我怎么知道Spark联接是有效的共分区输入联接?
Cam*_*lon 2 mapreduce apache-spark pyspark
我试图通过利用一些分区策略来优化一段PySpark代码,特别是对两个RDDS进行共分区,合并它们并在它们上调用reduce操作(这比这更复杂,但这是一个很好的初始模型) 。
查看以下图表:

(来源:reactivesoftware.pl)
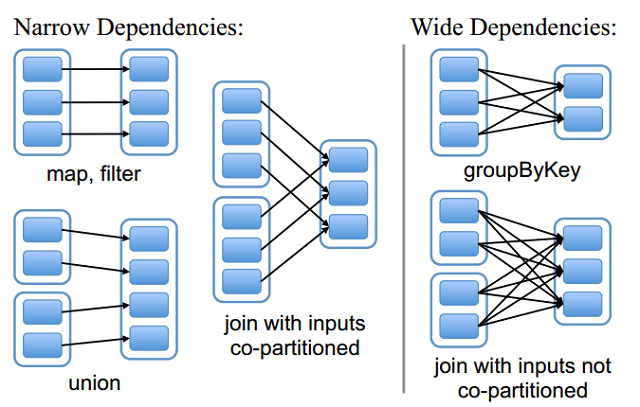{kind=link}
联合分区连接非常高效且紧凑。我的问题是,我怎么知道我的加入/减少是正确的共同分区?我应该在Spark应用程序用户界面上看到哪些统计信息?我应该看到哪些性能改进?
当数据在Spark中未正确地进行共分区时,系统必须执行随机播放(即,将数据移至新的临时分区以创建必要的联接以执行转换)。
因此,两者之间的主要区别在于混洗读取和写入时间的数量,即,对于狭窄的依存关系,您应该看到最小的读取次数和零写入,而对于广泛的依存关系,您将看到显着的随机写入。您可以在Spark UI的阶段详细信息中查看随机读取和写入统计信息。
从消除广泛的依赖关系中,您确实看到了两个性能提升:
- 随机播放本身会占用大量的IO和网络资源。
- 由于具有广泛的依赖关系链,洗牌操作通常是下游其他操作的瓶颈。
需要澄清的一点是:reduce操作始终会随机进行整理以聚集数据,因此分区策略仅适用于联接。
| 归档时间: |
|
| 查看次数: |
547 次 |
| 最近记录: |