)都可以进行分区,并且最容易将其视为由表中的数据定义并依赖于表中的数据的存储/软件概念.
最后,他们都努力解决同样的问题.但是......几乎每个RDBMS概念(索引,磁盘存储,优化,分区,分发等)都可以解决同样的问题.即:"我如何尽快获得所需的确切数据?" 当您将这些概念组合在一起以满足您的数据检索需求时,即使对于巨大的数据,您也可以快速地进行SQL请求.
只是为了好玩,让我用一个类比来解释它。
假设存在一本关于世界所有历史的巨著。它有42层楼的大小。
现在,如果图书管理员每年将该书分成 1 本书会怎样。这使得查找特定年份所需的所有信息变得更加容易。因为你可以把其他书放在书架上。
一本小书也更容易携带。
这就是表分区的意义所在。(参考:Azure 中的数据分区)
基于对大多数查询有用且具有良好平均分布的键(或列集)将数据块保存在一起。
这可以减少 IO,因为只需要访问相关的块。
现在,如果首席图书管理员解绑那本书呢?并将页面集发送到许多不同的库。当我们需要某些信息时,我们会要求每个图书馆向我们发送所需页面的副本。
更好的是,那些图书馆员已经可以总结他们页面的信息,然后只将他们的摘要发送给一个为您收集它们的图书馆。
这就是表分布的意义所在。(参考:Azure 中的表分布指南)
将数据分布在不同的节点上。
从概念上讲,它们是相同的。基本思想是数据将分布在多个存储中。然而,实施方式却截然不同。在幕后,Azure SQL 数据仓库管理和维护 70 个数据库,您定义的每个表都是在这些数据库中创建的。除了定义键之外,您什么也不做。分配得到照顾。对于分区,您必须定义和维护几乎所有内容才能使其正常工作。还有更多内容,但您已经了解了核心思想。这些是不同的过程和机制,但在宏观层面上却达到了相似的终点。然而,这些东西支持的流程非常不同。分布有助于提高性能,而分区主要是改进数据管理的一种手段(滚动窗口等)。尽管它们很相似,但它们是非常不同的事物,具有不同的意图。