在Python中展平浅层列表
Pra*_*ogg 382 python list-comprehension
是否有一种简单的方法可以使用列表推导来展平迭代列表,或者失败,你会认为什么是平衡这样的浅层列表,平衡性能和可读性的最佳方法?
我尝试使用嵌套列表理解来压缩这样的列表,如下所示:
[image for image in menuitem for menuitem in list_of_menuitems]
但我在NameError那里遇到麻烦,因为name 'menuitem' is not defined.谷歌搜索并浏览Stack Overflow后,我得到了一个reduce声明所需的结果:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
但是这个方法相当难以理解,因为我需要那个list(x)调用,因为x是一个Django QuerySet对象.
结论:
感谢所有为此问题做出贡献的人.以下是我学到的内容摘要.我也将其作为社区维基,以防其他人想要添加或更正这些观察结果.
我原来的reduce语句是多余的,用这种方式编写得更好:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
这是嵌套列表理解的正确语法(Brilliant summary dF!):
>>> [image for mi in list_of_menuitems for image in mi]
但这些方法都不如使用效率高itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
正如@cdleary指出的那样,通过使用chain.from_iterable如下所示来避免*操作符魔术可能是更好的风格:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
cdl*_*ary 293
如果您只是想要迭代数据结构的扁平化版本并且不需要可索引序列,请考虑使用itertools.chain和company.
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
它将适用于任何可迭代的东西,其中应包括Django的可迭代QuerySets,它似乎是你在问题中使用的.
编辑:无论如何,这可能与reduce一样好,因为reduce会将项目复制到正在扩展的列表中.chain如果你list(chain)在最后运行,只会产生这个(相同的)开销.
元编辑:实际上,它比问题的建议解决方案的开销更少,因为当您使用临时扩展原始文件时,您会丢弃您创建的临时列表.
编辑:正如JF Sebastian所说, itertools.chain.from_iterable避免拆包,你应该使用它来避免*魔术,但timeit应用程序显示可忽略不计的性能差异.
dF.*_*dF. 268
你几乎拥有它!该做的嵌套列表理解的方式是把for语句以相同的顺序,因为他们会去正规的嵌套for语句.
因此,这
for inner_list in outer_list:
for item in inner_list:
...
对应于
[... for inner_list in outer_list for item in inner_list]
所以你要
[image for menuitem in list_of_menuitems for image in menuitem]
- +1,我看了很多次,这是我见过的唯一一个明确排序的答案......也许现在我记得了! (40认同)
- 我希望我能再次投票,因为这种思维方式使得嵌套列表理解更容易理解. (9认同)
- 这个顺序“真的”很奇怪。如果将 `for i in list: ...` 更改为 `... for i in list`,那么为什么不更改 for 循环的顺序呢? (2认同)
cdl*_*ary 125
@ S.Lott:你激励我写一个timeit app.
我认为它也会根据分区数量(容器列表中的迭代器数量)而有所不同 - 您的评论没有提到30个项目中有多少个分区.这个图在每次运行中展平了一千个项目,分区数量不同.项目均匀分布在分区中.
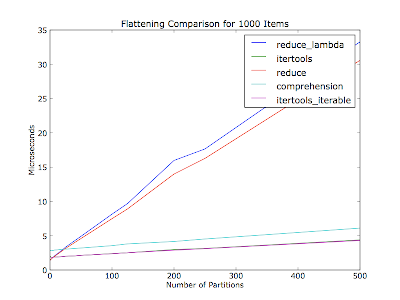
代码(Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
编辑:决定使其成为社区维基.
注意: METHODS应该与装饰者积累,但我认为人们更容易阅读这种方式.
- 或者只是总和(list,[]) (17认同)
- 我知道这是一个旧线程,但我添加了一个从[here](http://stackoverflow.com/a/5330178/2069974)获得的方法,该方法使用list.extend,它已经证明是最快的.[图](https://www.dropbox.com/s/lb7yojmcckndojm/flatten_graph.png)[更新的要点](https://gist.github.com/mshuffett/5316046) (3认同)
- 如果有很多分区,`chain.from_iterable()`会稍快一点http://i403.photobucket.com/albums/pp111/uber_ulrich/p10000.png (2认同)
Pre*_*and 46
sum(list_of_lists, []) 会使它变平.
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
Jam*_*ady 38
此解决方案适用于任意嵌套深度 - 不仅仅是"列表列表"深度,其他解决方案的一些(全部?)仅限于:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
它是允许任意深度嵌套的递归 - 直到你达到最大递归深度,当然......
- 这对我来说最有用,因为它不会分隔字符串. (3认同)
S.L*_*ott 23
表现结果.修订.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
我将30个项目的2级列表展平1000次
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
减少总是一个糟糕的选择.
- `map(lambda x:list(x),[mi in aList]))``是`map(list,aList)`. (4认同)
jfs*_*jfs 23
在Python 2.6中,使用chain.from_iterable():
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
它避免了创建中间列表.
Mei*_*ham 14
似乎有一种混乱operator.add!当您将两个列表一起添加时,正确的术语是concat,而不是添加.operator.concat是你需要使用的.
如果您正在考虑功能,它就像这样简单::
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
你看到reduce尊重序列类型,所以当你提供一个元组时,你会得到一个元组.让我们尝试一下清单::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
啊哈,你得到一份清单.
性能怎么样::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable非常快!但是用concat减少它是不可比的.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
在我的头顶,你可以消除lambda:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
或者甚至消除地图,因为你已经有了list-comp:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
您也可以将其表达为列表总和:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
- 这不是多余的.默认值为零,产生TypeError:+:'int'和'list'的不支持的操作数类型.IMO sum()比reduce更直接(add,...) (2认同)
这是使用列表推导的正确解决方案(它们在问题中是向后的):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
在你的情况下,它会
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
或者你可以使用join和说
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
在任何一种情况下,陷阱都是for循环的嵌套.
| 归档时间: |
|
| 查看次数: |
167081 次 |
| 最近记录: |