Yar*_*tov 125
即使训练数据集是线性可分的,我也希望软边界SVM更好.原因在于,在边界较宽的SVM中,单个异常值可以确定边界,这使得分类器对数据中的噪声过于敏感.
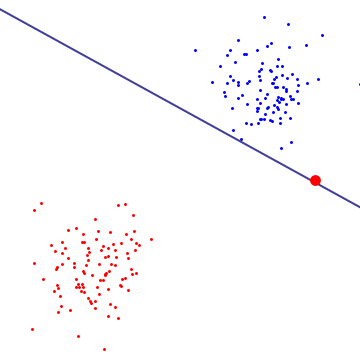
在下图中,单个红色异常值基本上决定了边界,这是过度拟合的标志
http://yaroslavvb.com/upload/save/so-svm.png
为了了解软边界SVM正在做什么,最好在双重公式中查看它,在那里您可以看到它具有与硬边界SVM相同的保证金最大化目标(保证金可能为负),但是附加约束条件是与支持向量相关联的每个拉格朗日乘数都受到C的限制.本质上,这限制了任何单个点对决策边界的影响,对于推导,参见Cristianini/Shaw-Taylor的"支持向量导论"中的命题6.12机器和其他基于内核的学习方法".
结果是软边界SVM可以选择具有非零训练误差的决策边界,即使数据集是线性可分的,并且不太可能过度拟合.
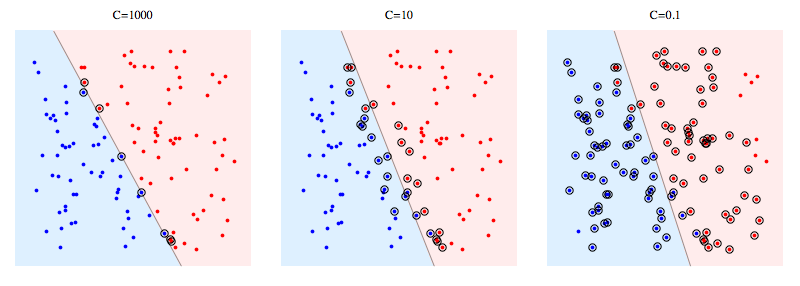
这是一个在合成问题上使用libSVM的示例.圆圈点显示支持向量.您可以看到,降低C导致分类器牺牲线性可分性以获得稳定性,在某种意义上,任何单个数据点的影响现在都受到C的限制.
http://yaroslavvb.com/upload/save/so-libsvm.png
支持向量的含义:
对于硬边距SVM,支持向量是"在边缘上"的点.在上面的图片中,C = 1000非常接近硬边距SVM,你可以看到带圆圈的点是那些将触及边距的点(该图中的边距几乎为0,因此它与分离超平面基本相同) )
对于软边距SVM,用双变量来解释它们更容易.根据双变量,您的支持向量预测器是以下函数.
http://yaroslavvb.com/upload/save/so-svm-dual.png
这里,alphas和b是在训练过程中找到的参数,xi,yi是你的训练集,x是新的数据点.支持向量是来自训练集的数据点,其包括在预测器中,即具有非零α参数的数据点.
小智 5
在我看来,Hard Margin SVM 对特定数据集过度拟合,因此无法泛化。即使在线性可分的数据集中(如上图所示),边界内的异常值也会影响边缘。Soft Margin SVM 具有更多的通用性,因为我们可以通过调整 C 来控制选择支持向量。
{kind=link}
{kind=link}
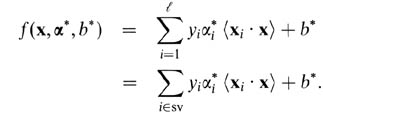{kind=link}