如何扇出AWS kinesis流?
Gil*_*hum 11 amazon-web-services amazon-kinesis
我想扇出/链接/复制输入AWS Kinesis流到N个新的Kinesis流,以便写入输入Kinesis的每个记录将出现在N个流中的每个流中.
是否有AWS服务或开源解决方案?
如果有现成的解决方案,我宁愿不编写代码来做到这一点.AWS Kinesis firehose是无法解决的,因为它无法输出到kinesis.也许AWS Lambda解决方案如果运行起来不会太昂贵?
Joh*_*ein 17
有两种方法可以完成Amazon Kinesis流的扇出:
- 使用Amazon Kinesis Analytics将记录复制到其他流
- 触发AWS Lambda函数以将记录复制到另一个流
选项1:使用Amazon Kinesis Analytics进行扇出
您可以使用Amazon Kinesis Analytics从现有流生成新流.
Amazon Kinesis Analytics应用程序可以实时连续读取和处理流数据.您使用SQL编写应用程序代码来处理传入的流数据并生成输出.然后,Amazon Kinesis Analytics 将输出写入已配置的目标.
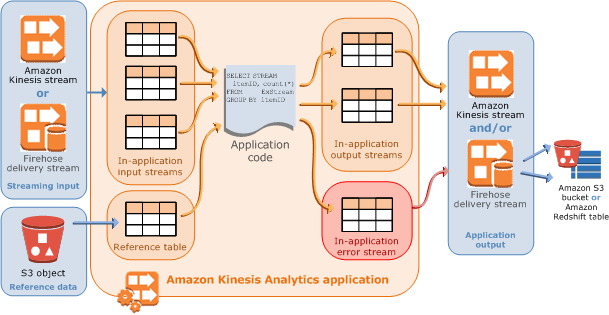
" 应用程序代码"部分提到了扇出:
您还可以编写彼此独立运行的SQL查询.例如,您可以编写两个SQL语句来查询相同的应用程序内部流,但将输出发送到不同的应用程序内部流.
我设法实现如下:
- 创建了三个流:input,output1,output2
- 创建了两个Amazon Kinesis Analytics应用程序:copy1,copy2
Amazon Kinesis Analytics SQL应用程序如下所示:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM"
(log VARCHAR(16));
CREATE OR REPLACE PUMP "COPY_PUMP1" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "log" FROM "SOURCE_SQL_STREAM_001";
此代码创建一个泵(将其视为连续的select语句),从input流中选择并输出到output1流.我创建了另一个输出到output2流的相同应用程序.
为了测试,我将数据发送到input流:
#!/usr/bin/env python
import json, time
from boto import kinesis
kinesis = kinesis.connect_to_region("us-west-2")
i = 0
while True:
data={}
data['log'] = 'Record ' + str(i)
i += 1
print data
kinesis.put_record("input", json.dumps(data), "key")
time.sleep(2)
我让它运行一段时间,然后使用以下代码显示输出:
from boto import kinesis
kinesis = kinesis.connect_to_region("us-west-2")
iterator = kinesis.get_shard_iterator('output1', 'shardId-000000000000', 'TRIM_HORIZON')['ShardIterator']
records = kinesis.get_records(iterator, 5)
print [r['Data'] for r in records['Records']]
输出是:
[u'{"LOG":"Record 0"}', u'{"LOG":"Record 1"}', u'{"LOG":"Record 2"}', u'{"LOG":"Record 3"}', u'{"LOG":"Record 4"}']
我再次运行它output2,显示相同的输出.
选项2:使用AWS Lambda
如果您要扇动到许多流,则可以使用更有效的方法来创建AWS Lambda函数:
- 由Amazon Kinesis流记录触发
- 这会将记录写入多个Amazon Kinesis的"输出"流
您甚至可以让Lambda函数根据命名约定(例如,任何名为的流app-output-*)自行发现输出流.
- 您也可以使用相同的Kinesis Analytics应用程序并向其添加两个输出流:) (2认同)
| 归档时间: |
|
| 查看次数: |
5356 次 |
| 最近记录: |