SQLite - UPSERT*不*INSERT或REPLACE
Mik*_*der 505 sql sqlite upsert
http://en.wikipedia.org/wiki/Upsert
在SQLite中有没有一些我没想到的聪明方法?
基本上,如果记录存在,我想更新四列中的三列,如果它不存在,我想用第四列的默认(NUL)值插入记录.
ID是主键,因此UPSERT只会有一条记录.
(我试图避免SELECT的开销,以确定我是否需要更新或插入显然)
建议?
我无法在SQLite网站上确认SQL CREATE的语法.我还没有构建一个演示来测试它,但它似乎不支持..
如果是,我有三列,所以它实际上看起来像:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
但是前两个blob不会引起冲突,只有ID会因此我asusme Blob1和Blob2不会被替换(根据需要)
绑定数据时SQLite中的UPDATE是一个完整的事务,这意味着每个要更新的发送行都需要:Prepare/Bind/Step/Finalize语句,与允许使用重置函数的INSERT不同
语句对象的生命周期如下:
- 使用sqlite3_prepare_v2()创建对象
- 使用sqlite3_bind_接口将值绑定到主机参数.
- 通过调用sqlite3_step()运行SQL
- 使用sqlite3_reset()重置语句,然后返回步骤2并重复.
- 使用sqlite3_finalize()销毁语句对象.
更新我猜测与INSERT相比速度慢,但它与使用主键的SELECT相比如何呢?
也许我应该使用select来读取第4列(Blob3),然后使用REPLACE编写一条新记录,将原始的第4列与前3列的新数据混合在一起?
小智 832
假设表中有3列.. ID,NAME,ROLE
BAD:这将使用ID = 1的新值插入或替换所有列:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
坏:这将插入或替换2列...... NAME列将设置为NULL或默认值:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
好的:这将更新2列.当ID = 1时,NAME将不受影响.当ID = 1不存在时,名称将为默认值(NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
这将更新2列.当ID = 1时,ROLE将不受影响.当ID = 1不存在时,角色将设置为"Benchwarmer"而不是默认值.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
- 这很伤人.SQlite需要UPSERT. (243认同)
- +1精彩!如果需要组合/比较任何字段的旧值和新值,嵌入式select子句使您可以灵活地覆盖默认的ON CONFLICT REPLACE功能. (32认同)
- 如果具有级联删除的其他行引用了Employee,则仍将通过替换删除其他行. (23认同)
- 你能解释一下为什么*这将插入或替换ID = 1的新值的所有列:*在你的第一个例子中被认为是*BAD*?您在那里出现的命令是为了创建一个ID为1,名称为*John Foo*和role*CEO*的新记录,或者使用该数据覆盖ID为1的记录(如果已经存在)(假设为*id)*是主键).那么,如果恰好发生这种情况,为什么不好呢? (18认同)
- @Cornelius:很清楚,但这不是第一个例子中发生的事情.第一个示例是强制设置所有列,无论是插入还是替换记录,都会发生这种情况.那么,为什么这被认为是坏的?链接的答案也只指出了为什么在指定列的子集时会发生不好的事情,例如在你的*second*例子中; 在指定*all*列的值时,它似乎没有详细说明在你的*第一个*示例,`INSERT OR REPLACE`中发生的任何不良影响. (9认同)
- 最后一个查询不正确.它应该是:coalesce((从员工中选择id = 1的角色),'Benchwarmer') (8认同)
- 劫持最高评论:[UPSERT现在由SQLite正式支持](/sf/answers/3520813061/) (5认同)
- 向子查询添加一个limit子句:从Employee中选择名称,其中id = 1 limit 1.尽管SQLite可能不会在此处引发错误,但最好这样做,因为其他SQL方言确实需要这样的限制. (3认同)
- 这很糟糕,因为后面的例子允许"如果未设置此属性,则将其设置为此值,否则将其保留为".不同之处在于,一个强制覆盖所有值,而另一个允许对覆盖的内容进行更细粒度的控制,以及在插入时仅设置的内容.想一想:更新超级管理员用户的用户记录."如果用户不存在,我将他的等级设置为'新手',否则我保持他的等级(超级管理员,这里)." 让你的管理员成为新手用户并不好.</ contrived example> :)另见http://stackoverflow.com/a/4253806/122764. (3认同)
- 为什么不添加示例查询以获得最佳解决方案? (2认同)
gre*_*lom 127
INSERT或REPLACE 不等同于"UPSERT".
假设我有表Employee,其中包含字段id,name和role:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom,你已经丢失了员工编号1的名称.SQLite已将其替换为默认值.
UPSERT的预期输出是改变角色并保留名称.
- 确实.埃里克绝对是最好的答案,值得更多的选票.话虽这么说,我认为通过指出问题,我已经贡献了一点点来找到好的答案(Eric的答案后来出现,并建立在我的答案中的示例sql表).所以不确定我是否应该得到-1,但没关系:) (20认同)
- -1恐怕我来自我 是的,接受的答案是错误的,但是当你的答案指出问题时,它也不是答案.有关实际答案,请参阅[Eric B的聪明解决方案](http://stackoverflow.com/questions/418898/sqlite-upsert-not-insert-or-replace/4330694#4330694)使用嵌入式`coalesce((选择. .),'新值')`条款.我想,埃里克的回答需要更多的选票. (18认同)
- +1以抵消上面的-1.大声笑.虽然这个线程有趣的时间表.显然你的答案是在埃里克的前一个星期,但是在你问到这两年后你们都回答了这个问题.埃里克也为+1精心制作. (5认同)
- @QED 否,因为删除 + 插入(这是一个替换)是 2 条 dml 语句,例如带有它们自己的触发器。它与仅 1 个更新语句不同。 (2认同)
Ari*_*zis 106
如果你想保留现有行中的一列或两列,Eric B的答案是可以的.如果你想保留很多列,它会变得太麻烦.
这是一种可以很好地扩展到任何一侧任意数量的列的方法.为了说明它,我将假设以下架构:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
特别注意,这name是行的自然键 - id仅用于外键,因此SQLite在插入新行时自行选择ID值.但是当基于它更新现有行时name,我希望它继续具有旧的ID值(显然!).
我UPSERT使用以下构造实现了一个真实的:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
此查询的确切形式可能有所不同.关键是使用INSERT SELECT左外连接,将现有行连接到新值.
在这里,如果行以前不存在,old.id会NULL再SQLite的会自动分配一个ID,但如果已经有了这样的行,old.id将有一个实际值,这将被重用.这正是我想要的.
实际上这非常灵活.请注意ts列的各个方面是如何完全丢失的 - 因为它有一个DEFAULT值,SQLite在任何情况下都会做正确的事情,所以我不必自己处理它.
您还可以同时在一列new和old面,然后用如COALESCE(new.content, old.content)在外SELECT说"插入新的内容,如果有任何,否则保留旧的内容" -例如,如果您使用的是固定的查询,并结合新的带占位符的值.
- +1,效果很好,但在`SELECT ... AS old`上添加一个`WHERE name ="about"约束来加快速度.如果你有1米+行,这是非常慢的. (11认同)
- 你可以简化亚里士多德的例子,如果你想:`INSERT OR REPLACE INTO页面(id,name,title,content,author)SELECT id,'about','About this site',content,42 FROM(SELECT NULL )LEFT JOIN(SELECT*FROM page WHERE name ='about')` (3认同)
- 这不会在执行替换(即更新)时不必要地触发`ON DELETE`触发器吗? (3认同)
- 它肯定会触发“ ON DELETE”触发器。邓诺关于不必要的。对于大多数用户而言,这可能是不必要的,甚至是不必要的,但可能并非对所有用户而言。同样,由于它还会将带有外键的任何行级联删除到所讨论的行中,这可能是许多用户遇到的问题。不幸的是,SQLite离真正的UPSERT更近了。(我猜是用“ INSTEAD OF UPDATE”触发器来伪造它的。) (2认同)
Sam*_*ron 81
如果你一般都在做更新,我会..
- 开始交易
- 做更新
- 检查rowcount
- 如果为0则执行插入操作
- 承诺
如果你通常做插入我会
- 开始交易
- 尝试插入
- 检查主键冲突错误
- 如果我们得到错误,请进行更新
- 承诺
这样你就可以避免选择,并且你在Sqlite上具有事务性.
- 我真的希望INSERT或UPDATE是该语言的一部分 (19认同)
- 如果您要在第3步使用sqlite3_changes()检查rowcount,请确保不要使用来自多个线程的DB句柄进行修改. (3认同)
- 下面的内容不会更加冗长,具有相同的效果:1)选择id表格表,其中id ='x'2)if(ResultSet.rows.length == 0)更新表,其中id ='x'; (2认同)
Ant*_*ert 78
2018-05-18 STOP PRESS.
在SQLite中支持UPSERT!UPSERT语法已添加到SQLite版本3.24.0(待定)!
UPSERT是INSERT的一种特殊语法添加,如果INSERT违反唯一性约束,则会导致INSERT表现为UPDATE或no-op.UPSERT不是标准SQL.SQLite中的UPSERT遵循PostgreSQL建立的语法.

我知道我迟到了,但......
__PRE__
因此它会尝试更新,如果记录在那里则插入不会被动作.
或者:
另一种完全不同的方法是:在我的应用程序中,当我在内存中创建行时,我将内存rowID设置为long.MaxValue.(MaxValue将永远不会被用作ID,你将不会活得足够长....然后如果rowID不是那个值,那么它必须已经在数据库中,所以如果它是MaxValue需要更新,那么它需要插入.这仅在您可以跟踪应用中的rowID时有用.
- 阿门.简单比复杂更好.这比接受的答案要简单一些. (4认同)
- @CharlieMartin是对的.此语法对于SQLite无效 - 这是OP请求的内容.`WHERE`子句不能附加到`INSERT`语句:[sqlite-insert](https://sqlite.org/lang_insert.html)... (4认同)
- 我以为你不能INSERT INTO ...在sqlite中哪里?这是sqlite3中的语法错误 (3认同)
- 这个答案让我花了很多时间,问题是关于SQLITE,我不知道sqite不支持INSERT WHERE,**请在你的答案中添加此注释,它对sqlite无效** (3认同)
- @colminator和其他人:我根据您的建议修复了他的SQL语句。 (2认同)
Chr*_*los 59
我意识到这是一个旧线程,但我最近一直在sqlite3中工作,并提出了这个方法,它更适合我动态生成参数化查询的需求:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
它仍然是2个查询,在更新中有一个where子句,但似乎可以解决问题.我也有这样的想法,如果对changes()的调用大于零,sqlite可以完全优化更新语句.它是否真的这样做是我所不知道的,但是一个人可以梦想不能吗?;)
对于奖励积分,您可以附加此行,该行返回行的ID,无论是新插入的行还是现有行.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Dav*_*err 13
这是一个真正的UPSERT(UPDATE或INSERT)而不是INSERT OR REPLACE(在许多情况下工作方式不同)的解决方案.
它的工作方式如下:
1.尝试更新具有相同Id的记录是否存在.
2.如果更新未更改任何行(NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0)),则插入记录.
因此,要么更新现有记录,要么执行插入.
重要的细节是使用changes()SQL函数来检查update语句是否命中了任何现有记录,如果没有命中任何记录,则只执行insert语句.
有一点需要注意的是,changes()函数不会返回由较低级别触发器执行的更改(请参阅http://sqlite.org/lang_corefunc.html#changes),因此请务必将其考虑在内.
这是SQL ...
测试更新:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
测试插页:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
- 这对我来说似乎比Eric更好.但是`INSERT INTO Contact(Id,Name)SELECT 3,'Bob'WHERERE changes()= 0;``也应该有效. (2认同)
从3.24.0版本开始,SQLite支持UPSERT。
从文档中:
UPSERT是INSERT的特殊语法补充,如果INSERT违反唯一性约束,则它会使INSERT表现为UPDATE或no-op。UPSERT不是标准的SQL。SQLite中的UPSERT遵循PostgreSQL建立的语法。UPSERT语法已添加到SQLite版本3.24.0(待定)中。
UPSERT是普通的INSERT语句,后跟特殊的ON CONFLICT子句
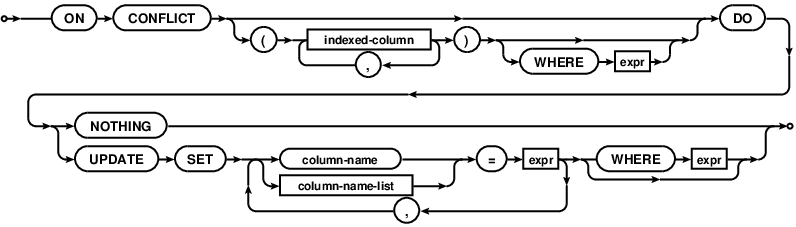
图片来源:https : //www.sqlite.org/images/syntax/upsert-clause.gif
- 截至 API 27,Android 仍为 3.19 (3认同)
您确实可以在SQLite中进行更新,它看起来与您习惯的有所不同。它看起来像:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
- 这其实是错误的。它应该是这样的:`INSERT INTO table_name (id, column1, column2) VALUES (123, 'value1', 'value2') ON CONFLICT (id) DO UPDATE SET column1 = 'value1', column2 = 'value2'` (3认同)
我所知道的最好的方法是进行更新,然后进行插入。“选择的开销”是必要的,但这并不是一个可怕的负担,因为您正在搜索主键,这很快。
您应该能够使用您的表和字段名称修改以下语句以执行您想要的操作。
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
小智 5
扩展亚里士多德的答案,你可以从一个虚拟的'singleton'表中选择(一个你自己创建的表,只有一行).这避免了一些重复.
我还将示例保持在MySQL和SQLite之间,并使用'date_added'列作为如何仅在第一次设置列时的示例.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
| 归档时间: |
|
| 查看次数: |
277859 次 |
| 最近记录: |