在数组中搜索标量时,Perl的smartmatch运算符有多快?
我想重复搜索不会更改的数组中的值.
到目前为止,我一直在这样做:我把值放在一个哈希(所以我有一个数组和一个基本相同内容的哈希),然后我使用搜索哈希exists.
我不喜欢有两个不同的变量(数组和散列)都存储相同的东西; 但是,哈希搜索速度要快得多.
我发现~~Perl 5.10 中有一个(smartmatch)运算符.在数组中搜索标量时效率如何?
bri*_*foy 39
如果要在数组中搜索单个标量,可以使用List :: Util的first子例程.一旦知道答案,它就会停止.如果您已经拥有哈希值,我不希望这比哈希查找更快,但是当您考虑创建哈希并将其存储在内存中时,您可能更方便地搜索已有的数组.
至于智能匹配运营商的聪明才智,如果你想看看它有多聪明,那就试试吧.:)
至少有三种情况需要检查.最糟糕的情况是,您想要找到的每个元素都在最后.最好的情况是,您要查找的每个元素都在开头.可能的情况是,您想要找到的元素平均在中间.
现在,在我开始这个基准测试之前,我希望如果智能匹配可以短路(并且它可以;它在perlsyn中记录),尽管阵列大小最好,但最好的情况时间将保持不变,而其他的变得越来越差.如果它不能短路并且每次都必须扫描整个阵列,那么时间应该没有区别,因为每种情况都涉及相同的工作量.
这是一个基准:
#!perl
use 5.12.2;
use strict;
use warnings;
use Benchmark qw(cmpthese);
my @hits = qw(A B C);
my @base = qw(one two three four five six) x ( $ARGV[0] || 1 );
my @at_end = ( @base, @hits );
my @at_beginning = ( @hits, @base );
my @in_middle = @base;
splice @in_middle, int( @in_middle / 2 ), 0, @hits;
my @random = @base;
foreach my $item ( @hits ) {
my $index = int rand @random;
splice @random, $index, 0, $item;
}
sub count {
my( $hits, $candidates ) = @_;
my $count;
foreach ( @$hits ) { when( $candidates ) { $count++ } }
$count;
}
cmpthese(-5, {
hits_beginning => sub { my $count = count( \@hits, \@at_beginning ) },
hits_end => sub { my $count = count( \@hits, \@at_end ) },
hits_middle => sub { my $count = count( \@hits, \@in_middle ) },
hits_random => sub { my $count = count( \@hits, \@random ) },
control => sub { my $count = count( [], [] ) },
}
);
这是各个部分的作用.请注意,这是两个轴上的对数图,因此切入线的斜率不如它们看起来那么接近:
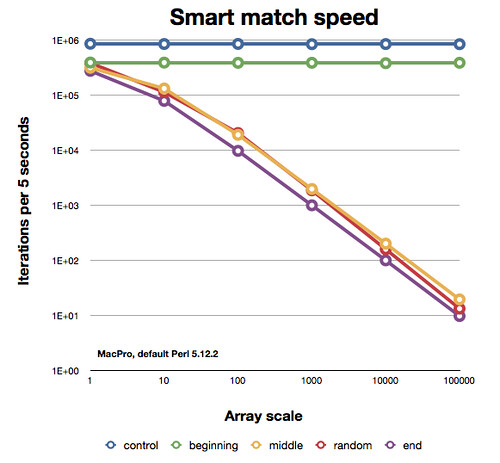
因此,看起来智能匹配运算符有点聪明,但这并不能真正帮助您,因为您仍可能需要扫描整个阵列.你可能不知道你会在哪里找到你的元素.我希望哈希将与最佳案例智能匹配相同,即使你必须放弃一些内存.
好的,所以智能匹配是智能时代的两个很好,但真正的问题是"我应该使用它吗?".另一种方法是哈希查找,我一直在烦恼,我没有考虑过这种情况.
与任何基准测试一样,我开始考虑在实际测试之前结果可能是什么.我希望如果我已经有了哈希,那么查找一个值就会很快.那个案子不是问题.我对我还没有哈希的情况更感兴趣.我能以多快的速度进行哈希并查找密钥?我希望表现得不是那么好,但它仍然比最坏情况的智能比赛更好吗?
但是,在您看到基准测试之前,请记住,通过查看数字,几乎从来没有足够的信息来说明您应该使用哪种技术.问题的背景选择最好的技术,而不是最快的,无环境的微基准.考虑一些可以选择不同技术的案例:
- 您将重复搜索一个阵列
- 你总是得到一个你只需要搜索一次的新数组
- 你得到非常大的数组,但内存有限
现在,记住这些,我添加到我以前的程序:
my %old_hash = map {$_,1} @in_middle;
cmpthese(-5, {
...,
new_hash => sub {
my %h = map {$_,1} @in_middle;
my $count = 0;
foreach ( @hits ) { $count++ if exists $h{$_} }
$count;
},
old_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ if exists $old_hash{$_} }
$count;
},
control_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ }
$count;
},
}
);
这是情节.颜色有点难以区分.最低的行是您必须在任何时候搜索它时创建哈希的情况.那很糟糕.最高的两条(绿色)线是散列的控件(实际上没有散列)和现有的散列查找.这是一个对数/对数图; 这两种情况甚至比智能匹配控制(只调用子程序)更快.

还有一些其他注意事项."随机"案例的行有点不同.这是可以理解的,因为每个基准测试(因此,每个数组规模运行一次)随机将命中元素放置在候选数组中.有些运行会稍微提前一些,稍后会有一些运行,但由于我@random每次运行整个程序时只运行一次,所以它们会稍微移动一下.这意味着线路中的凸起并不重要.如果我尝试了所有位置并取平均值,我希望"随机"线与"中间"线相同.
现在,看看这些结果,我会说在最糟糕的情况下,智能匹配比最坏情况下的哈希查找要快得多.那讲得通.要创建一个哈希,我必须访问数组的每个元素,并制作哈希,这是很多复制.聪明的比赛没有复制.
这是我不会检查的另一个案例.哈希何时变得比智能匹配更好?也就是说,什么时候创建散列的开销在重复搜索中分散得足够多,那么散列是更好的选择?
hob*_*bbs 10
快速进行少量潜在匹配,但不比哈希更快.哈希真的是测试集合成员资格的正确工具.由于散列访问是O(log n),并且阵列上的smartmatch仍然是O(n)线性扫描(尽管是短路的,与grep不同),在允许的匹配中具有更大数量的值,smartmatch变得相对更差.
基准代码(与3个值匹配):
#!perl
use 5.12.0;
use Benchmark qw(cmpthese);
my @hits = qw(one two three);
my @candidates = qw(one two three four five six); # 50% hit rate
my %hash;
@hash{@hits} = ();
sub count_hits_hash {
my $count = 0;
for (@_) {
$count++ if exists $hash{$_};
}
$count;
}
sub count_hits_smartmatch {
my $count = 0;
for (@_) {
$count++ when @hits;
}
$count;
}
say count_hits_hash(@candidates);
say count_hits_smartmatch(@candidates);
cmpthese(-5, {
hash => sub { count_hits_hash((@candidates) x 1000) },
smartmatch => sub { count_hits_smartmatch((@candidates) x 1000) },
}
);
基准测试结果:
Rate smartmatch hash
smartmatch 404/s -- -65%
hash 1144/s 183% --
"智能匹配"中的"智能"与搜索无关.它是基于上下文在正确的时间做正确的事情.
是否更快将循环数组或索引循环到散列中的问题是您必须进行基准测试的问题,但总的来说,它必须是一个非常小的数组,以便更快地浏览而不是索引到散列.