use*_*ser 34 python bayesian bayesian-networks
这就是我问这个问题的原因: 去年我制作了一些C++代码来计算特定类型模型的后验概率(由贝叶斯网络描述).该模型工作得很好,其他一些人开始使用我的软件.现在我想改进我的模型.由于我已经为新模型编写了略微不同的推理算法,因此我决定使用python,因为运行时并不重要,python可以让我制作更优雅和易于管理的代码.
通常在这种情况下我会在python中搜索现有的贝叶斯网络包,但我正在使用的推理算法是我自己的,我也认为这将是一个很好的机会,可以在python中学习更多有关优秀设计的知识.
我已经为网络图(networkx)找到了一个很棒的python模块,它允许你将字典附加到每个节点和每个边缘.从本质上讲,这将让我给出节点和边缘属性.
对于特定网络及其观察数据,我需要编写一个函数来计算模型中未分配变量的可能性.
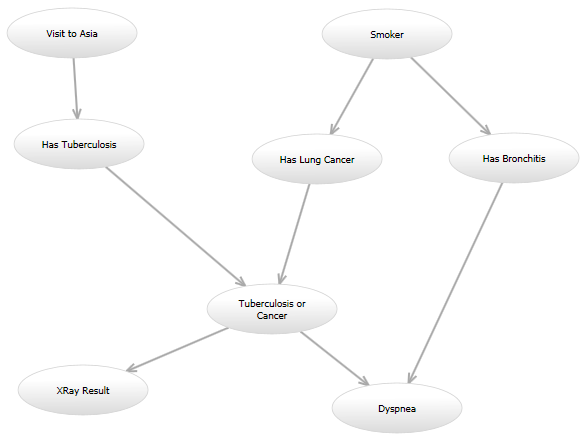
例如,在经典的"亚洲"网络(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png)中,以"XRay Result"和"Dyspnea"状态着称,我需要编写一个函数计算其他变量具有某些值的可能性(根据某些模型).
这是我的编程问题: 我将尝试一些模型,将来我可能会想要尝试另一种模型.例如,一个模型看起来可能与亚洲网络完全一样.在另一个模型中,可以从"访问亚洲"到"有肺癌"添加有针对性的边缘.另一个模型可能使用原始有向图,但给定"肺结核或癌症"和"支气管炎"节点的"呼吸困难"节点的概率模型可能不同.所有这些模型都将以不同的方式计算可能性.
所有模型都会有很大的重叠; 例如,如果所有输入都为"0",则进入"或"节点的多个边将始终为"0",否则为"1".但是一些模型将具有在某个范围内采用整数值的节点,而其他模型将是布尔值.
在过去,我一直在努力解决如何编程这样的事情.我不会撒谎; 有相当数量的复制和粘贴代码,有时我需要将单个方法中的更改传播到多个文件.这次我真的想花时间以正确的方式做到这一点.
一些选择:
非常感谢你的帮助.
Update: Object oriented ideas help a lot here (each node has a designated set of predecessor nodes of a certain node subtype, and each node has a likelihood function that computes its likelihood of different outcome states given the states of the predecessor nodes, etc.). OOP FTW!
小智 22
我在业余时间一直在研究这种事情已有一段时间了.我想我现在正处于同一问题的第三或第四版.我实际上准备发布另一个版本的Fathom(https://github.com/davidrichards/fathom/wiki),其中包含动态贝叶斯模型和不同的持久层.
因为我试图澄清我的答案,所以它已经很长了.我为此道歉.这就是我一直在攻击这个问题的方法,它似乎回答了你的一些问题(有点间接):
我开始研究Judea Pearl在贝叶斯网络中对信念传播的破坏.也就是说,它是来自父母的先前赔率(因果支持)和来自儿童的可能性(诊断支持)的图表.通过这种方式,基本类只是一个BeliefNode,就像你在BeliefNodes,LinkMatrix之间的额外节点所描述的那样.通过这种方式,我明确地选择了我使用的LinkMatrix类型的可能性类型.它可以更容易地解释信任网络之后正在做什么以及使计算更简单.
我对基本BeliefNode进行的任何子类化或更改都将用于对连续变量进行分级,而不是更改传播规则或节点关联.
我决定将所有数据保存在BeliefNode中,并且只保留LinkedMatrix中的固定数据.这与确保我以最少的网络活动保持干净的信念更新有关.这意味着我的BeliefNode存储:
LinkMatrix可以使用许多不同的算法构建,具体取决于节点之间关系的性质.您描述的所有模型都只是您使用的不同类.可能最简单的事情是默认为or-gate,然后如果节点之间有特殊关系,则选择其他方式来处理LinkMatrix.
我使用MongoDB进行持久化和缓存.我在一个事件模型中访问这些数据以获得速度和异步访问.这使得网络具有相当的性能,同时还有机会在需要时非常大.此外,由于我以这种方式使用Mongo,我可以轻松地为同一知识库创建新的上下文.因此,例如,如果我有诊断树,诊断的一些诊断支持将来自患者的症状和测试.我所做的是为该患者创建一个背景,然后根据该特定患者的证据传播我的信念.同样,如果医生说患者可能正在经历两种或更多种疾病,那么我可以改变我的一些链接矩阵以不同方式传播信念更新.
如果您不想在系统中使用Mongo之类的东西,但是您计划让多个消费者在知识库上工作,那么您需要采用某种缓存系统来确保您正在进行新的工作.最新的节点.
我的工作是开源的,所以如果你愿意,你可以跟进.这都是Ruby,所以它类似于你的Python,但不一定是替代品.我喜欢我的设计的一件事是人类解释结果所需的所有信息都可以在节点本身找到,而不是在代码中找到.这可以在定性描述中或在网络结构中完成.
所以,以下是我对您的设计的一些重要区别:
一个重要的警告:我正在谈论的一些内容尚未发布.我在谈论我正在谈论的东西,直到今天凌晨2点左右,所以这绝对是当前的,并且肯定会得到我的定期关注,但目前还没有公众可用.由于这是我的热情,如果您愿意,我很乐意回答任何问题或共同完成一个项目.
{kind=link}