Kar*_*lek 3 unicode perl utf-8
我有一个外部模块,它返回一些字符串.我不确定字符串是如何返回的.我真的不知道,Unicode字符串是如何工作的以及为什么.
例如,该模块应返回捷克语单词"být",意思是"待定".(如果你看不到第二个字母 - 它应该是这样的.)如果我显示模块返回的字符串,使用Data Dumper,我将其视为b\x{fd}t.
但是,如果我尝试打印它print $s,我会得到"宽字符打印"警告,并且?而不是ý.
如果我尝试Encode::decode(whatever, $s);,无论如何都不能打印结果字符串(总是带有"宽字符"警告,有时带有损坏的字符,有时是正确的),无论我放入什么whatever.
如果我尝试Encode::encode("utf-8", $s);,可以打印生成的字符串,没有问题或错误消息.
如果我使用use encoding 'utf8';,打印工作,无需编码/解码.但是,如果我使用IO::CaptureOutput或Capture::Tiny模块,它会再次开始喊"宽字符".
我有几个问题,主要是关于究竟发生了什么.(我试着阅读perldocs,但我不是很聪明)
use encoding做什么的?为什么默认编码不同utf-8?编辑:有人告诉我使用-C或binmode或PERL_UNICODE.这是一个很好的建议.然而,不知何故,两个捕获模块都神奇地破坏了STDOUT的UTF8-ness.这似乎是模块的一个错误,但我不太确定.
edit2:好的,最好的解决方案是转储模块并自己编写"捕获"(灵活性更低).
decode函数将假定为ENCODING的字节序列解码为Perl的内部形式(utf8).您的输入似乎已经解码,encode()函数将Perl内部形式的字符串编码为ENCODING.encoding编译指示允许您以您喜欢的任何编码编写脚本.字符串文字自动转换为perl的内部形式.另请参阅perluniintro,perlunicode,Encode模块,binmode()函数.
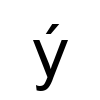{kind=link}